A Comprehensive Study of Multimodal Large Language Models for Image Quality Assessment

0

Sign in to get full access
Overview
- This paper presents a comprehensive study of multimodal large language models (M-LLMs) for image quality assessment (IQA).
- M-LLMs are an emerging class of AI models that can understand and generate both text and images, leveraging the power of large-scale training on diverse data.
- The researchers investigate how well these models can perform the task of IQA, which is crucial for applications like photo editing, video streaming, and image-based decision making.
Plain English Explanation
Multimodal large language models (M-LLMs) are a new type of artificial intelligence that can understand and work with both text and images. These models are trained on huge amounts of data, allowing them to learn complex relationships between language and visual information.
In this study, the researchers explored how well M-LLMs can assess the quality of images. Image quality assessment (IQA) is an important task in many real-world applications, like photo editing software, video streaming services, and systems that make decisions based on visual data. The researchers wanted to see if these powerful M-LLMs could perform IQA effectively, potentially outperforming other AI approaches.
Technical Explanation
The researchers evaluated the performance of several state-of-the-art M-LLMs, including DALL-E 2, Imagen, and BLIP, on a variety of IQA datasets. They compared the M-LLMs to traditional IQA models and analyzed the factors that contribute to their performance. The results showed that M-LLMs can achieve state-of-the-art results on IQA tasks, often outperforming specialized IQA models.
The researchers also investigated how the internal representations and attention mechanisms of M-LLMs can be used to explain their decision-making process and provide insights into the visual features they prioritize for IQA. This can help users better understand and trust the model's assessments.
Critical Analysis
The paper provides a thorough and well-designed evaluation of M-LLMs for IQA, covering a range of state-of-the-art models and datasets. However, the researchers acknowledge that their study is limited to a specific set of M-LLMs and IQA benchmarks. Further research is needed to explore the broader applicability of M-LLMs in other visual understanding tasks and real-world scenarios.
Additionally, the paper does not delve deeply into the potential biases or limitations of the M-LLMs, which is an important consideration for the responsible deployment of these models in high-stakes applications like image-based decision making.
Conclusion
This study demonstrates the impressive capabilities of multimodal large language models in the domain of image quality assessment. The researchers show that these powerful AI systems can outperform specialized IQA models, highlighting their potential to transform a wide range of visual understanding tasks. The insights into the inner workings of M-LLMs also open up new avenues for explainable AI and building user trust in these technologies. As M-LLMs continue to evolve, further research is needed to fully harness their capabilities and address potential limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comprehensive Study of Multimodal Large Language Models for Image Quality Assessment
Tianhe Wu, Kede Ma, Jie Liang, Yujiu Yang, Lei Zhang
While Multimodal Large Language Models (MLLMs) have experienced significant advancement in visual understanding and reasoning, their potential to serve as powerful, flexible, interpretable, and text-driven models for Image Quality Assessment (IQA) remains largely unexplored. In this paper, we conduct a comprehensive and systematic study of prompting MLLMs for IQA. We first investigate nine prompting systems for MLLMs as the combinations of three standardized testing procedures in psychophysics (i.e., the single-stimulus, double-stimulus, and multiple-stimulus methods) and three popular prompting strategies in natural language processing (i.e., the standard, in-context, and chain-of-thought prompting). We then present a difficult sample selection procedure, taking into account sample diversity and uncertainty, to further challenge MLLMs equipped with the respective optimal prompting systems. We assess three open-source and one closed-source MLLMs on several visual attributes of image quality (e.g., structural and textural distortions, geometric transformations, and color differences) in both full-reference and no-reference scenarios. Experimental results show that only the closed-source GPT-4V provides a reasonable account for human perception of image quality, but is weak at discriminating fine-grained quality variations (e.g., color differences) and at comparing visual quality of multiple images, tasks humans can perform effortlessly.
Read more7/12/2024

0
Depicting Beyond Scores: Advancing Image Quality Assessment through Multi-modal Language Models
Zhiyuan You, Zheyuan Li, Jinjin Gu, Zhenfei Yin, Tianfan Xue, Chao Dong
We introduce a Depicted image Quality Assessment method (DepictQA), overcoming the constraints of traditional score-based methods. DepictQA allows for detailed, language-based, human-like evaluation of image quality by leveraging Multi-modal Large Language Models (MLLMs). Unlike conventional Image Quality Assessment (IQA) methods relying on scores, DepictQA interprets image content and distortions descriptively and comparatively, aligning closely with humans' reasoning process. To build the DepictQA model, we establish a hierarchical task framework, and collect a multi-modal IQA training dataset. To tackle the challenges of limited training data and multi-image processing, we propose to use multi-source training data and specialized image tags. These designs result in a better performance of DepictQA than score-based approaches on multiple benchmarks. Moreover, compared with general MLLMs, DepictQA can generate more accurate reasoning descriptive languages. We also demonstrate that our full-reference dataset can be extended to non-reference applications. These results showcase the research potential of multi-modal IQA methods. Codes and datasets are available in https://depictqa.github.io.
Read more7/16/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
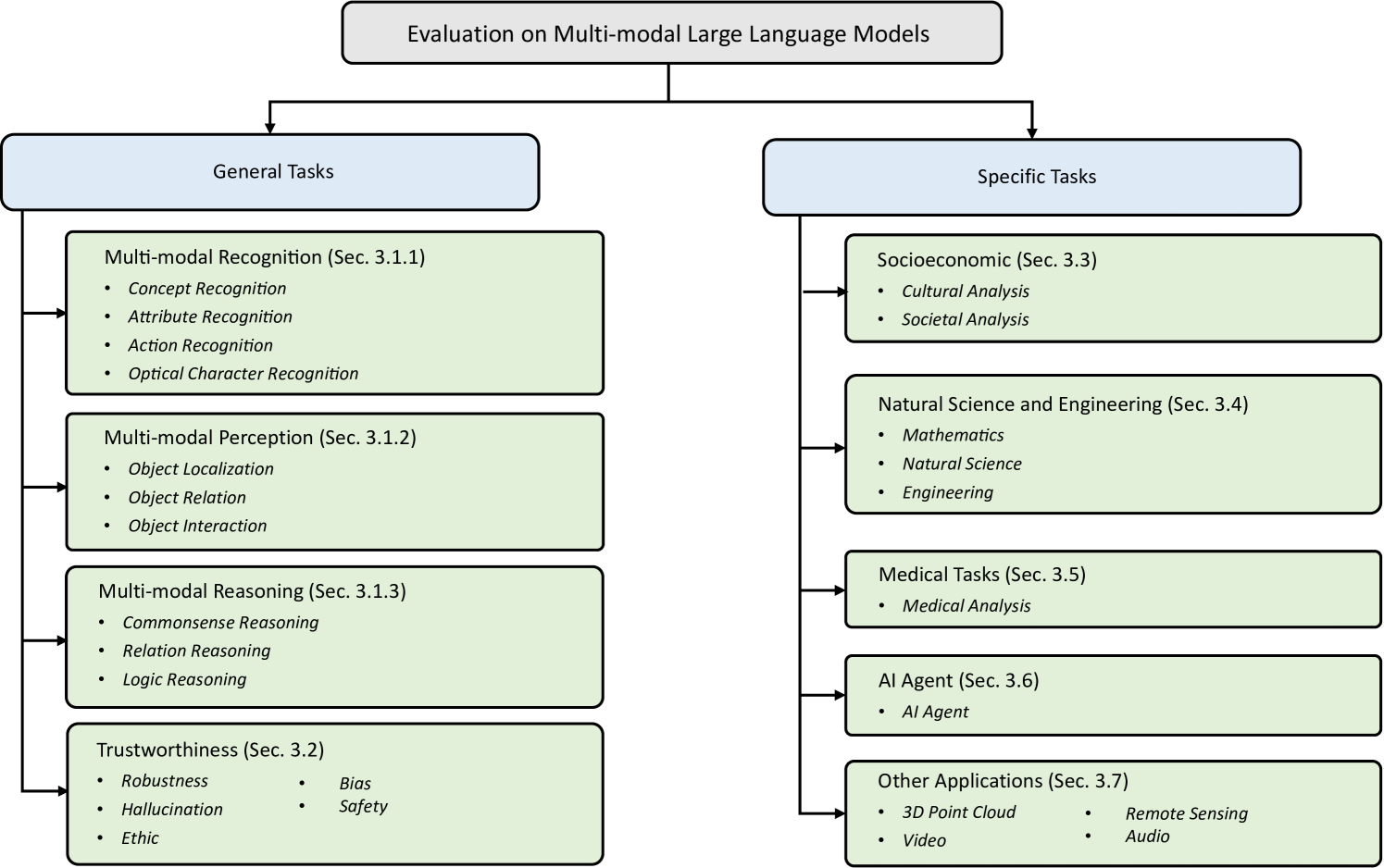
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024
0
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
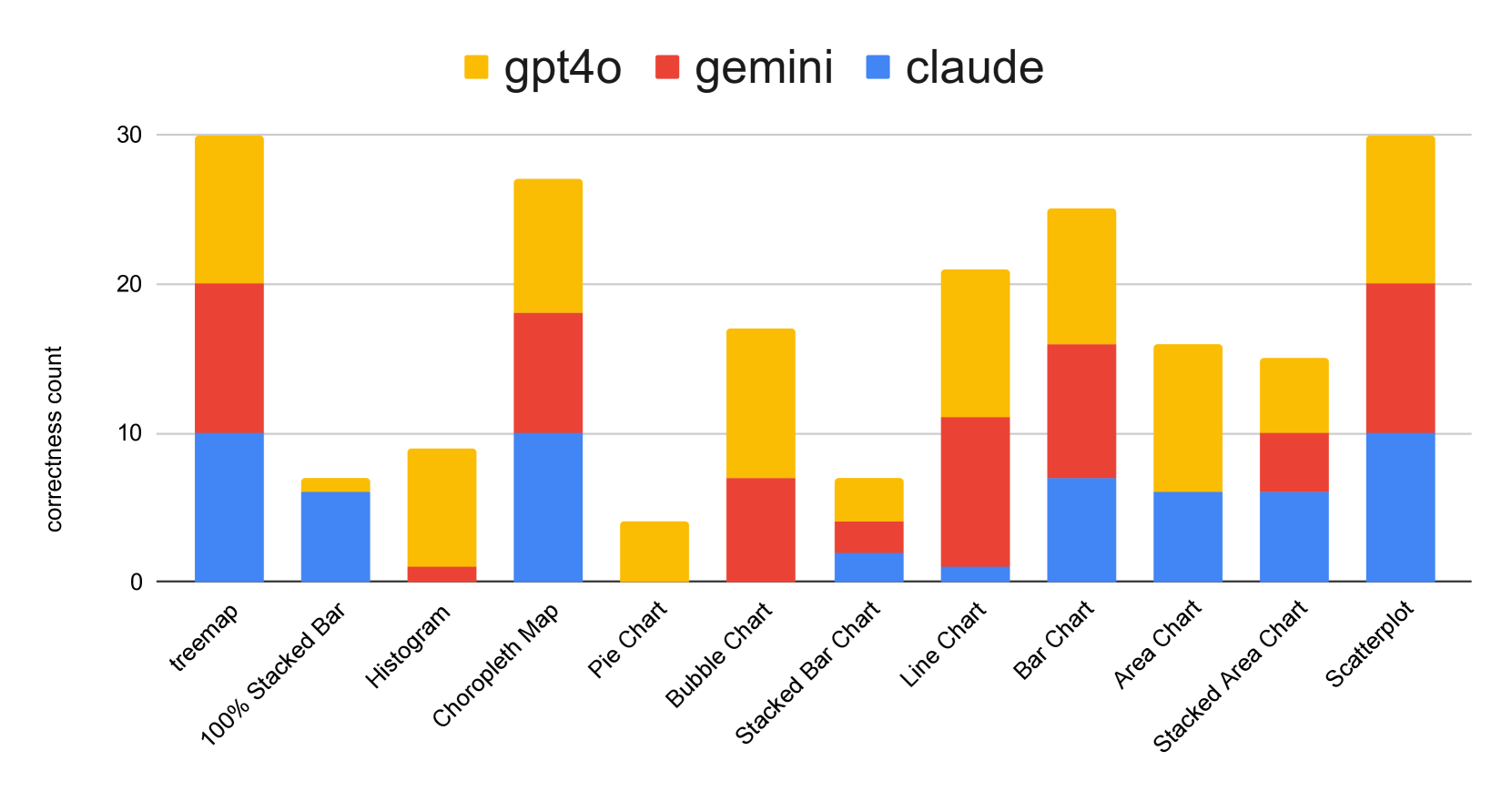
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024