The Limits and Potentials of Local SGD for Distributed Heterogeneous Learning with Intermittent Communication
2405.11667
0
0

Abstract
Local SGD is a popular optimization method in distributed learning, often outperforming other algorithms in practice, including mini-batch SGD. Despite this success, theoretically proving the dominance of local SGD in settings with reasonable data heterogeneity has been difficult, creating a significant gap between theory and practice. In this paper, we provide new lower bounds for local SGD under existing first-order data heterogeneity assumptions, showing that these assumptions are insufficient to prove the effectiveness of local update steps. Furthermore, under these same assumptions, we demonstrate the min-max optimality of accelerated mini-batch SGD, which fully resolves our understanding of distributed optimization for several problem classes. Our results emphasize the need for better models of data heterogeneity to understand the effectiveness of local SGD in practice. Towards this end, we consider higher-order smoothness and heterogeneity assumptions, providing new upper bounds that imply the dominance of local SGD over mini-batch SGD when data heterogeneity is low.
Create account to get full access
Overview
- This paper examines the effectiveness of Local Stochastic Gradient Descent (Local SGD) for distributed, heterogeneous learning in scenarios with intermittent communication.
- Local SGD is a technique where each device or node in a distributed system performs local updates before occasionally sharing their model with a central coordinator.
- The paper explores the limits and potentials of Local SGD in the presence of device heterogeneity and intermittent communication.
Plain English Explanation
The paper looks at a technique called Local Stochastic Gradient Descent (Local SGD) that can be used in distributed machine learning systems. In a distributed system, you might have many different devices or nodes (like phones, computers, etc.) each working on a piece of a larger machine learning problem.
With Local SGD, each device performs its own model updates locally, without constantly communicating with a central coordinator. The devices only occasionally share their model updates, rather than communicating after every single update. This can be helpful when the devices have different capabilities (are "heterogeneous") or when the communication between devices is unreliable or intermittent.
The researchers in this paper investigate the pros and cons of using Local SGD in these types of distributed, heterogeneous learning scenarios with intermittent communication. They want to understand the limits and potentials of this approach.
Technical Explanation
The paper analyzes the performance of Local SGD in distributed learning settings where the participating devices have different data distributions and computational capabilities (i.e. are heterogeneous), and communication between devices is intermittent.
The authors provide a convergence analysis of Local SGD under these challenging conditions. They derive new upper bounds on the optimization error, which highlight the tradeoffs between local update frequency, device heterogeneity, and communication reliability.
The theoretical analysis is complemented by numerical experiments that validate the insights from the convergence analysis. The results show that Local SGD can be more robust than standard distributed SGD when communication is limited, but also identify regimes where the benefits of Local SGD diminish.
The paper also discusses connections to related work, such as analyses of the singular limit of gradient descent with noise injection and improved generalization bounds for communication-efficient federated learning.
Critical Analysis
The paper provides a thorough theoretical analysis of Local SGD in the presence of device heterogeneity and intermittent communication. The derived convergence bounds offer insights into the tradeoffs involved and help identify the regimes where Local SGD excels or underperforms compared to standard distributed SGD.
However, the analysis relies on several simplifying assumptions, such as convexity of the objective function and the availability of an unbiased gradient estimator. These assumptions may not hold in more realistic, non-convex machine learning settings. Further research is needed to understand the performance of Local SGD in such scenarios.
Additionally, the paper does not address practical implementation details, such as the impact of gradient compression techniques or the effect of device failures and stragglers. Investigating the robustness of Local SGD to these practical challenges would be an important next step.
Conclusion
This paper provides a comprehensive theoretical and experimental examination of the limits and potentials of Local SGD for distributed, heterogeneous learning with intermittent communication. The key insights include the identification of tradeoffs between local update frequency, device heterogeneity, and communication reliability, as well as the potential for Local SGD to outperform standard distributed SGD in certain regimes.
While the analysis relies on simplifying assumptions, the paper offers a valuable contribution to the understanding of distributed learning algorithms and sets the stage for further research into the practical deployment of Local SGD in real-world, non-convex machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
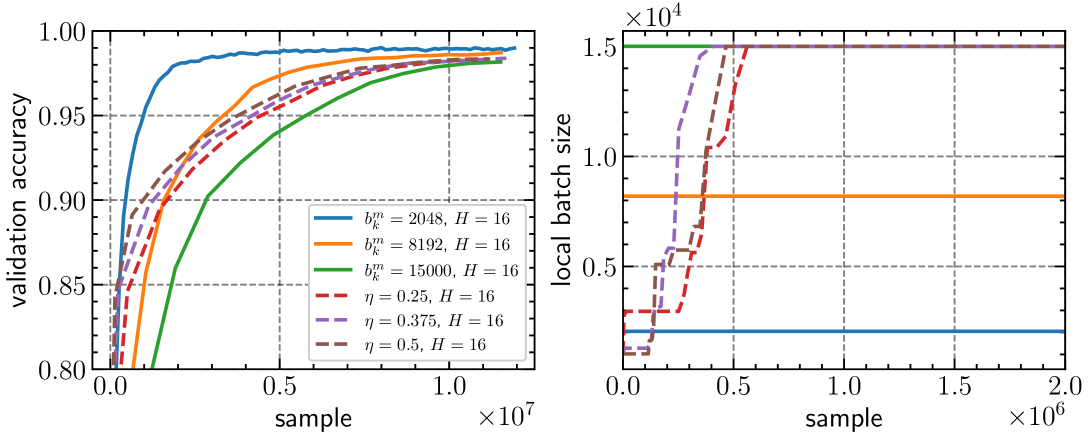
Communication-Efficient Adaptive Batch Size Strategies for Distributed Local Gradient Methods
Tim Tsz-Kit Lau, Weijian Li, Chenwei Xu, Han Liu, Mladen Kolar
0
0
Modern deep neural networks often require distributed training with many workers due to their large size. As worker numbers increase, communication overheads become the main bottleneck in data-parallel minibatch stochastic gradient methods with per-iteration gradient synchronization. Local gradient methods like Local SGD reduce communication by only syncing after several local steps. Despite understanding their convergence in i.i.d. and heterogeneous settings and knowing the importance of batch sizes for efficiency and generalization, optimal local batch sizes are difficult to determine. We introduce adaptive batch size strategies for local gradient methods that increase batch sizes adaptively to reduce minibatch gradient variance. We provide convergence guarantees under homogeneous data conditions and support our claims with image classification experiments, demonstrating the effectiveness of our strategies in training and generalization.
6/21/2024
🌀
Demystifying Why Local Aggregation Helps: Convergence Analysis of Hierarchical SGD
Jiayi Wang, Shiqiang Wang, Rong-Rong Chen, Mingyue Ji
0
0
Hierarchical SGD (H-SGD) has emerged as a new distributed SGD algorithm for multi-level communication networks. In H-SGD, before each global aggregation, workers send their updated local models to local servers for aggregations. Despite recent research efforts, the effect of local aggregation on global convergence still lacks theoretical understanding. In this work, we first introduce a new notion of upward and downward divergences. We then use it to conduct a novel analysis to obtain a worst-case convergence upper bound for two-level H-SGD with non-IID data, non-convex objective function, and stochastic gradient. By extending this result to the case with random grouping, we observe that this convergence upper bound of H-SGD is between the upper bounds of two single-level local SGD settings, with the number of local iterations equal to the local and global update periods in H-SGD, respectively. We refer to this as the sandwich behavior. Furthermore, we extend our analytical approach based on upward and downward divergences to study the convergence for the general case of H-SGD with more than two levels, where the sandwich behavior still holds. Our theoretical results provide key insights of why local aggregation can be beneficial in improving the convergence of H-SGD.
4/12/2024
Local Methods with Adaptivity via Scaling
Savelii Chezhegov, Sergey Skorik, Nikolas Khachaturov, Danil Shalagin, Aram Avetisyan, Aleksandr Beznosikov, Martin Tak'av{c}, Yaroslav Kholodov, Alexander Gasnikov
0
0
The rapid development of machine learning and deep learning has introduced increasingly complex optimization challenges that must be addressed. Indeed, training modern, advanced models has become difficult to implement without leveraging multiple computing nodes in a distributed environment. Distributed optimization is also fundamental to emerging fields such as federated learning. Specifically, there is a need to organize the training process to minimize the time lost due to communication. A widely used and extensively researched technique to mitigate the communication bottleneck involves performing local training before communication. This approach is the focus of our paper. Concurrently, adaptive methods that incorporate scaling, notably led by Adam, have gained significant popularity in recent years. Therefore, this paper aims to merge the local training technique with the adaptive approach to develop efficient distributed learning methods. We consider the classical Local SGD method and enhance it with a scaling feature. A crucial aspect is that the scaling is described generically, allowing us to analyze various approaches, including Adam, RMSProp, and OASIS, in a unified manner. In addition to theoretical analysis, we validate the performance of our methods in practice by training a neural network.
6/14/2024
🔍
Improved Stability and Generalization Guarantees of the Decentralized SGD Algorithm
Batiste Le Bars, Aur'elien Bellet, Marc Tommasi, Kevin Scaman, Giovanni Neglia
0
0
This paper presents a new generalization error analysis for Decentralized Stochastic Gradient Descent (D-SGD) based on algorithmic stability. The obtained results overhaul a series of recent works that suggested an increased instability due to decentralization and a detrimental impact of poorly-connected communication graphs on generalization. On the contrary, we show, for convex, strongly convex and non-convex functions, that D-SGD can always recover generalization bounds analogous to those of classical SGD, suggesting that the choice of graph does not matter. We then argue that this result is coming from a worst-case analysis, and we provide a refined optimization-dependent generalization bound for general convex functions. This new bound reveals that the choice of graph can in fact improve the worst-case bound in certain regimes, and that surprisingly, a poorly-connected graph can even be beneficial for generalization.
6/14/2024