LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM

0
Sign in to get full access
Overview
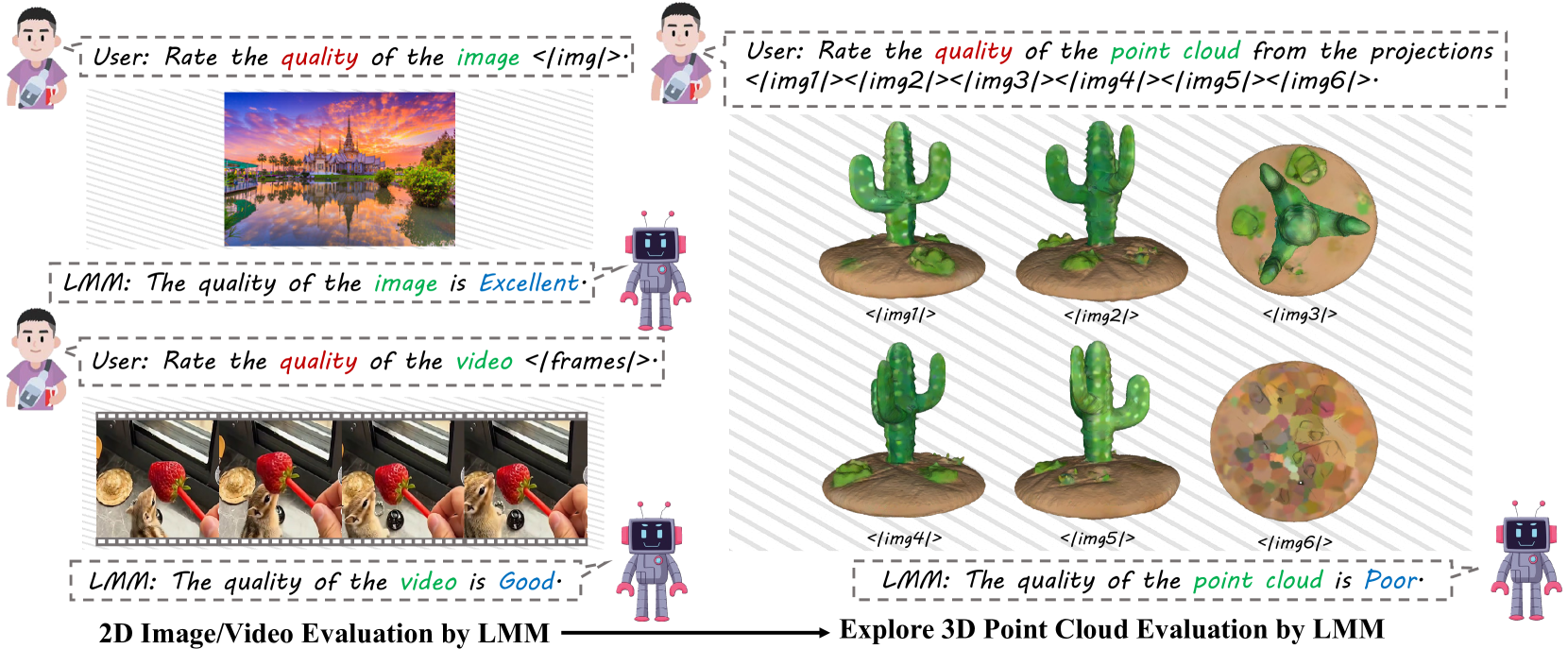
- This paper introduces LMM-PCQA, a system that uses large multi-modal models (LMMs) to assist in the assessment of point cloud quality.
- Point clouds are 3D representations of objects or environments that are widely used in applications like virtual reality, autonomous vehicles, and 3D scanning.
- Accurately assessing the quality of point clouds is crucial, as poor quality can negatively impact downstream applications.
- LMM-PCQA leverages the powerful multimodal capabilities of LMMs to provide more accurate and reliable point cloud quality assessment compared to existing approaches.
Plain English Explanation
LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM is a system that uses large, advanced AI models to help evaluate the quality of 3D point cloud data. Point clouds are digital representations of real-world objects or environments, created by techniques like 3D scanning. They are used in many cutting-edge technologies, like virtual reality, self-driving cars, and 3D printing.
Accurately judging the quality of point clouds is very important, because poor quality data can cause problems for the applications that rely on it. The researchers behind LMM-PCQA have found a way to leverage the impressive capabilities of large, multimodal AI models to provide better point cloud quality assessments than previous methods.
Multimodal models are AIs that can understand and process different types of data, like text, images, and 3D structures. By using these powerful models, LMM-PCQA can more reliably evaluate point clouds and identify any issues or flaws. This helps ensure that the 3D data being used in critical applications is of high enough quality to work effectively.
Technical Explanation
LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM proposes a system that leverages large multimodal models (LMMs) to assist in the task of point cloud quality assessment (PCQA). Point clouds are 3D representations of objects or environments that are widely used in applications such as virtual reality, autonomous vehicles, and 3D scanning.
The key innovation of LMM-PCQA is its use of LMMs, which are powerful AI models capable of processing and understanding diverse data modalities, including text, images, and 3D structures. By harnessing the multimodal capabilities of LMMs, the system is able to provide more accurate and reliable PCQA compared to existing approaches.
The authors conduct experiments on standard PCQA benchmarks and demonstrate that LMM-PCQA outperforms state-of-the-art PCQA models. The system's superior performance is attributed to its ability to effectively leverage the rich multimodal representations learned by LMMs, which allow it to better capture the complex relationships between point cloud characteristics and quality.
Critical Analysis
The paper presents a promising approach to leveraging large multimodal models for point cloud quality assessment. However, it is worth noting some potential limitations and areas for further research:
-
Dataset Bias: The performance of LMM-PCQA may be influenced by biases present in the training datasets used for the LMMs. It would be important to evaluate the system's robustness to diverse point cloud data, including those from different domains or with different characteristics.
-
Interpretability: As with many complex AI systems, the inner workings of LMM-PCQA may not be easily interpretable. Providing more insights into how the system arrives at its quality assessments could help build trust and facilitate further development.
-
Real-World Deployment: The paper focuses on evaluating LMM-PCQA on standard benchmarks. Practical deployment in real-world applications may introduce additional challenges, such as computational efficiency, integration with existing pipelines, and user experience considerations.
-
Ethical Considerations: The use of powerful AI models in critical applications like point cloud quality assessment raises important ethical questions, such as ensuring fairness, transparency, and accountability. These aspects should be carefully considered as the technology progresses.
Despite these potential limitations, the promising results presented in the paper suggest that the use of large multimodal models for point cloud quality assessment is a valuable research direction that warrants further exploration.
Conclusion
LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM introduces a novel approach to point cloud quality assessment that leverages the capabilities of large multimodal models. By harnessing the rich multimodal representations learned by these powerful AI systems, the LMM-PCQA system is able to provide more accurate and reliable quality assessments compared to existing methods.
The successful application of LMMs to this task highlights the potential of multimodal learning to address complex challenges in various domains, including 3D data processing and computer vision. As point clouds become increasingly important in emerging technologies, tools like LMM-PCQA will play a crucial role in ensuring the quality and integrity of these 3D representations, with far-reaching implications for applications ranging from virtual reality to autonomous navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM
Zicheng Zhang, Haoning Wu, Yingjie Zhou, Chunyi Li, Wei Sun, Chaofeng Chen, Xiongkuo Min, Xiaohong Liu, Weisi Lin, Guangtao Zhai
Although large multi-modality models (LMMs) have seen extensive exploration and application in various quality assessment studies, their integration into Point Cloud Quality Assessment (PCQA) remains unexplored. Given LMMs' exceptional performance and robustness in low-level vision and quality assessment tasks, this study aims to investigate the feasibility of imparting PCQA knowledge to LMMs through text supervision. To achieve this, we transform quality labels into textual descriptions during the fine-tuning phase, enabling LMMs to derive quality rating logits from 2D projections of point clouds. To compensate for the loss of perception in the 3D domain, structural features are extracted as well. These quality logits and structural features are then combined and regressed into quality scores. Our experimental results affirm the effectiveness of our approach, showcasing a novel integration of LMMs into PCQA that enhances model understanding and assessment accuracy. We hope our contributions can inspire subsequent investigations into the fusion of LMMs with PCQA, fostering advancements in 3D visual quality analysis and beyond. The code is available at https://github.com/zzc-1998/LMM-PCQA.
Read more8/7/2024

0
LMM-VQA: Advancing Video Quality Assessment with Large Multimodal Models
Qihang Ge, Wei Sun, Yu Zhang, Yunhao Li, Zhongpeng Ji, Fengyu Sun, Shangling Jui, Xiongkuo Min, Guangtao Zhai
The explosive growth of videos on streaming media platforms has underscored the urgent need for effective video quality assessment (VQA) algorithms to monitor and perceptually optimize the quality of streaming videos. However, VQA remains an extremely challenging task due to the diverse video content and the complex spatial and temporal distortions, thus necessitating more advanced methods to address these issues. Nowadays, large multimodal models (LMMs), such as GPT-4V, have exhibited strong capabilities for various visual understanding tasks, motivating us to leverage the powerful multimodal representation ability of LMMs to solve the VQA task. Therefore, we propose the first Large Multi-Modal Video Quality Assessment (LMM-VQA) model, which introduces a novel spatiotemporal visual modeling strategy for quality-aware feature extraction. Specifically, we first reformulate the quality regression problem into a question and answering (Q&A) task and construct Q&A prompts for VQA instruction tuning. Then, we design a spatiotemporal vision encoder to extract spatial and temporal features to represent the quality characteristics of videos, which are subsequently mapped into the language space by the spatiotemporal projector for modality alignment. Finally, the aligned visual tokens and the quality-inquired text tokens are aggregated as inputs for the large language model (LLM) to generate the quality score and level. Extensive experiments demonstrate that LMM-VQA achieves state-of-the-art performance across five VQA benchmarks, exhibiting an average improvement of $5%$ in generalization ability over existing methods. Furthermore, due to the advanced design of the spatiotemporal encoder and projector, LMM-VQA also performs exceptionally well on general video understanding tasks, further validating its effectiveness. Our code will be released at https://github.com/Sueqk/LMM-VQA.
Read more8/27/2024
💬
0
PointLLM: Empowering Large Language Models to Understand Point Clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, Dahua Lin
The unprecedented advancements in Large Language Models (LLMs) have shown a profound impact on natural language processing but are yet to fully embrace the realm of 3D understanding. This paper introduces PointLLM, a preliminary effort to fill this gap, enabling LLMs to understand point clouds and offering a new avenue beyond 2D visual data. PointLLM understands colored object point clouds with human instructions and generates contextually appropriate responses, illustrating its grasp of point clouds and common sense. Specifically, it leverages a point cloud encoder with a powerful LLM to effectively fuse geometric, appearance, and linguistic information. We collect a novel dataset comprising 660K simple and 70K complex point-text instruction pairs to enable a two-stage training strategy: aligning latent spaces and subsequently instruction-tuning the unified model. To rigorously evaluate the perceptual and generalization capabilities of PointLLM, we establish two benchmarks: Generative 3D Object Classification and 3D Object Captioning, assessed through three different methods, including human evaluation, GPT-4/ChatGPT evaluation, and traditional metrics. Experimental results reveal PointLLM's superior performance over existing 2D and 3D baselines, with a notable achievement in human-evaluated object captioning tasks where it surpasses human annotators in over 50% of the samples. Codes, datasets, and benchmarks are available at https://github.com/OpenRobotLab/PointLLM .
Read more9/10/2024

0
A Comprehensive Study of Multimodal Large Language Models for Image Quality Assessment
Tianhe Wu, Kede Ma, Jie Liang, Yujiu Yang, Lei Zhang
While Multimodal Large Language Models (MLLMs) have experienced significant advancement in visual understanding and reasoning, their potential to serve as powerful, flexible, interpretable, and text-driven models for Image Quality Assessment (IQA) remains largely unexplored. In this paper, we conduct a comprehensive and systematic study of prompting MLLMs for IQA. We first investigate nine prompting systems for MLLMs as the combinations of three standardized testing procedures in psychophysics (i.e., the single-stimulus, double-stimulus, and multiple-stimulus methods) and three popular prompting strategies in natural language processing (i.e., the standard, in-context, and chain-of-thought prompting). We then present a difficult sample selection procedure, taking into account sample diversity and uncertainty, to further challenge MLLMs equipped with the respective optimal prompting systems. We assess three open-source and one closed-source MLLMs on several visual attributes of image quality (e.g., structural and textural distortions, geometric transformations, and color differences) in both full-reference and no-reference scenarios. Experimental results show that only the closed-source GPT-4V provides a reasonable account for human perception of image quality, but is weak at discriminating fine-grained quality variations (e.g., color differences) and at comparing visual quality of multiple images, tasks humans can perform effortlessly.
Read more7/12/2024