LLMs in Web-Development: Evaluating LLM-Generated PHP code unveiling vulnerabilities and limitations
2404.14459
0
0
🧪
Abstract
This research carries out a comprehensive examination of web application code security, when generated by Large Language Models through analyzing a dataset comprising 2,500 small dynamic PHP websites. These AI-generated sites are scanned for security vulnerabilities after being deployed as standalone websites in Docker containers. The evaluation of the websites was conducted using a hybrid methodology, incorporating the Burp Suite active scanner, static analysis, and manual checks. Our investigation zeroes in on identifying and analyzing File Upload, SQL Injection, Stored XSS, and Reflected XSS. This approach not only underscores the potential security flaws within AI-generated PHP code but also provides a critical perspective on the reliability and security implications of deploying such code in real-world scenarios. Our evaluation confirms that 27% of the programs generated by GPT-4 verifiably contains vulnerabilities in the PHP code, where this number -- based on static scanning and manual verification -- is potentially much higher. This poses a substantial risks to software safety and security. In an effort to contribute to the research community and foster further analysis, we have made the source codes publicly available, alongside a record enumerating the detected vulnerabilities for each sample. This study not only sheds light on the security aspects of AI-generated code but also underscores the critical need for rigorous testing and evaluation of such technologies for software development.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research examines the security of web applications generated by Large Language Models (LLMs) like GPT-4.
- The researchers analyzed a dataset of 2,500 small PHP websites created by AI models, scanning them for common vulnerabilities.
- The evaluation used a hybrid methodology, including active scanning, static analysis, and manual checks.
- The study focused on identifying and analyzing File Upload, SQL Injection, Stored XSS, and Reflected XSS vulnerabilities.
- The findings highlight the potential security risks of AI-generated code and the need for rigorous testing before deployment.
Plain English Explanation
The researchers wanted to understand how secure the code produced by AI models like GPT-4 is when used to build web applications. They looked at a large set of 2,500 small PHP websites that were created by AI, and scanned them for common security problems.
To do this, they used a mix of different techniques: an active scanner to find vulnerabilities, static analysis to examine the code, and manual checks by experts. They focused on four key types of security issues: file upload flaws, SQL injection, stored cross-site scripting (XSS), and reflected XSS.
The results showed that 27% of the websites had verifiable vulnerabilities in the PHP code generated by the AI. However, the researchers think the actual number could be even higher based on their analysis. This is a significant risk, as insecure code can lead to serious problems like data breaches or system compromises.
To help the research community, the researchers have made the source code and vulnerability details public. This will allow others to further study the security of AI-generated code and work on improving it.
Overall, the study highlights the critical need to thoroughly test and evaluate AI systems used for software development, to ensure the resulting code is secure and safe to deploy. This is an important step as AI becomes more widely used in creating real-world applications.
Technical Explanation
The research team conducted a comprehensive analysis of the security of web applications generated by Large Language Models (LLMs), using a dataset of 2,500 small dynamic PHP websites created by AI models. After deploying these AI-generated sites as standalone websites in Docker containers, the researchers evaluated them using a hybrid methodology.
This hybrid approach incorporated the use of the Burp Suite active scanner, static code analysis, and manual verification checks. The evaluation focused on identifying and analyzing four key vulnerability types: File Upload, SQL Injection, Stored Cross-Site Scripting (XSS), and Reflected XSS.
The findings of the study indicate that 27% of the AI-generated PHP programs contained verifiable vulnerabilities. However, the researchers believe the actual number of vulnerable programs could be much higher, based on their static analysis and manual verification processes.
To contribute to further research in this area, the researchers have made the source code and a detailed vulnerability enumeration for each sample publicly available. This dataset can be used by the research community to continue investigating the security implications of AI-generated code and develop strategies to improve its reliability and safety.
Critical Analysis
The researchers have highlighted an important issue in the security of AI-generated code, which is a critical concern as AI becomes more widely adopted for software development. The comprehensive and multi-pronged approach used in the evaluation provides a robust assessment of the potential vulnerabilities in these AI-generated web applications.
However, it is important to note that the study was limited to a relatively small dataset of 2,500 PHP websites. While this provides valuable insights, the findings may not be fully representative of the broader landscape of AI-generated code across different programming languages and application types. Further research with larger and more diverse datasets would be beneficial to validate the conclusions and identify any potential patterns or variations.
Additionally, the study does not delve into the specific mechanisms or root causes behind the vulnerabilities found in the AI-generated code. Understanding the underlying factors that contribute to these security issues would be valuable for developing effective mitigation strategies and improving the security of AI-generated software.
Lastly, the researchers acknowledge the need for rigorous testing and evaluation of AI systems used for software development, but do not provide detailed recommendations or guidelines on how this can be effectively implemented. Exploring best practices and frameworks for the secure deployment of AI-generated code would be a valuable contribution to the field.
Conclusion
This research highlights the significant security risks associated with web applications generated by Large Language Models. The study's comprehensive evaluation of a dataset of 2,500 AI-created PHP websites reveals that a substantial portion (27%) contains verifiable vulnerabilities, with the potential for an even higher number of security issues.
These findings underscore the critical need for thorough testing and evaluation of AI-generated code before deployment in real-world scenarios. As AI becomes increasingly integrated into software development processes, ensuring the security and reliability of the resulting applications is paramount to protect users and organizations from potential data breaches, system compromises, and other cyber threats.
By making the source code and vulnerability details publicly available, the researchers have provided a valuable resource for the research community to further investigate the security implications of AI-generated code and develop strategies to address these challenges. Continued efforts in this direction will be essential for realizing the full potential of AI in software development while prioritizing the safety and security of the end products.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
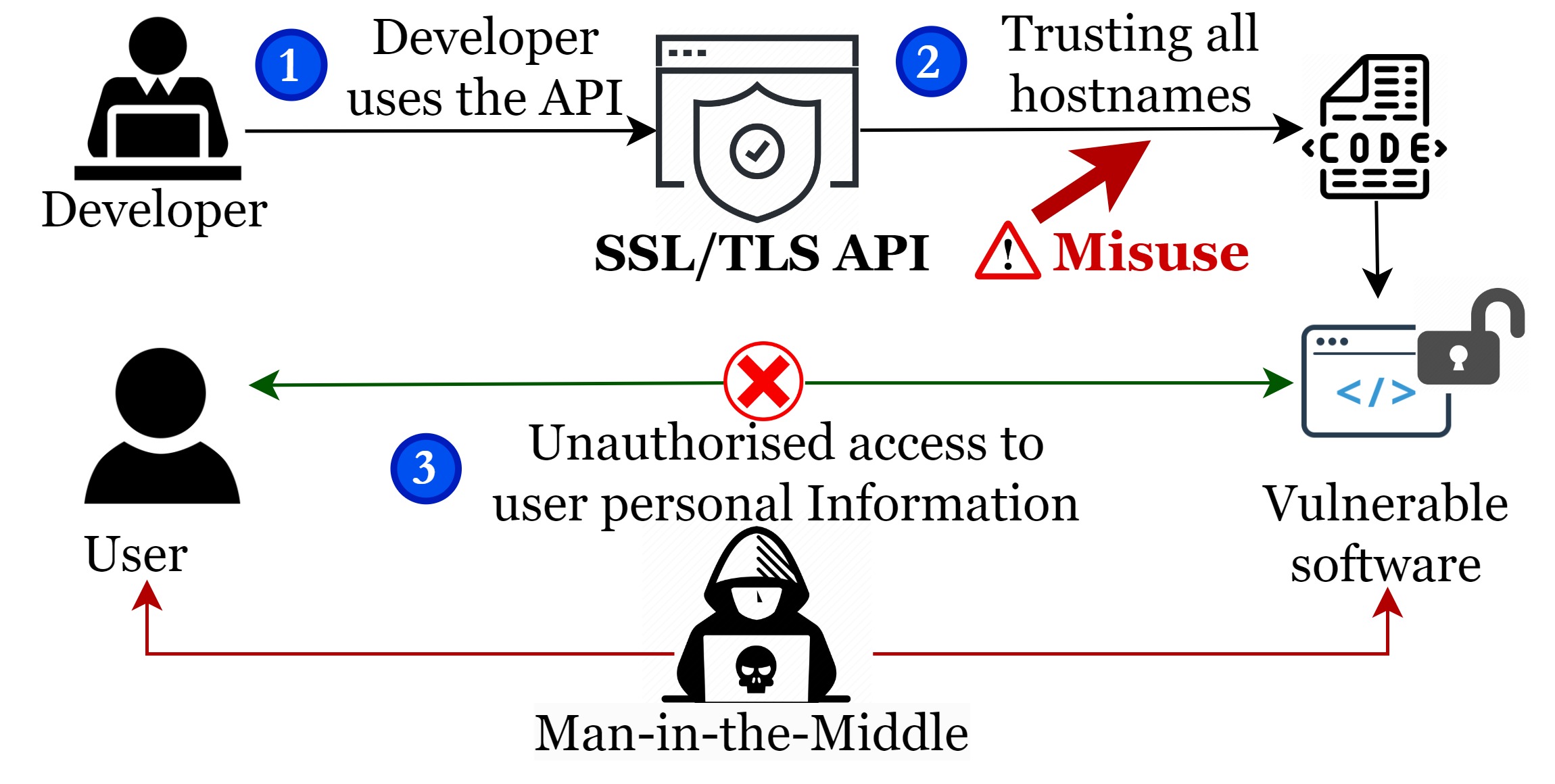
An Investigation into Misuse of Java Security APIs by Large Language Models
Zahra Mousavi, Chadni Islam, Kristen Moore, Alsharif Abuadbba, Muhammad Ali Babar
0
0
The increasing trend of using Large Language Models (LLMs) for code generation raises the question of their capability to generate trustworthy code. While many researchers are exploring the utility of code generation for uncovering software vulnerabilities, one crucial but often overlooked aspect is the security Application Programming Interfaces (APIs). APIs play an integral role in upholding software security, yet effectively integrating security APIs presents substantial challenges. This leads to inadvertent misuse by developers, thereby exposing software to vulnerabilities. To overcome these challenges, developers may seek assistance from LLMs. In this paper, we systematically assess ChatGPT's trustworthiness in code generation for security API use cases in Java. To conduct a thorough evaluation, we compile an extensive collection of 48 programming tasks for 5 widely used security APIs. We employ both automated and manual approaches to effectively detect security API misuse in the code generated by ChatGPT for these tasks. Our findings are concerning: around 70% of the code instances across 30 attempts per task contain security API misuse, with 20 distinct misuse types identified. Moreover, for roughly half of the tasks, this rate reaches 100%, indicating that there is a long way to go before developers can rely on ChatGPT to securely implement security API code.
4/8/2024
💬
Automatic Programming: Large Language Models and Beyond
Michael R. Lyu, Baishakhi Ray, Abhik Roychoudhury, Shin Hwei Tan, Patanamon Thongtanunam
0
0
Automatic programming has seen increasing popularity due to the emergence of tools like GitHub Copilot which rely on Large Language Models (LLMs). At the same time, automatically generated code faces challenges during deployment due to concerns around quality and trust. In this article, we study automated coding in a general sense and study the concerns around code quality, security and related issues of programmer responsibility. These are key issues for organizations while deciding on the usage of automatically generated code. We discuss how advances in software engineering such as program repair and analysis can enable automatic programming. We conclude with a forward looking view, focusing on the programming environment of the near future, where programmers may need to switch to different roles to fully utilize the power of automatic programming. Automated repair of automatically generated programs from LLMs, can help produce higher assurance code from LLMs, along with evidence of assurance
5/16/2024
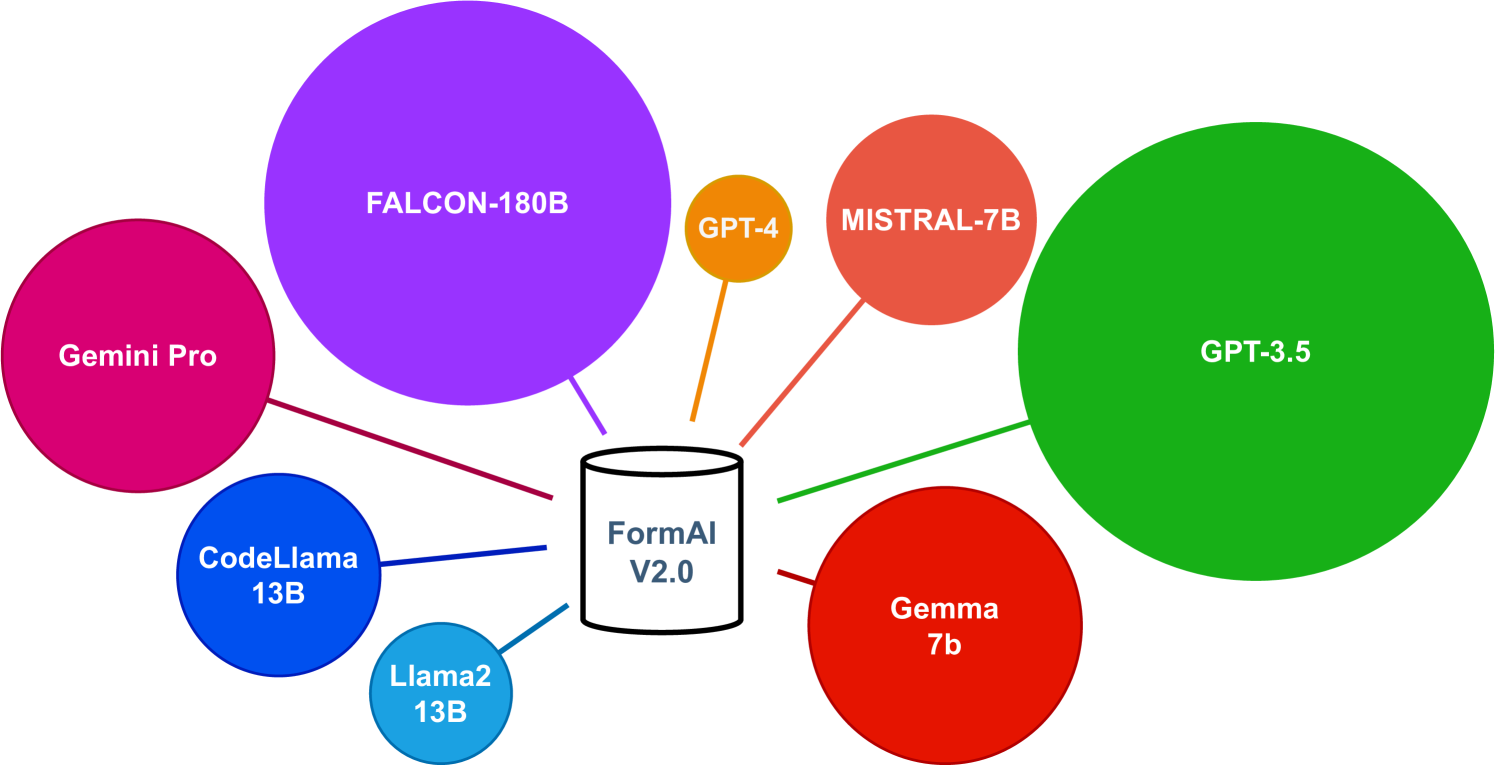
Do Neutral Prompts Produce Insecure Code? FormAI-v2 Dataset: Labelling Vulnerabilities in Code Generated by Large Language Models
Norbert Tihanyi, Tamas Bisztray, Mohamed Amine Ferrag, Ridhi Jain, Lucas C. Cordeiro
0
0
This study provides a comparative analysis of state-of-the-art large language models (LLMs), analyzing how likely they generate vulnerabilities when writing simple C programs using a neutral zero-shot prompt. We address a significant gap in the literature concerning the security properties of code produced by these models without specific directives. N. Tihanyi et al. introduced the FormAI dataset at PROMISE '23, containing 112,000 GPT-3.5-generated C programs, with over 51.24% identified as vulnerable. We expand that work by introducing the FormAI-v2 dataset comprising 265,000 compilable C programs generated using various LLMs, including robust models such as Google's GEMINI-pro, OpenAI's GPT-4, and TII's 180 billion-parameter Falcon, to Meta's specialized 13 billion-parameter CodeLLama2 and various other compact models. Each program in the dataset is labelled based on the vulnerabilities detected in its source code through formal verification using the Efficient SMT-based Context-Bounded Model Checker (ESBMC). This technique eliminates false positives by delivering a counterexample and ensures the exclusion of false negatives by completing the verification process. Our study reveals that at least 63.47% of the generated programs are vulnerable. The differences between the models are minor, as they all display similar coding errors with slight variations. Our research highlights that while LLMs offer promising capabilities for code generation, deploying their output in a production environment requires risk assessment and validation.
4/30/2024
💬
Attacks on Third-Party APIs of Large Language Models
Wanru Zhao, Vidit Khazanchi, Haodi Xing, Xuanli He, Qiongkai Xu, Nicholas Donald Lane
0
0
Large language model (LLM) services have recently begun offering a plugin ecosystem to interact with third-party API services. This innovation enhances the capabilities of LLMs, but it also introduces risks, as these plugins developed by various third parties cannot be easily trusted. This paper proposes a new attacking framework to examine security and safety vulnerabilities within LLM platforms that incorporate third-party services. Applying our framework specifically to widely used LLMs, we identify real-world malicious attacks across various domains on third-party APIs that can imperceptibly modify LLM outputs. The paper discusses the unique challenges posed by third-party API integration and offers strategic possibilities to improve the security and safety of LLM ecosystems moving forward. Our code is released at https://github.com/vk0812/Third-Party-Attacks-on-LLMs.
4/29/2024