LoCoCo: Dropping In Convolutions for Long Context Compression
2406.05317
0
0

Abstract
This paper tackles the memory hurdle of processing long context sequences in Large Language Models (LLMs), by presenting a novel approach, Dropping In Convolutions for Long Context Compression (LoCoCo). LoCoCo employs only a fixed-size Key-Value (KV) cache, and can enhance efficiency in both inference and fine-tuning stages. Diverging from prior methods that selectively drop KV pairs based on heuristics, LoCoCo leverages a data-driven adaptive fusion technique, blending previous KV pairs with incoming tokens to minimize the loss of contextual information and ensure accurate attention modeling. This token integration is achieved through injecting one-dimensional convolutional kernels that dynamically calculate mixing weights for each KV cache slot. Designed for broad compatibility with existing LLM frameworks, LoCoCo allows for straightforward drop-in integration without needing architectural modifications, while incurring minimal tuning overhead. Experiments demonstrate that LoCoCo maintains consistently outstanding performance across various context lengths and can achieve a high context compression rate during both inference and fine-tuning phases. During inference, we successfully compressed up to 3482 tokens into a 128-size KV cache, while retaining comparable performance to the full sequence - an accuracy improvement of up to 0.2791 compared to baselines at the same cache size. During post-training tuning, we also effectively extended the context length from 4K to 32K using a KV cache of fixed size 512, achieving performance similar to fine-tuning with entire sequences.
Create account to get full access
Overview
- This paper introduces LoCoCo, a novel approach to long context compression in large language models (LLMs).
- LoCoCo aims to address the challenge of effectively modeling long-range dependencies in text, which existing LLMs often struggle with.
- The key idea is to incorporate convolutional layers into the model architecture to capture local and global patterns in the input sequence.
Plain English Explanation
Large language models like GPT-3 are incredibly powerful at understanding and generating human-like text. However, they can have difficulty with tasks that require understanding long-range relationships and context in a piece of writing. The LoCoCo paper proposes a new way to address this problem.
The researchers developed a model called LoCoCo that adds convolutional neural networks (CNNs) to the standard transformer-based architecture used in many LLMs. CNNs are good at detecting local patterns in data, like the relationships between nearby words in a sentence. By incorporating CNNs, LoCoCo can better capture both the local and global context in an input text, helping the model understand longer-range dependencies.
The SNAPKV paper and other research have shown that existing LLMs can struggle with tasks that require understanding lengthy input sequences. LoCoCo aims to address this limitation by compressing the long context in a more effective way.
Technical Explanation
The core idea behind LoCoCo is to incorporate convolutional layers into a transformer-based language model architecture. Specifically, the researchers introduce convolutional blocks that operate in parallel with the standard transformer layers.
These convolutional blocks take the input sequence and apply a series of 1D convolutions to extract local and global features. The output of the convolutional blocks is then combined with the output of the transformer layers, allowing the model to leverage both the local pattern detection of the CNNs and the long-range modeling capabilities of the transformers.
The researchers evaluate LoCoCo on a range of long-context tasks, including text summarization and question answering. They find that LoCoCo outperforms standard transformer-based models, demonstrating the benefits of the convolutional compression approach.
Critical Analysis
The LoCoCo paper presents a promising approach to addressing the long-range context modeling limitations of existing LLMs. The combination of transformers and convolutional layers is an interesting architectural choice that allows the model to leverage the strengths of both types of neural networks.
However, the paper does not provide a thorough analysis of the limitations or potential issues with the LoCoCo approach. For example, it's unclear how the model scales to extremely long input sequences or whether the convolutional layers introduce additional computational overhead.
Additionally, the paper focuses primarily on evaluating LoCoCo on existing long-context tasks, but does not explore potential novel applications or use cases that could benefit from the model's improved long-range understanding capabilities.
Further research is needed to fully understand the strengths, weaknesses, and broader implications of the LoCoCo approach. Nonetheless, this work represents an important step forward in addressing a key challenge in large language model development.
Conclusion
The LoCoCo paper introduces a novel approach to long context compression in large language models. By incorporating convolutional layers into a transformer-based architecture, the model can more effectively capture both local and global patterns in input text, addressing a key limitation of existing LLMs.
While the paper demonstrates promising results on long-context tasks, further research is needed to fully understand the capabilities and limitations of the LoCoCo approach. Nonetheless, this work represents an important contribution to the ongoing effort to develop language models with stronger long-range understanding abilities, which could have significant implications for a wide range of natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LLoCO: Learning Long Contexts Offline
Sijun Tan, Xiuyu Li, Shishir Patil, Ziyang Wu, Tianjun Zhang, Kurt Keutzer, Joseph E. Gonzalez, Raluca Ada Popa
0
0
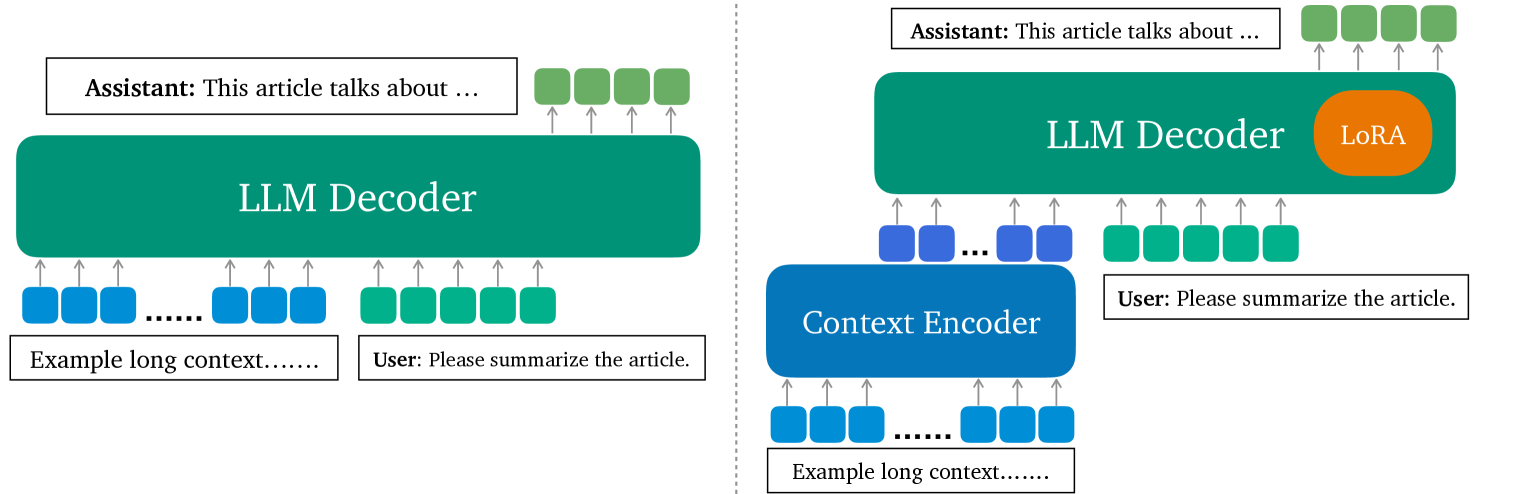
Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30times$ fewer tokens during inference. LLoCO achieves up to $7.62times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
4/12/2024

LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, Li Yuan
0
0
Long-context Multimodal Large Language Models (MLLMs) demand substantial computational resources for inference as the growth of their multimodal Key-Value (KV) cache, in response to increasing input lengths, challenges memory and time efficiency. Unlike single-modality LLMs that manage only textual contexts, the KV cache of long-context MLLMs includes representations from multiple images with temporal and spatial relationships and related textual contexts. The predominance of image tokens means traditional optimizations for LLMs' KV caches are unsuitable for multimodal long-context settings, and no prior works have addressed this challenge. In this work, we introduce LOOK-M, a pioneering, fine-tuning-free approach that efficiently reduces the multimodal KV cache size while maintaining performance comparable to a full cache. We observe that during prompt prefill, the model prioritizes more textual attention over image features, and based on the multimodal interaction observation, a new proposed text-prior method is explored to compress the KV cache. Furthermore, to mitigate the degradation of image contextual information, we propose several compensatory strategies using KV pairs merging. LOOK-M demonstrates that with a significant reduction in KV Cache memory usage, such as reducing it by 80% in some cases, it not only achieves up to 1.5x faster decoding but also maintains or even enhances performance across a variety of long context multimodal tasks.
6/27/2024
Training-Free Exponential Extension of Sliding Window Context with Cascading KV Cache
Jeffrey Willette, Heejun Lee, Youngwan Lee, Myeongjae Jeon, Sung Ju Hwang
0
0
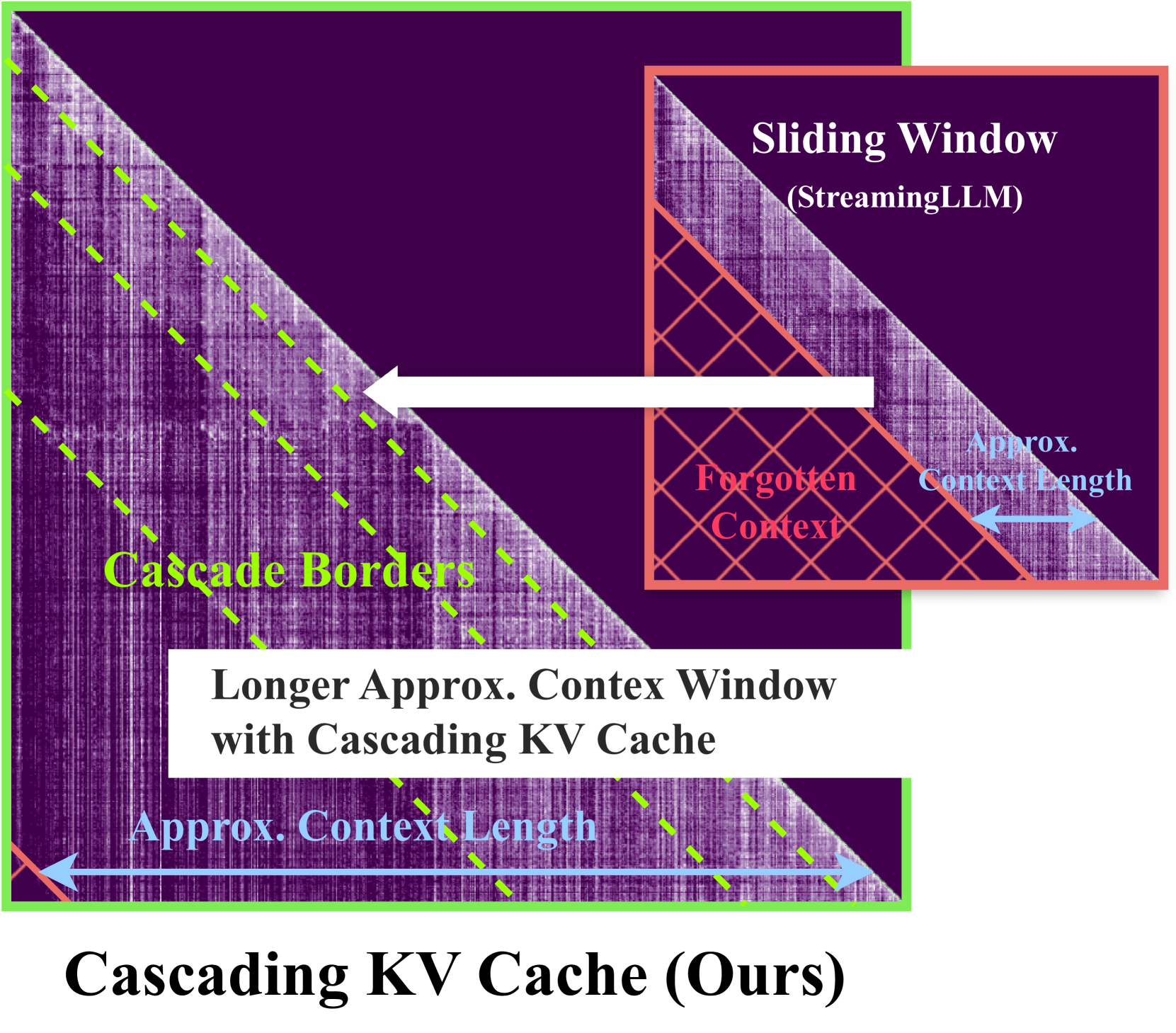
The context window within a transformer provides a form of active memory for the current task, which can be useful for few-shot learning and conditional generation, both which depend heavily on previous context tokens. However, as the context length grows, the computational cost increases quadratically. Recent works have shown that saving a few initial tokens along with a fixed-sized sliding window leads to stable streaming generation with linear complexity in transformer-based Large Language Models (LLMs). However, they make suboptimal use of the fixed window by naively evicting all tokens unconditionally from the key-value (KV) cache once they reach the end of the window, resulting in tokens being forgotten and no longer able to affect subsequent predictions. To overcome this limitation, we propose a novel mechanism for storing longer sliding window contexts with the same total cache size by keeping separate cascading sub-cache buffers whereby each subsequent buffer conditionally accepts a fraction of the relatively more important tokens evicted from the previous buffer. Our method results in a dynamic KV cache that can store tokens from the more distant past than a fixed, static sliding window approach. Our experiments show improvements of 5.6% on long context generation (LongBench), 1.2% in streaming perplexity (PG19), and 0.6% in language understanding (MMLU STEM) using LLMs given the same fixed cache size. Additionally, we provide an efficient implementation that improves the KV cache latency from 1.33ms per caching operation to 0.54ms, a 59% speedup over previous work.
6/27/2024

VoCo-LLaMA: Towards Vision Compression with Large Language Models
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, Ying Shan, Yansong Tang
0
0
Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos. Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss. However, the LLMs' understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576$times$, resulting in up to 94.8$%$ fewer FLOPs and 69.6$%$ acceleration in inference time. Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks. Our approach presents a promising way to unlock the full potential of VLMs' contextual window, enabling more scalable multi-modal applications. The project page, along with the associated code, can be accessed via $href{https://yxxxb.github.io/VoCo-LLaMA-page/}{text{this https URL}}$.
6/19/2024