Long-context LLMs Struggle with Long In-context Learning
2404.02060
0
0

Abstract
Large Language Models (LLMs) have made significant strides in handling long sequences exceeding 32K tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their abilities in more nuanced, real-world scenarios. This study introduces a specialized benchmark (LongICLBench) focusing on long in-context learning within the realm of extreme-label classification. We meticulously selected six datasets with a label range spanning 28 to 174 classes covering different input (few-shot demonstration) lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate 13 long-context LLMs on our benchmarks. We find that the long-context LLMs perform relatively well on less challenging tasks with shorter demonstration lengths by effectively utilizing the long context window. However, on the most challenging task Discovery with 174 labels, all the LLMs struggle to understand the task definition, thus reaching a performance close to zero. This suggests a notable gap in current LLM capabilities for processing and understanding long, context-rich sequences. Further analysis revealed a tendency among models to favor predictions for labels presented toward the end of the sequence. Their ability to reason over multiple pieces in the long sequence is yet to be improved. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Long-context language models (LLMs) can capture long-range dependencies in text, but struggle with "long in-context learning" where a model has to learn a new skill from a long context.
- The paper examines the limitations of long-context LLMs when it comes to this type of learning, and proposes potential solutions.
Plain English Explanation
Language models are AI systems trained on massive amounts of text data to understand and generate human language. Long-context LLMs can take in and reason about long stretches of text, not just short snippets.
However, this paper found that these powerful models struggle when presented with a long context and asked to learn a new skill or task from that context. For example, if given a long passage of text and then asked to solve a math problem based on the information in the passage, the model would perform poorly compared to simpler models trained just on math.
The researchers think this is because long-context LLMs are optimized for general language understanding, not for quickly learning new skills from extended inputs. The models have difficulty extracting the relevant information from the long context and applying it to the new task.
The paper explores potential solutions, such as incorporating more explicit task-learning mechanisms into the models or breaking down the long context into more manageable chunks. Overcoming these limitations could make long-context LLMs even more versatile and effective.
Technical Explanation
The paper evaluates the performance of long-context language models (LLMs) on "long in-context learning" tasks, where a model must learn a new skill or solve a new problem based on a long passage of text.
The researchers tested several LLMs, including GPT-3 and PaLM, on a variety of tasks ranging from math problem-solving to code generation. They found that despite the models' strong language understanding capabilities, they struggled compared to simpler models trained solely on the specific task.
The authors hypothesize this is because LLMs are optimized for general language modeling, not for rapidly learning new skills from extended contexts. The models have difficulty extracting the most relevant information from the long input and applying it appropriately.
The paper explores potential solutions, such as incorporating more explicit task-learning mechanisms or using a "divide-and-conquer" approach to break down the long context. The researchers also discuss the trade-offs between general-purpose language understanding and specialized task learning.
Critical Analysis
The paper provides a thoughtful and nuanced examination of the limitations of current long-context LLMs when it comes to learning new skills from extended inputs. The experiments are well-designed and the results are clearly articulated.
One potential limitation is that the paper focuses mainly on academic or technical tasks like math and coding. It would be interesting to see how these models perform on more open-ended, real-world tasks that require drawing insights from longer passages of text.
Additionally, the proposed solutions, while promising, may require significant architectural changes or training approaches that introduce their own challenges. Fully addressing the long in-context learning issue may require rethinking fundamental aspects of LLM design.
Overall, this paper makes a valuable contribution by highlighting an important limitation of state-of-the-art language models and proposing directions for future research. Continued progress in this area could unlock even more powerful and versatile AI language understanding capabilities.
Conclusion
This paper sheds light on a notable limitation of long-context language models - their struggle with "long in-context learning" tasks that require rapidly learning a new skill from an extended passage of text. While LLMs excel at general language understanding, the researchers found they underperform simpler models when it comes to applying insights from long contexts to specific problems.
Addressing this limitation could unlock even greater potential for LLMs, allowing them to be more dynamically adaptable and capable of learning new skills on the fly. The proposed solutions, such as enhanced task-learning mechanisms and divide-and-conquer approaches, offer promising avenues for future research. Overcoming the challenges of long in-context learning could be a key step in making language models truly versatile and effective problem-solving tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MileBench: Benchmarking MLLMs in Long Context
Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang
0
0
Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 20 models, revealed that while the closed-source GPT-4(Vision) and Gemini 1.5 outperform others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.
4/30/2024

XL$^2$Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies
Xuanfan Ni, Hengyi Cai, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Piji Li
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks but are constrained by their small context window sizes. Various efforts have been proposed to expand the context window to accommodate even up to 200K input tokens. Meanwhile, building high-quality benchmarks with much longer text lengths and more demanding tasks to provide comprehensive evaluations is of immense practical interest to facilitate long context understanding research of LLMs. However, prior benchmarks create datasets that ostensibly cater to long-text comprehension by expanding the input of traditional tasks, which falls short to exhibit the unique characteristics of long-text understanding, including long dependency tasks and longer text length compatible with modern LLMs' context window size. In this paper, we introduce a benchmark for extremely long context understanding with long-range dependencies, XL$^2$Bench, which includes three scenarios: Fiction Reading, Paper Reading, and Law Reading, and four tasks of increasing complexity: Memory Retrieval, Detailed Understanding, Overall Understanding, and Open-ended Generation, covering 27 subtasks in English and Chinese. It has an average length of 100K+ words (English) and 200K+ characters (Chinese). Evaluating six leading LLMs on XL$^2$Bench, we find that their performance significantly lags behind human levels. Moreover, the observed decline in performance across both the original and enhanced datasets underscores the efficacy of our approach to mitigating data contamination.
4/9/2024
In-Context Learning with Long-Context Models: An In-Depth Exploration
Amanda Bertsch, Maor Ivgi, Uri Alon, Jonathan Berant, Matthew R. Gormley, Graham Neubig
0
0
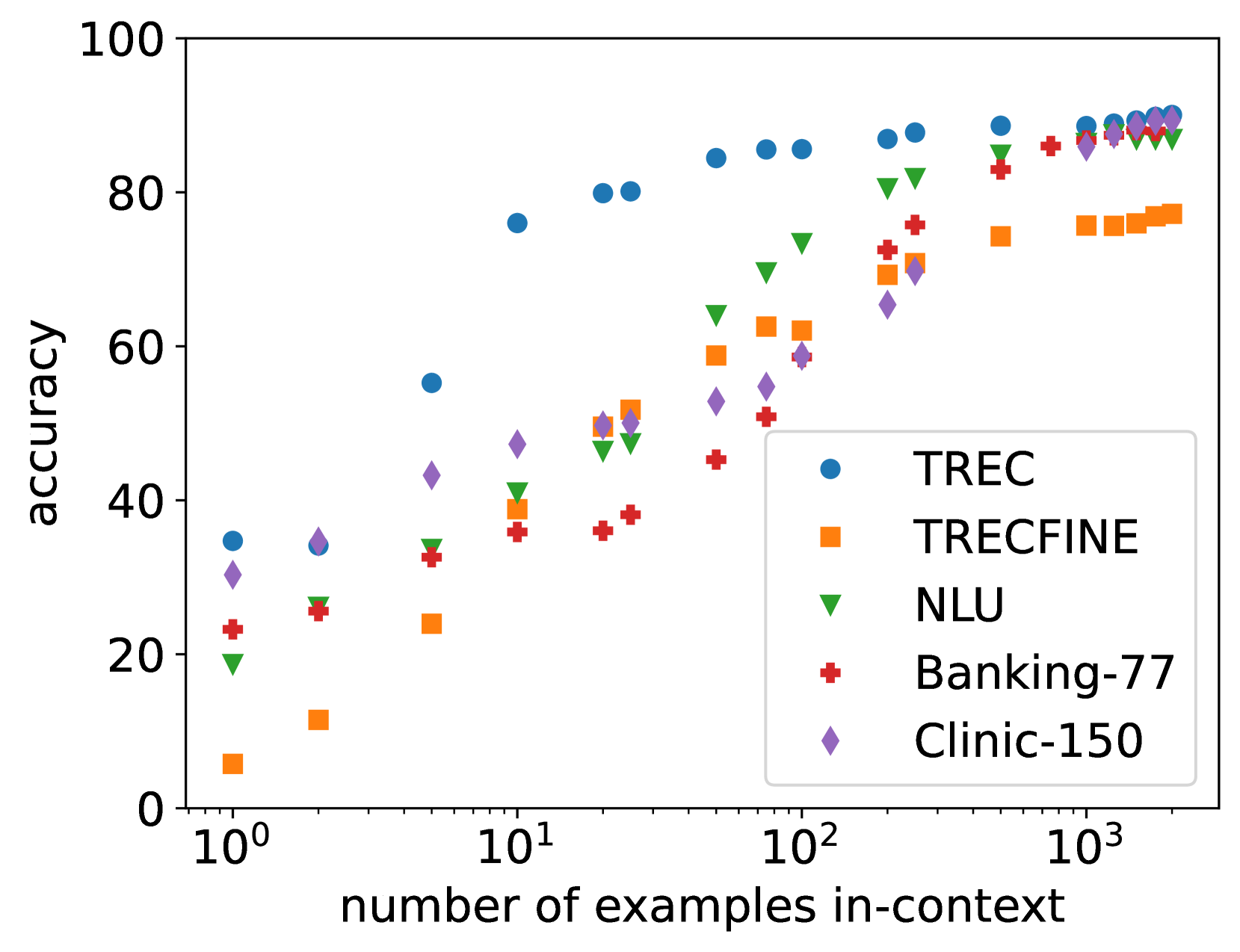
As model context lengths continue to increase, the number of demonstrations that can be provided in-context approaches the size of entire training datasets. We study the behavior of in-context learning (ICL) at this extreme scale on multiple datasets and models. We show that, for many datasets with large label spaces, performance continues to increase with hundreds or thousands of demonstrations. We contrast this with example retrieval and finetuning: example retrieval shows excellent performance at low context lengths but has diminished gains with more demonstrations; finetuning is more data hungry than ICL but can sometimes exceed long-context ICL performance with additional data. We use this ICL setting as a testbed to study several properties of both in-context learning and long-context models. We show that long-context ICL is less sensitive to random input shuffling than short-context ICL, that grouping of same-label examples can negatively impact performance, and that the performance boosts we see do not arise from cumulative gain from encoding many examples together. We conclude that although long-context ICL can be surprisingly effective, most of this gain comes from attending back to similar examples rather than task learning.
5/2/2024
Ada-LEval: Evaluating long-context LLMs with length-adaptable benchmarks
Chonghua Wang, Haodong Duan, Songyang Zhang, Dahua Lin, Kai Chen
0
0
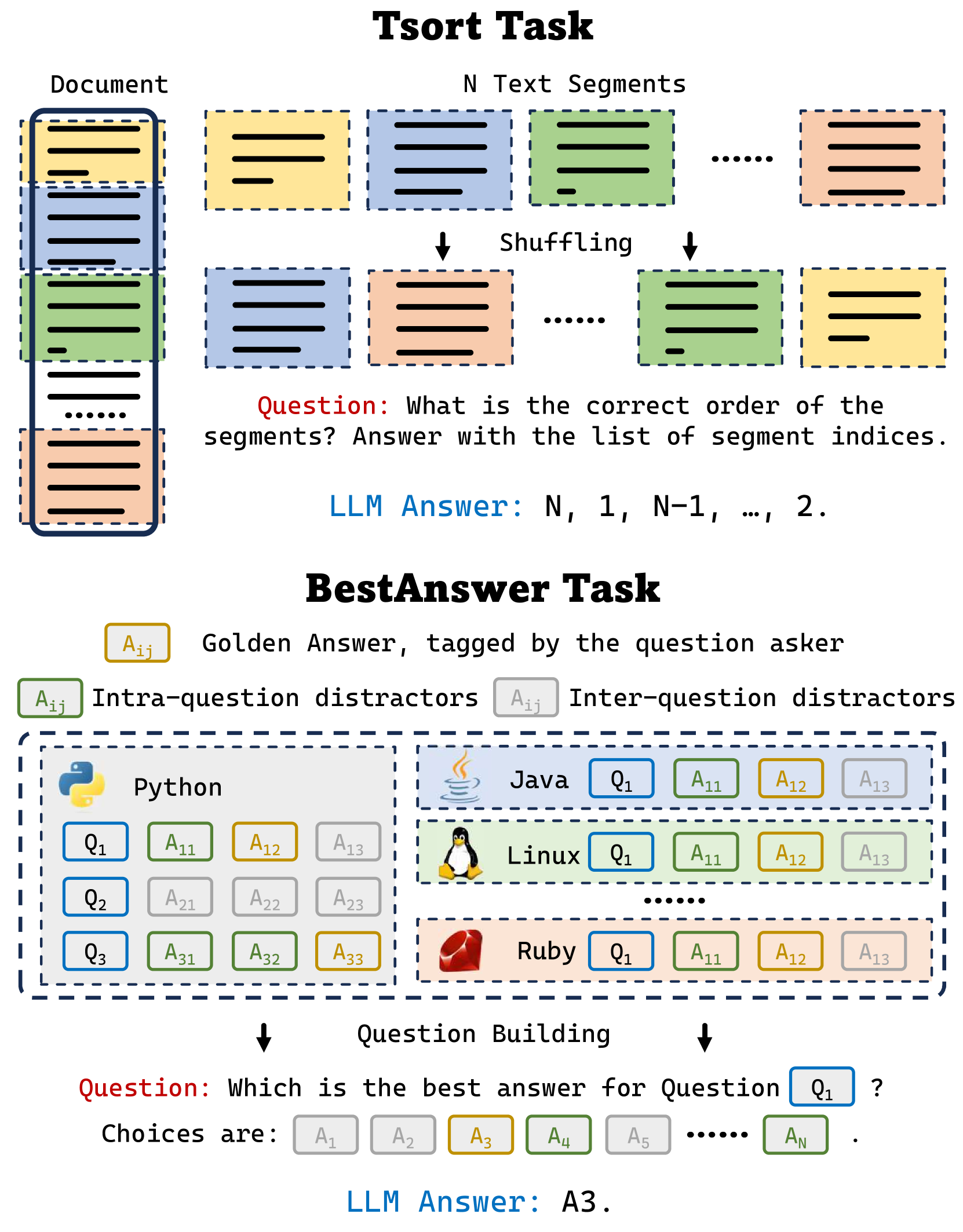
Recently, the large language model (LLM) community has shown increasing interest in enhancing LLMs' capability to handle extremely long documents. As various long-text techniques and model architectures emerge, the precise and detailed evaluation of models' long-text capabilities has become increasingly important. Existing long-text evaluation benchmarks, such as L-Eval and LongBench, construct long-text test sets based on open-source datasets, focusing mainly on QA and summarization tasks. These datasets include test samples of varying lengths (from 2k to 32k+) entangled together, making it challenging to assess model capabilities across different length ranges. Moreover, they do not cover the ultralong settings (100k+ tokens) that the latest LLMs claim to achieve. In this paper, we introduce Ada-LEval, a length-adaptable benchmark for evaluating the long-context understanding of LLMs. Ada-LEval includes two challenging subsets, TSort and BestAnswer, which enable a more reliable evaluation of LLMs' long context capabilities. These benchmarks support intricate manipulation of the length of test cases, and can easily produce text samples up to 128k tokens. We evaluate 4 state-of-the-art closed-source API models and 6 open-source models with Ada-LEval. The evaluation results demonstrate the limitations of current LLMs, especially in ultra-long-context settings. Our code is available at https://github.com/open-compass/Ada-LEval.
4/11/2024