LongVLM: Efficient Long Video Understanding via Large Language Models
2404.03384
0
0
Abstract
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces LongVLM, a novel approach for efficient long video understanding using large language models.
- LongVLM aims to leverage the power of large language models to understand and summarize long, complex video content.
- The key idea is to combine large language models with specialized video processing modules to capture both the semantic and temporal aspects of long videos.
Plain English Explanation
LongVLM is a new technique that uses large language models to better understand and summarize long videos. Traditional video processing methods can struggle with lengthy, complex videos, but LongVLM tries to overcome this by tapping into the impressive language understanding capabilities of large language models.
The core innovation is integrating these powerful language models with specialized video processing modules. This allows LongVLM to capture both the overall meaning and the temporal flow of long video content. For example, it could watch a 30-minute documentary and summarize the key points and narrative in a concise way.
By combining the strengths of language models and video processing, LongVLM aims to make it easier and more efficient to understand and extract insights from lengthy, information-rich videos. This could have applications in areas like video summarization, multimedia question answering, and long-form video analysis.
Technical Explanation
The key innovation in LongVLM is its architecture, which integrates a large language model with specialized video processing components. The language model is responsible for understanding the semantic content and high-level narrative of the video, while the video modules capture the temporal dynamics and visual features.
Specifically, LongVLM consists of three main components:
- Video Encoder: This module processes the raw video frames to extract visual and temporal features.
- Language Model: A large, pre-trained language model, such as GPT-3, is used to understand the semantic content and overall narrative of the video.
- Fusion Module: This component combines the outputs of the video encoder and language model to produce a unified representation of the video.
The authors train LongVLM in an end-to-end fashion on a large dataset of long video content. During inference, LongVLM can accept a new video as input and generate a concise summary, answer questions about the video's content, or perform other downstream tasks.
The key advantage of LongVLM is its ability to efficiently process and understand lengthy, complex video data by leveraging the strengths of large language models. This contrasts with traditional video processing approaches that may struggle with long-form content.
Critical Analysis
The authors provide a comprehensive evaluation of LongVLM, demonstrating its effectiveness on several long video understanding tasks. However, the paper does acknowledge some potential limitations:
- The performance of LongVLM is still dependent on the quality and coverage of the training data, which may be challenging to obtain for certain domains or use cases.
- The computational and memory requirements of LongVLM may be higher than some simpler video processing techniques, particularly for very long videos.
- The paper does not explore the interpretability or explainability of LongVLM's decision-making, which could be an important consideration for certain applications.
Additionally, it would be interesting to see further research on the generalization capabilities of LongVLM, such as its ability to handle novel video domains or types of content beyond what was included in the training data.
Conclusion
The LongVLM approach represents an exciting advancement in long video understanding by leveraging the power of large language models. By combining semantic understanding and temporal processing, LongVLM can efficiently summarize, analyze, and extract insights from complex, long-form video content.
This work has the potential to enable more effective video summarization, question answering, and other video-based applications, particularly for domains with extensive, information-rich video data. As large language models continue to advance, further research and development of techniques like LongVLM could lead to significant improvements in our ability to make sense of the growing volume of video content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
0
0
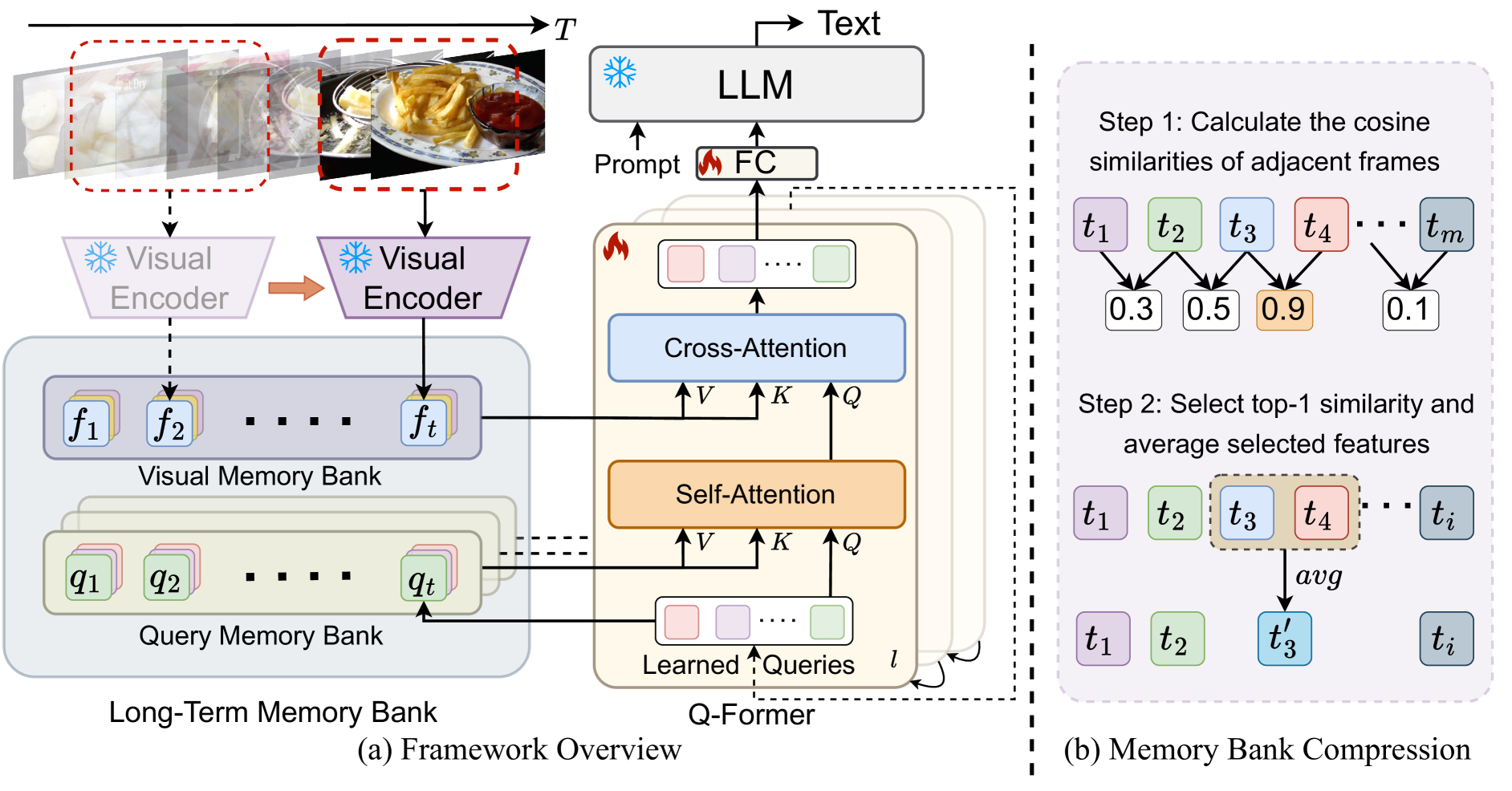
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
4/9/2024
Koala: Key frame-conditioned long video-LLM
Reuben Tan, Ximeng Sun, Ping Hu, Jui-hsien Wang, Hanieh Deilamsalehy, Bryan A. Plummer, Bryan Russell, Kate Saenko
0
0
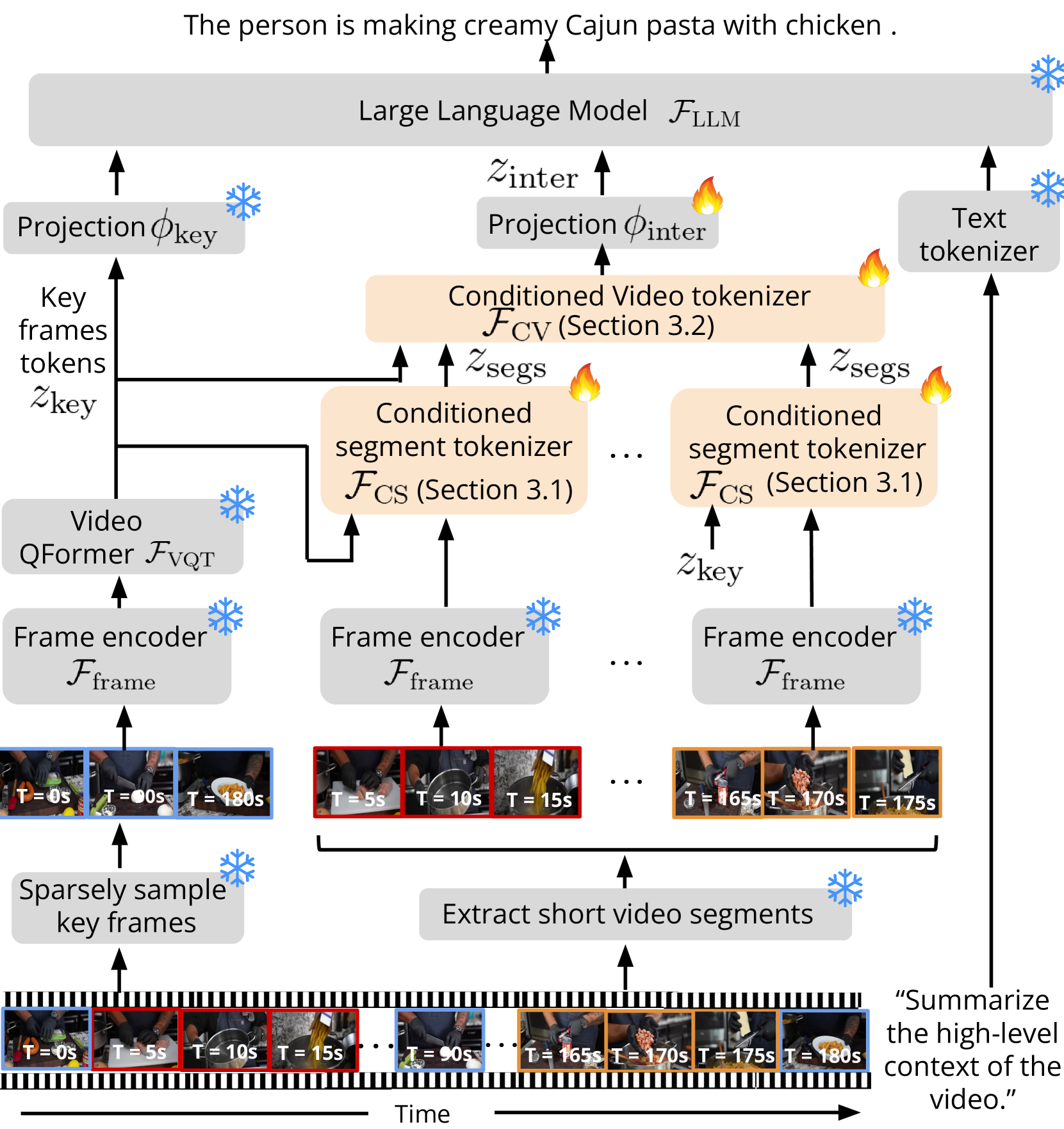
Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
5/7/2024
💬
VidCoM: Fast Video Comprehension through Large Language Models with Multimodal Tools
Ji Qi, Kaixuan Ji, Jifan Yu, Duokang Wang, Bin Xu, Lei Hou, Juanzi Li
0
0
Building models that comprehends videos and responds specific user instructions is a practical and challenging topic, as it requires mastery of both vision understanding and knowledge reasoning. Compared to language and image modalities, training efficiency remains a serious problem as existing studies train models on massive sparse videos paired with brief descriptions. In this paper, we introduce textbf{VidCoM}, a fast adaptive framework that leverages Large Language Models (LLMs) to reason about videos using lightweight visual tools. Specifically, we reveal that the key to responding to specific instructions is focusing on relevant video events, and utilize two visual tools, structured scene graph generation and descriptive image caption generation, to gather and represent the event information. Thus, a LLM enriched with world knowledge is adopted as the reasoning agent to achieve the responses by performing multiple reasoning steps on specific video events. To address the difficulty of LLMs identifying video events, we further propose an Instruction-oriented Video Events Recognition (InsOVER) algorithm. This algorithm locates the corresponding video events based on an efficient Hungarian matching between decompositions of linguistic instructions and video events, thereby enabling LLMs to interact effectively with extended videos. Extensive experiments on two typical video comprehension tasks show that the proposed tuning-free framework outperforms the pre-trained models including Flamingo-80B, to achieve the state-of-the-art performance. Our source code and system will be publicly available.
4/30/2024
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
0
0
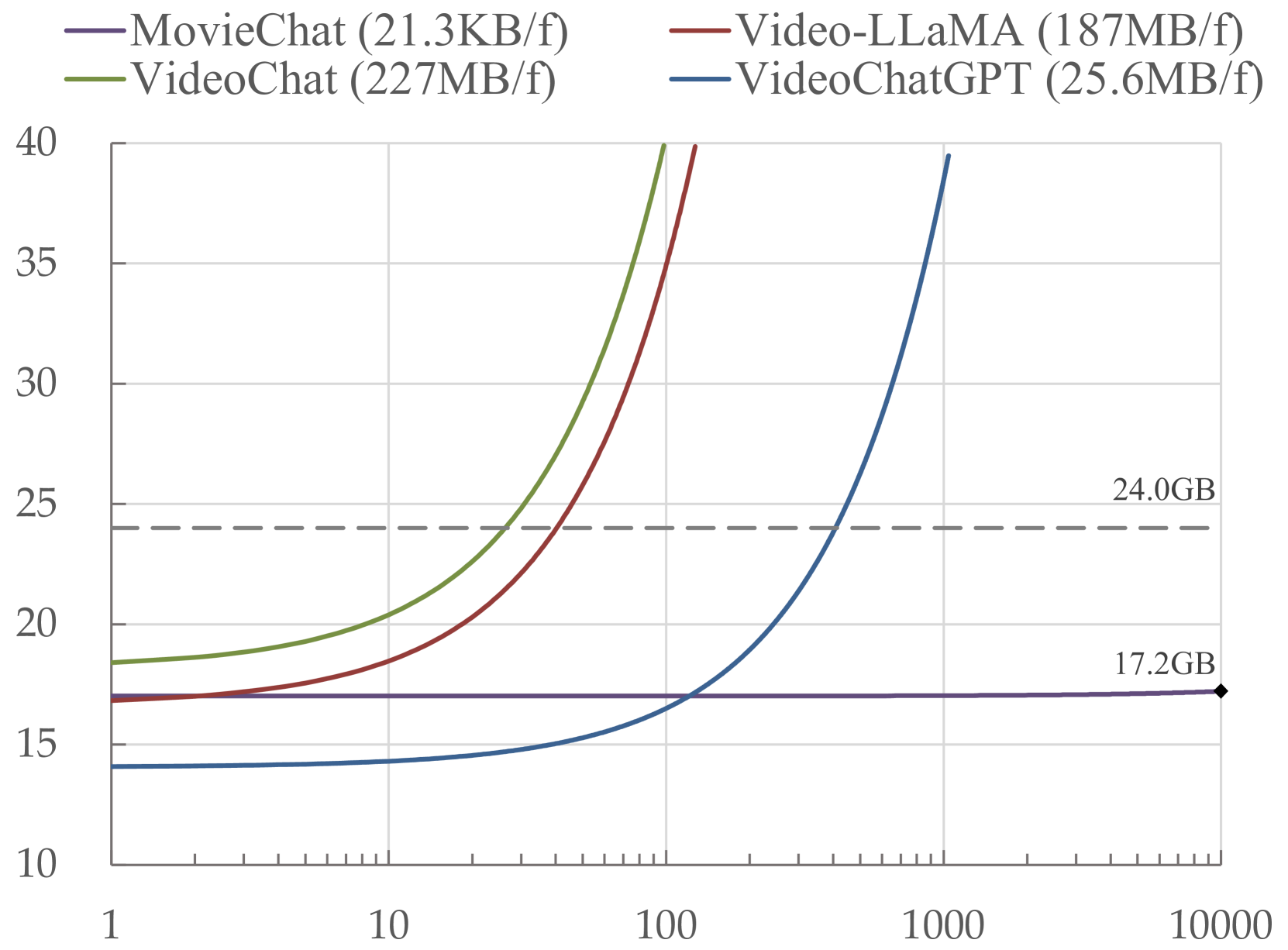
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
4/29/2024