LLMs Meet Long Video: Advancing Long Video Question Answering with An Interactive Visual Adapter in LLMs

0
Sign in to get full access
Overview
- This paper introduces a new approach to improve long video comprehension using large language models (LLMs).
- The key idea is an "interactive visual adapter" that allows LLMs to better understand and reason about long videos.
- The authors conducted experiments to evaluate their approach on various long video understanding tasks.
Plain English Explanation
LLMs Meet Long Video: Advancing Long Video Comprehension with An Interactive Visual Adapter in LLMs
Large language models (LLMs) have made impressive advancements in understanding and generating human language. However, applying these models to long videos, which contain much more information than typical text, has proven challenging.
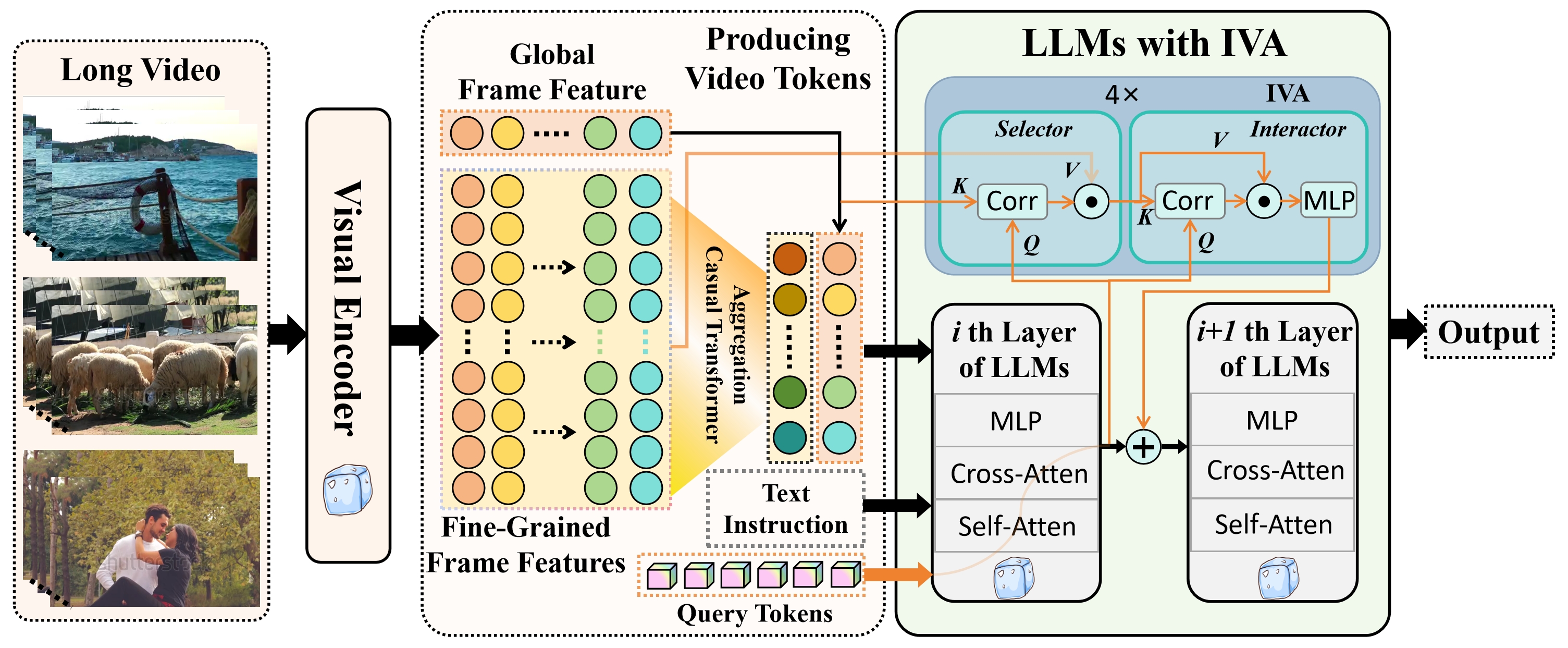
The researchers in this paper developed a new technique called an "interactive visual adapter" to help LLMs better comprehend long videos. The adapter allows the LLM to interactively attend to and reason about the visual information in the video, rather than just processing the video as a static input.
By incorporating this interactive visual adapter, the LLM can gain a deeper understanding of the events, objects, and relationships depicted in the long video. The authors evaluated their approach on several long video understanding tasks and found significant performance improvements compared to previous methods.
Technical Explanation
The key component of the researchers' approach is the interactive visual adapter, which is integrated with a large language model. This adapter allows the LLM to dynamically attend to and reason about the visual information in the video as it processes the language.
Specifically, the adapter takes the video frames as input and generates visual embeddings that capture the semantics of the visual content. These embeddings are then combined with the language embeddings produced by the LLM, enabling the model to jointly reason about the visual and textual information.
The authors also introduce several techniques to make the adapter more effective, such as using a hierarchical attention mechanism to focus on salient visual regions and incorporating contrastive learning to improve the visual embedding quality.
Critical Analysis
The paper builds upon previous research on using LLMs for video understanding, but it addresses some of the key limitations of these prior approaches. For example, many existing methods simply treat the video as a static input, without allowing the LLM to dynamically interact with the visual information.
One potential concern is the computational complexity of the interactive visual adapter, which could make it challenging to deploy in real-world applications. The authors acknowledge this issue and suggest several optimization strategies to improve the efficiency of their approach.
Additionally, the evaluation in the paper is focused on specific long video understanding tasks, and it would be valuable to see how the interactive visual adapter performs on a wider range of applications, such as video question answering or video captioning.
Conclusion
This paper presents a novel approach to enhancing long video comprehension using large language models. By incorporating an interactive visual adapter, the LLM can more effectively attend to and reason about the visual information in long videos, leading to significant performance improvements on various understanding tasks.
The researchers' work represents an important step towards bridging the gap between the impressive language understanding capabilities of LLMs and the challenges of processing long, complex video data. As LLMs continue to advance, techniques like the interactive visual adapter will likely play a crucial role in enabling these models to tackle increasingly complex multimodal tasks and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMs Meet Long Video: Advancing Long Video Question Answering with An Interactive Visual Adapter in LLMs
Yunxin Li, Xinyu Chen, Baotain Hu, Min Zhang
Long video understanding is a significant and ongoing challenge in the intersection of multimedia and artificial intelligence. Employing large language models (LLMs) for comprehending video becomes an emerging and promising method. However, this approach incurs high computational costs due to the extensive array of video tokens, experiences reduced visual clarity as a consequence of token aggregation, and confronts challenges arising from irrelevant visual tokens while answering video-related questions. To alleviate these issues, we present an Interactive Visual Adapter (IVA) within LLMs, designed to enhance interaction with fine-grained visual elements. Specifically, we first transform long videos into temporal video tokens via leveraging a visual encoder alongside a pretrained causal transformer, then feed them into LLMs with the video instructions. Subsequently, we integrated IVA, which contains a lightweight temporal frame selector and a spatial feature interactor, within the internal blocks of LLMs to capture instruction-aware and fine-grained visual signals. Consequently, the proposed video-LLM facilitates a comprehensive understanding of long video content through appropriate long video modeling and precise visual interactions. We conducted extensive experiments on nine video understanding benchmarks and experimental results show that our interactive visual adapter significantly improves the performance of video LLMs on long video QA tasks. Ablation studies further verify the effectiveness of IVA in understanding long and short video.
Read more8/27/2024
0
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
Empowered by Large Language Models (LLMs), recent advancements in Video-based LLMs (VideoLLMs) have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a simple yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples show that our model produces more precise responses for long video understanding. Code is available at https://github.com/ziplab/LongVLM.
Read more7/23/2024

0
Streaming Long Video Understanding with Large Language Models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, Jiaqi Wang
This paper presents VideoStreaming, an advanced vision-language large model (VLLM) for video understanding, that capably understands arbitrary-length video with a constant number of video tokens streamingly encoded and adaptively selected. The challenge of video understanding in the vision language area mainly lies in the significant computational burden caused by the great number of tokens extracted from long videos. Previous works rely on sparse sampling or frame compression to reduce tokens. However, such approaches either disregard temporal information in a long time span or sacrifice spatial details, resulting in flawed compression. To address these limitations, our VideoStreaming has two core designs: Memory-Propagated Streaming Encoding and Adaptive Memory Selection. The Memory-Propagated Streaming Encoding architecture segments long videos into short clips and sequentially encodes each clip with a propagated memory. In each iteration, we utilize the encoded results of the preceding clip as historical memory, which is integrated with the current clip to distill a condensed representation that encapsulates the video content up to the current timestamp. After the encoding process, the Adaptive Memory Selection strategy selects a constant number of question-related memories from all the historical memories and feeds them into the LLM to generate informative responses. The question-related selection reduces redundancy within the memories, enabling efficient and precise video understanding. Meanwhile, the disentangled video extraction and reasoning design allows the LLM to answer different questions about a video by directly selecting corresponding memories, without the need to encode the whole video for each question. Our model achieves superior performance and higher efficiency on long video benchmarks, showcasing precise temporal comprehension for detailed question answering.
Read more5/28/2024

0
Video Understanding with Large Language Models: A Survey
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, Ali Vosoughi, Chao Huang, Zeliang Zhang, Pinxin Liu, Mingqian Feng, Feng Zheng, Jianguo Zhang, Ping Luo, Jiebo Luo, Chenliang Xu
With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of large language models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of recent advancements in video understanding that harness the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended multi-granularity (general, temporal, and spatiotemporal) reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into three main types: Video Analyzer x LLM, Video Embedder x LLM, and (Analyzer + Embedder) x LLM. Furthermore, we identify five sub-types based on the functions of LLMs in Vid-LLMs: LLM as Summarizer, LLM as Manager, LLM as Text Decoder, LLM as Regressor, and LLM as Hidden Layer. Furthermore, this survey presents a comprehensive study of the tasks, datasets, benchmarks, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding.
Read more7/25/2024