Localize, Understand, Collaborate: Semantic-Aware Dragging via Intention Reasoner

0

Sign in to get full access
Overview
- This paper presents an approach called "Localize, Understand, Collaborate: Semantic-Aware Dragging via Intention Reasoner" for improving the experience of drag-and-drop interactions.
- The key ideas are to enable users to localize the target object, understand its semantic meaning, and collaborate with the system to refine the interaction.
- The authors introduce an "Intention Reasoner" module that infers the user's high-level intentions and adapts the dragging behavior accordingly.
Plain English Explanation
The paper tackles the common problem of drag-and-drop interactions, where users often struggle to precisely select and move objects on a digital interface. To address this, the researchers developed a system that aims to make drag-and-drop more intuitive and efficient.
At the core of their approach is the "Intention Reasoner", which tries to understand what the user is trying to achieve when dragging an object. For example, is the user trying to move the object to a specific location, or are they trying to resize or rotate it? By inferring the user's high-level intentions, the system can adapt the dragging behavior to better match what the user wants to do.
To enable this, the system first helps the user localize the target object they want to interact with. It then analyzes the semantic meaning of the object, such as whether it's a button, text, or image. Armed with this understanding, the system can now collaborate with the user to refine the drag-and-drop interaction in a way that feels more natural and responsive.
For example, if the user is trying to move a button, the system might snap the object to the nearest valid position, or if the user is trying to resize an image, it might constrain the resizing to maintain the proper aspect ratio. By anticipating the user's goals and adjusting the interaction accordingly, the system aims to create a more seamless and productive drag-and-drop experience.
Technical Explanation
The paper introduces a framework called "Localize, Understand, Collaborate" that enhances drag-and-drop interactions by leveraging semantic understanding and intention reasoning. The key components are:
-
Localization: The system first helps the user precisely select the target object they want to interact with, using techniques like segmentation and object detection.
-
Semantic Understanding: Once the object is localized, the system analyzes its semantic meaning, such as whether it's a button, text, or image. This semantic information is used to guide the subsequent interaction.
-
Intention Reasoning: The core of the approach is the "Intention Reasoner" module, which infers the user's high-level goals based on the object's semantics and the ongoing drag-and-drop interaction. For example, is the user trying to move, resize, or rotate the object?
-
Collaborative Interaction: Armed with the localized object and the inferred user intention, the system can now adapt the dragging behavior to better suit the user's goals. For instance, it might snap the object to the nearest valid position or maintain the aspect ratio when resizing an image.
The authors evaluate their approach through a user study, demonstrating that it can significantly improve the efficiency and user experience of drag-and-drop interactions compared to a traditional approach.
Critical Analysis
The paper presents a promising approach to enhancing drag-and-drop interactions by incorporating semantic understanding and intention reasoning. The key strength of the system is its ability to anticipate the user's high-level goals and adapt the interaction accordingly, which can lead to a more intuitive and productive user experience.
However, the paper does not discuss the limitations or potential challenges of this approach. For example, the accuracy of the intention reasoning module may depend on the complexity of the user's goals, and it's unclear how the system would handle ambiguous or unexpected user intentions.
Additionally, the paper does not explore the generalizability of the approach beyond the specific use cases and interface elements presented in the experiments. It would be valuable to see how the system would perform with a wider range of interface elements, interactions, and user scenarios.
Further research could also investigate the trade-offs between the benefits of the collaborative interaction and any potential cognitive or perceptual overhead imposed on the user by the system's adaptations. It's important to ensure that the system's interventions enhance, rather than hinder, the user's natural interaction flow.
Conclusion
The "Localize, Understand, Collaborate" framework presented in this paper offers a novel approach to improving drag-and-drop interactions by leveraging semantic understanding and intention reasoning. By anticipating the user's high-level goals and adapting the interaction accordingly, the system aims to create a more seamless and productive user experience.
While the paper demonstrates promising results, further research is needed to address the potential limitations and explore the broader applicability of the approach. Nonetheless, this work represents an important step towards more intelligent and user-friendly drag-and-drop interactions, with implications for a wide range of digital interfaces and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Localize, Understand, Collaborate: Semantic-Aware Dragging via Intention Reasoner
Xing Cui, Peipei Li, Zekun Li, Xuannan Liu, Yueying Zou, Zhaofeng He
Flexible and accurate drag-based editing is a challenging task that has recently garnered significant attention. Current methods typically model this problem as automatically learning ``how to drag'' through point dragging and often produce one deterministic estimation, which presents two key limitations: 1) Overlooking the inherently ill-posed nature of drag-based editing, where multiple results may correspond to a given input, as illustrated in Fig.1; 2) Ignoring the constraint of image quality, which may lead to unexpected distortion. To alleviate this, we propose LucidDrag, which shifts the focus from ``how to drag'' to a paradigm of ``what-then-how''. LucidDrag comprises an intention reasoner and a collaborative guidance sampling mechanism. The former infers several optimal editing strategies, identifying what content and what semantic direction to be edited. Based on the former, the latter addresses how to drag by collaboratively integrating existing editing guidance with the newly proposed semantic guidance and quality guidance. Specifically, semantic guidance is derived by establishing a semantic editing direction based on reasoned intentions, while quality guidance is achieved through classifier guidance using an image fidelity discriminator. Both qualitative and quantitative comparisons demonstrate the superiority of LucidDrag over previous methods. The code will be released.
Read more6/4/2024

0
FastDrag: Manipulate Anything in One Step
Xuanjia Zhao, Jian Guan, Congyi Fan, Dongli Xu, Youtian Lin, Haiwei Pan, Pengming Feng
Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance. Project page: https://fastdrag-site.github.io/ .
Read more6/7/2024
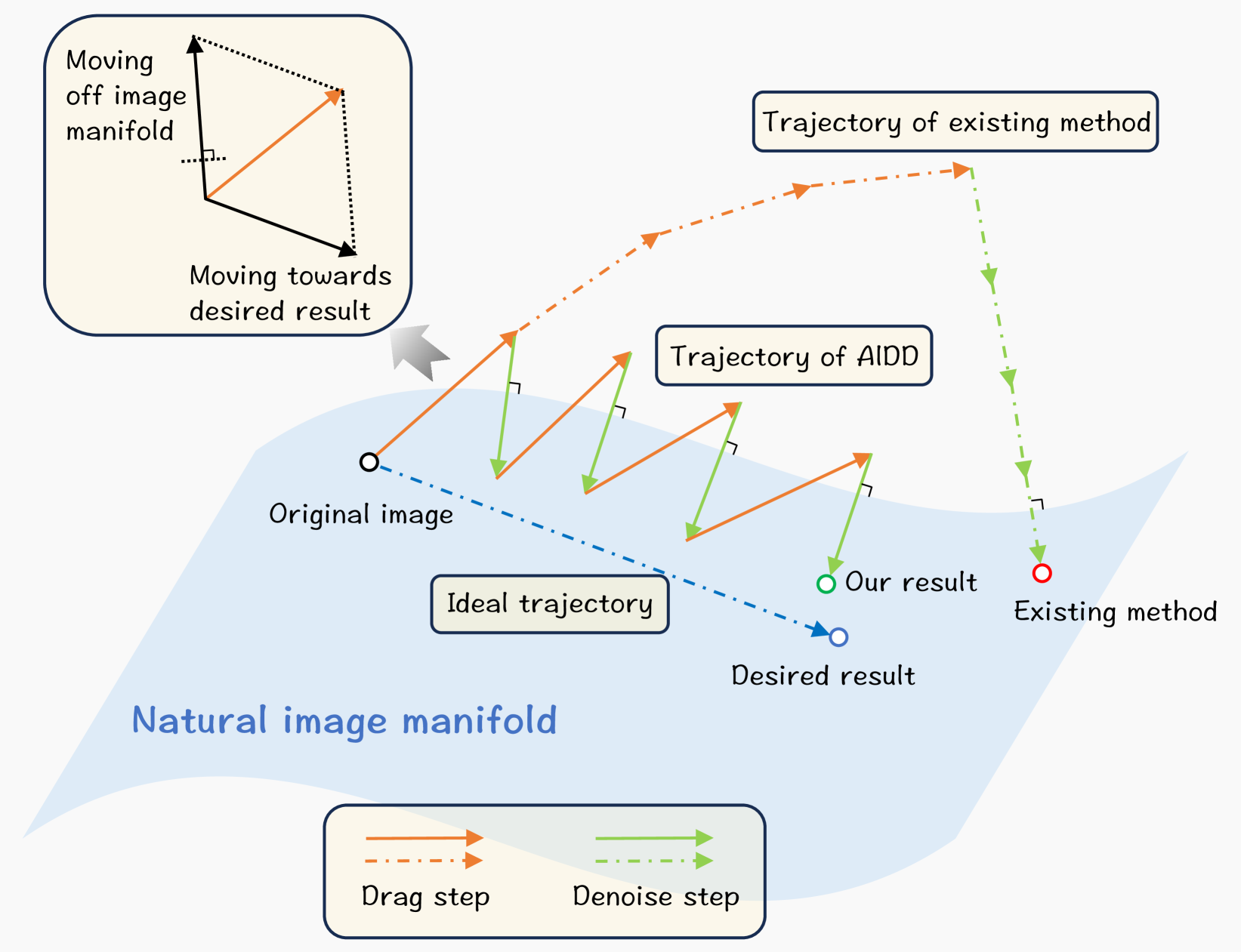
0
GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
Zewei Zhang, Huan Liu, Jun Chen, Xiangyu Xu
In this paper, we introduce GoodDrag, a novel approach to improve the stability and image quality of drag editing. Unlike existing methods that struggle with accumulated perturbations and often result in distortions, GoodDrag introduces an AlDD framework that alternates between drag and denoising operations within the diffusion process, effectively improving the fidelity of the result. We also propose an information-preserving motion supervision operation that maintains the original features of the starting point for precise manipulation and artifact reduction. In addition, we contribute to the benchmarking of drag editing by introducing a new dataset, Drag100, and developing dedicated quality assessment metrics, Dragging Accuracy Index and Gemini Score, utilizing Large Multimodal Models. Extensive experiments demonstrate that the proposed GoodDrag compares favorably against the state-of-the-art approaches both qualitatively and quantitatively. The project page is https://gooddrag.github.io.
Read more4/11/2024

0
InstantDrag: Improving Interactivity in Drag-based Image Editing
Joonghyuk Shin, Daehyeon Choi, Jaesik Park
Drag-based image editing has recently gained popularity for its interactivity and precision. However, despite the ability of text-to-image models to generate samples within a second, drag editing still lags behind due to the challenge of accurately reflecting user interaction while maintaining image content. Some existing approaches rely on computationally intensive per-image optimization or intricate guidance-based methods, requiring additional inputs such as masks for movable regions and text prompts, thereby compromising the interactivity of the editing process. We introduce InstantDrag, an optimization-free pipeline that enhances interactivity and speed, requiring only an image and a drag instruction as input. InstantDrag consists of two carefully designed networks: a drag-conditioned optical flow generator (FlowGen) and an optical flow-conditioned diffusion model (FlowDiffusion). InstantDrag learns motion dynamics for drag-based image editing in real-world video datasets by decomposing the task into motion generation and motion-conditioned image generation. We demonstrate InstantDrag's capability to perform fast, photo-realistic edits without masks or text prompts through experiments on facial video datasets and general scenes. These results highlight the efficiency of our approach in handling drag-based image editing, making it a promising solution for interactive, real-time applications.
Read more9/16/2024