LoFormer: Local Frequency Transformer for Image Deblurring

0

Sign in to get full access
Overview
- LoFormer is a novel deep learning model for image deblurring that leverages local frequency-domain information.
- It combines self-attention mechanisms with frequency-domain processing to effectively capture and restore blurry image details.
- The model exhibits state-of-the-art performance on several image deblurring benchmarks.
Plain English Explanation
Image deblurring is the process of restoring a clear, sharp image from one that has been blurred, often due to camera shake or object movement during capture. LoFormer is a new deep learning approach that tackles this problem by combining two powerful techniques:
-
Self-Attention: LoFormer uses self-attention mechanisms, which allow the model to intelligently focus on the most relevant parts of the image when trying to remove the blur. This helps it better understand the overall context and structure of the image.
-
Frequency-Domain Processing: In addition to working in the standard pixel space, LoFormer also analyzes the image in the frequency domain. This allows it to identify and restore high-frequency details that are often lost in blurry images, leading to sharper, more detailed results.
By bringing these two elements together, LoFormer is able to achieve state-of-the-art performance on benchmark image deblurring datasets. The model can effectively remove blur from a variety of scenes and image types, making it a powerful tool for improving the quality of photos and videos.
Technical Explanation
LoFormer is built upon the success of transformer-based models for computer vision tasks. The paper proposes a novel architecture that combines self-attention with frequency-domain processing to tackle the image deblurring problem.
The key components of LoFormer include:
-
Local Frequency Encoding: LoFormer first transforms the input image into the frequency domain using a 2D Discrete Fourier Transform (DFT). This allows the model to explicitly capture high-frequency details that are often lost in blurry images.
-
Frequency-Aware Self-Attention: The model then applies self-attention mechanisms to the frequency-domain representation, enabling it to focus on the most relevant frequency components when restoring the image.
-
Frequency-to-Spatial Reconstruction: Finally, LoFormer applies an inverse DFT to transform the processed frequency-domain representation back into the spatial domain, producing the final deblurred output.
The authors demonstrate the effectiveness of LoFormer through extensive experiments on several image deblurring benchmarks, where it outperforms other state-of-the-art methods. The model's ability to leverage both spatial and frequency-domain information is a key factor in its strong performance.
Critical Analysis
The LoFormer paper presents a well-designed and thoroughly evaluated approach to image deblurring. The authors have made several important contributions:
-
Innovative Architecture: The combination of self-attention and frequency-domain processing is a novel and promising direction for image restoration tasks like deblurring.
-
State-of-the-Art Performance: LoFormer achieves impressive results on benchmark datasets, demonstrating its practical value for real-world applications.
However, the paper also raises a few points for further consideration:
-
Computational Complexity: While the authors claim LoFormer is efficient, the use of Fourier transforms and self-attention mechanisms may still impose a significant computational burden, especially for high-resolution images. Further optimizations may be necessary for deployment in resource-constrained settings.
-
Generalization Capabilities: The paper focuses on evaluating LoFormer on standard deblurring benchmarks. It would be helpful to see how the model performs on more diverse or challenging real-world scenarios, such as extreme blur conditions or varying blur kernels.
-
Interpretability: As with many deep learning models, the inner workings of LoFormer may be difficult to interpret. Additional analysis of the model's attention patterns and frequency-domain processing could provide valuable insights into its deblurring capabilities.
Overall, LoFormer represents an important step forward in the field of image deblurring, and the authors have presented a well-executed and impactful piece of research. Further exploration of the model's strengths, limitations, and broader applications could lead to even more significant advancements in this area.
Conclusion
LoFormer is a novel deep learning model that combines self-attention and frequency-domain processing to achieve state-of-the-art performance in image deblurring. By explicitly capturing and restoring high-frequency details, LoFormer is able to produce sharper, more detailed results compared to previous approaches.
The paper's innovative architecture and strong experimental results make LoFormer a promising contribution to the field of image restoration. While there are some areas for further exploration, such as computational efficiency and generalization capabilities, LoFormer represents an important step forward in developing practical and effective solutions for real-world deblurring challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LoFormer: Local Frequency Transformer for Image Deblurring
Xintian Mao, Jiansheng Wang, Xingran Xie, Qingli Li, Yan Wang
Due to the computational complexity of self-attention (SA), prevalent techniques for image deblurring often resort to either adopting localized SA or employing coarse-grained global SA methods, both of which exhibit drawbacks such as compromising global modeling or lacking fine-grained correlation. In order to address this issue by effectively modeling long-range dependencies without sacrificing fine-grained details, we introduce a novel approach termed Local Frequency Transformer (LoFormer). Within each unit of LoFormer, we incorporate a Local Channel-wise SA in the frequency domain (Freq-LC) to simultaneously capture cross-covariance within low- and high-frequency local windows. These operations offer the advantage of (1) ensuring equitable learning opportunities for both coarse-grained structures and fine-grained details, and (2) exploring a broader range of representational properties compared to coarse-grained global SA methods. Additionally, we introduce an MLP Gating mechanism complementary to Freq-LC, which serves to filter out irrelevant features while enhancing global learning capabilities. Our experiments demonstrate that LoFormer significantly improves performance in the image deblurring task, achieving a PSNR of 34.09 dB on the GoPro dataset with 126G FLOPs. https://github.com/DeepMed-Lab-ECNU/Single-Image-Deblur
Read more7/25/2024

0
F2former: When Fractional Fourier Meets Deep Wiener Deconvolution and Selective Frequency Transformer for Image Deblurring
Subhajit Paul, Sahil Kumawat, Ashutosh Gupta, Deepak Mishra
Recent progress in image deblurring techniques focuses mainly on operating in both frequency and spatial domains using the Fourier transform (FT) properties. However, their performance is limited due to the dependency of FT on stationary signals and its lack of capability to extract spatial-frequency properties. In this paper, we propose a novel approach based on the Fractional Fourier Transform (FRFT), a unified spatial-frequency representation leveraging both spatial and frequency components simultaneously, making it ideal for processing non-stationary signals like images. Specifically, we introduce a Fractional Fourier Transformer (F2former), where we combine the classical fractional Fourier based Wiener deconvolution (F2WD) as well as a multi-branch encoder-decoder transformer based on a new fractional frequency aware transformer block (F2TB). We design F2TB consisting of a fractional frequency aware self-attention (F2SA) to estimate element-wise product attention based on important frequency components and a novel feed-forward network based on frequency division multiplexing (FM-FFN) to refine high and low frequency features separately for efficient latent clear image restoration. Experimental results for the cases of both motion deblurring as well as defocus deblurring show that the performance of our proposed method is superior to other state-of-the-art (SOTA) approaches.
Read more9/4/2024
🖼️
0
DEFormer: DCT-driven Enhancement Transformer for Low-light Image and Dark Vision
Xiangchen Yin, Zhenda Yu, Xin Gao, Xiao Sun
Low-light image enhancement restores colors and details of single image and improves high-level visual tasks. However, restoring the lost details in the dark area is a challenge by only relying on the RGB domain. In this paper, we introduce frequency as a new clue into the network and propose a DCT-driven enhancement transformer (DEFormer) framework. First, we propose a learnable frequency branch (LFB) for frequency enhancement contains DCT processing and curvature-based frequency enhancement (CFE) to represent frequency features. In addition, we propose a cross domain fusion (CDF) for reducing the differences between the RGB domain and the frequency domain. Our DEFormer has achieved advanced results in both the LOL and MIT-Adobe FiveK datasets and improved the performance of dark detection.
Read more9/10/2024
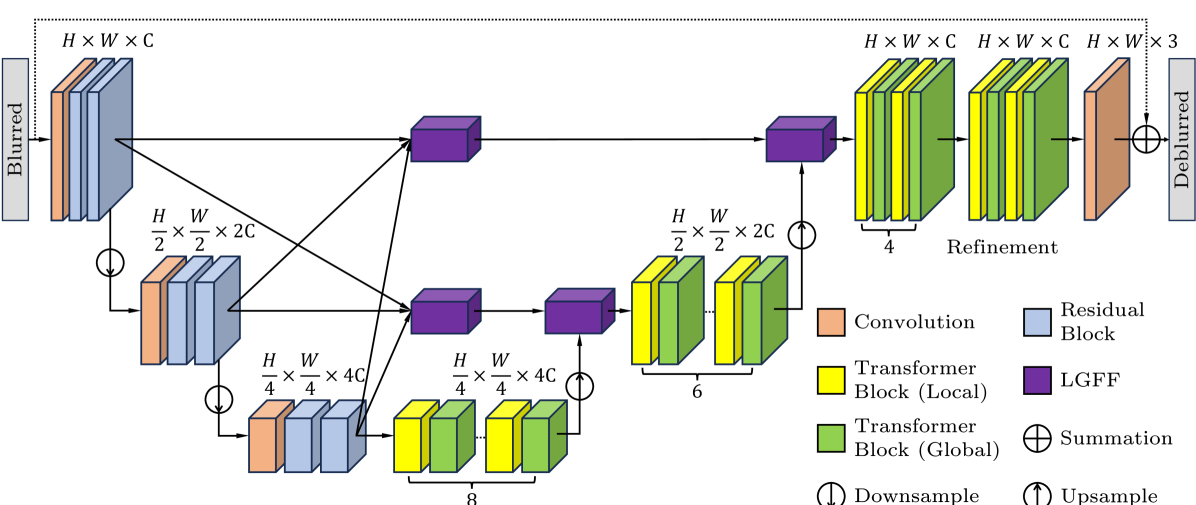
0
DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring
Hanzhou Liu, Binghan Li, Chengkai Liu, Mi Lu
Although prior state-of-the-art (SOTA) deblurring networks achieve high metric scores on synthetic datasets, there are two challenges which prevent them from perceptual image deblurring. First, a deblurring model overtrained on synthetic datasets may collapse in a broad range of unseen real-world scenarios. Second, the conventional metrics PSNR and SSIM may not correctly reflect the perceptual quality observed by human eyes. To this end, we propose DeblurDiNAT, a generalizable and efficient encoder-decoder Transformer which restores clean images visually close to the ground truth. We adopt an alternating dilation factor structure to capture local and global blur patterns. We propose a local cross-channel learner to assist self-attention layers to learn short-range cross-channel relationships. In addition, we present a linear feed-forward network and a non-linear dual-stage feature fusion module for faster feature propagation across the network. Compared to nearest competitors, our model demonstrates the strongest generalization ability and achieves the best perceptual quality on mainstream image deblurring datasets with 3%-68% fewer parameters.
Read more7/12/2024