Logistic Variational Bayes Revisited

0
Sign in to get full access
Overview
- The paper "Logistic Variational Bayes Revisited" explores improvements to the Logistic Variational Bayes (LVB) method, a technique used for Bayesian inference in logistic regression models.
- The authors propose several enhancements to the standard LVB approach, aiming to address some of its limitations and improve its performance.
- Key contributions include new algorithms for optimizing the variational lower bound, strategies for adjusting the variance of the variational distribution, and methods for handling high-dimensional data.
Plain English Explanation
In machine learning, researchers often use Bayesian inference to make predictions and draw conclusions from data. One popular Bayesian technique is called logistic regression, which is useful for modeling binary outcomes like whether a customer will buy a product or not.
The Logistic Variational Bayes (LVB) method is a way to do Bayesian inference for logistic regression models. It works by approximating the true posterior distribution with a simpler, more manageable distribution. This makes the computations easier and faster.
However, the standard LVB approach has some drawbacks. The authors of this paper propose several improvements to address these limitations:
-
New optimization algorithms: The authors develop new ways to efficiently optimize the variational lower bound, which is a key part of the LVB method. This helps the algorithm converge faster and find better solutions.
-
Variance adjustment: The authors introduce strategies for automatically adjusting the variance of the variational distribution. This can improve the accuracy of the approximation and lead to better predictions.
-
High-dimensional data: The authors also present methods for handling high-dimensional data, which is important for real-world applications where there are many input variables. Their techniques help the LVB approach scale better to large datasets.
By incorporating these improvements, the authors aim to make the LVB method more robust, efficient, and practical for a wider range of machine learning problems.
Technical Explanation
The paper "Logistic Variational Bayes Revisited" focuses on enhancing the Logistic Variational Bayes (LVB) method, a technique for performing Bayesian inference in logistic regression models.
The authors propose several key contributions:
-
New optimization algorithms: The authors introduce novel optimization algorithms for maximizing the variational lower bound (ELBO) in the LVB framework. These algorithms, which include a Rao-Blackwellized stochastic gradient ascent method and a Riemannian trust-region approach, are designed to improve the convergence rate and solution quality compared to standard methods.
-
Variance adjustment: To address the challenges of correctly specifying the variance of the variational distribution, the authors develop strategies for automatically adjusting the variance during the optimization process. This includes using a Stein variational gradient descent approach and a novel variance adaptation scheme.
-
High-dimensional data: For applications with high-dimensional input features, the authors propose extensions to the LVB method that can effectively handle such scenarios. This includes using Manifold Gaussian Variational Bayes to model the precision matrix and exploiting the sparse structure of the problem.
Through extensive experiments, the authors demonstrate that their proposed enhancements can significantly improve the performance of the LVB method, leading to better predictive accuracy and faster convergence compared to the standard approach.
Critical Analysis
The paper makes several valuable contributions to improving the Logistic Variational Bayes (LVB) method, addressing important limitations and expanding its capabilities. The authors' focus on optimization algorithms, variance adjustment, and handling high-dimensional data are well-motivated and represent meaningful advancements in the field.
However, the paper does not provide a comprehensive evaluation of the proposed techniques across a wide range of datasets and problem settings. While the experimental results are promising, it would be helpful to see a more extensive comparison to alternative Bayesian logistic regression methods, such as Markov Chain Monte Carlo (MCMC) techniques, to better assess the relative merits and limitations of the LVB approach.
Additionally, the paper does not delve deeply into the potential drawbacks or caveats of the LVB method, even with the proposed enhancements. For example, the authors could have discussed the sensitivity of the method to hyperparameter choices, the impact of model misspecification, or the computational trade-offs involved in the various optimization algorithms.
Overall, the paper presents a solid step forward in improving the LVB method, but there is still room for further research and exploration, especially in terms of a more thorough evaluation and a deeper understanding of the method's strengths, weaknesses, and applicable domains.
Conclusion
The paper "Logistic Variational Bayes Revisited" introduces several key enhancements to the Logistic Variational Bayes (LVB) method, a technique used for Bayesian inference in logistic regression models. The authors propose new optimization algorithms, variance adjustment strategies, and extensions for handling high-dimensional data, all with the goal of improving the performance and practical applicability of the LVB approach.
The experimental results demonstrate the effectiveness of the proposed improvements, suggesting that the enhanced LVB method can outperform the standard approach in terms of predictive accuracy and convergence speed. These advancements represent a significant step forward in making Bayesian logistic regression more robust and efficient, which could have important implications for a wide range of real-world machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Logistic Variational Bayes Revisited
Michael Komodromos, Marina Evangelou, Sarah Filippi
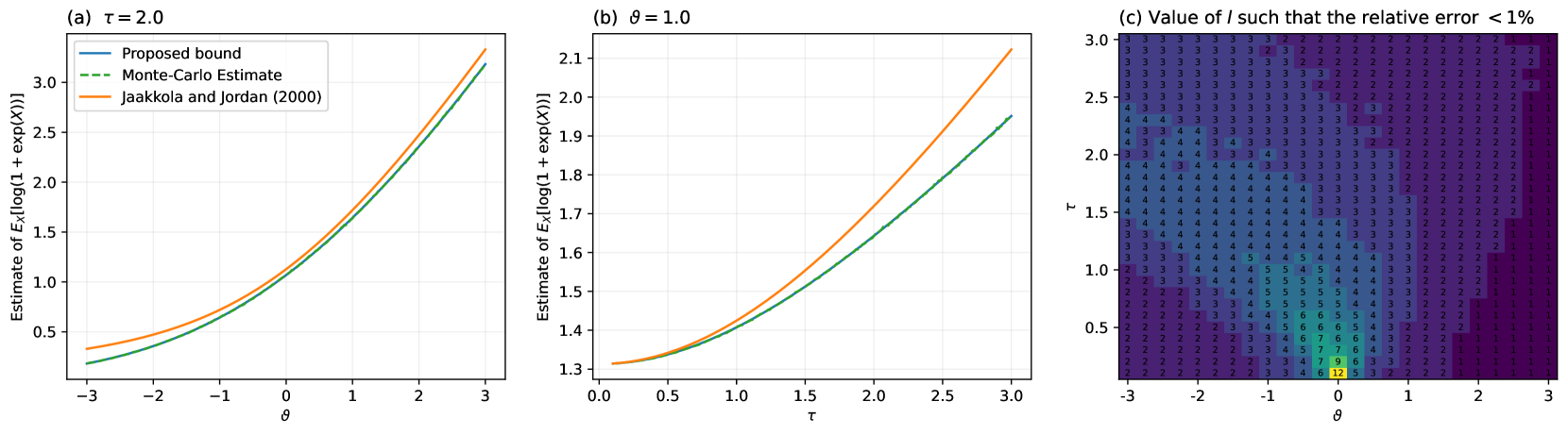
Variational logistic regression is a popular method for approximate Bayesian inference seeing wide-spread use in many areas of machine learning including: Bayesian optimization, reinforcement learning and multi-instance learning to name a few. However, due to the intractability of the Evidence Lower Bound, authors have turned to the use of Monte Carlo, quadrature or bounds to perform inference, methods which are costly or give poor approximations to the true posterior. In this paper we introduce a new bound for the expectation of softplus function and subsequently show how this can be applied to variational logistic regression and Gaussian process classification. Unlike other bounds, our proposal does not rely on extending the variational family, or introducing additional parameters to ensure the bound is tight. In fact, we show that this bound is tighter than the state-of-the-art, and that the resulting variational posterior achieves state-of-the-art performance, whilst being significantly faster to compute than Monte-Carlo methods.
Read more6/4/2024
🤔
0
Variational inference, Mixture of Gaussians, Bayesian Machine Learning
Tom Huix, Anna Korba, Alain Durmus, Eric Moulines
Variational inference (VI) is a popular approach in Bayesian inference, that looks for the best approximation of the posterior distribution within a parametric family, minimizing a loss that is typically the (reverse) Kullback-Leibler (KL) divergence. Despite its empirical success, the theoretical properties of VI have only received attention recently, and mostly when the parametric family is the one of Gaussians. This work aims to contribute to the theoretical study of VI in the non-Gaussian case by investigating the setting of Mixture of Gaussians with fixed covariance and constant weights. In this view, VI over this specific family can be casted as the minimization of a Mollified relative entropy, i.e. the KL between the convolution (with respect to a Gaussian kernel) of an atomic measure supported on Diracs, and the target distribution. The support of the atomic measure corresponds to the localization of the Gaussian components. Hence, solving variational inference becomes equivalent to optimizing the positions of the Diracs (the particles), which can be done through gradient descent and takes the form of an interacting particle system. We study two sources of error of variational inference in this context when optimizing the mollified relative entropy. The first one is an optimization result, that is a descent lemma establishing that the algorithm decreases the objective at each iteration. The second one is an approximation error, that upper bounds the objective between an optimal finite mixture and the target distribution.
Read more6/11/2024
🤯
0
Variational Bayesian surrogate modelling with application to robust design optimisation
Thomas A. Archbold, Ieva Kazlauskaite, Fehmi Cirak
Surrogate models provide a quick-to-evaluate approximation to complex computational models and are essential for multi-query problems like design optimisation. The inputs of current computational models are usually high-dimensional and uncertain. We consider Bayesian inference for constructing statistical surrogates with input uncertainties and intrinsic dimensionality reduction. The surrogates are trained by fitting to data from prevalent deterministic computational models. The assumed prior probability density of the surrogate is a Gaussian process. We determine the respective posterior probability density and parameters of the posited statistical model using variational Bayes. The non-Gaussian posterior is approximated by a simpler trial density with free variational parameters and the discrepancy between them is measured using the Kullback-Leibler (KL) divergence. We employ the stochastic gradient method to compute the variational parameters and other statistical model parameters by minimising the KL divergence. We demonstrate the accuracy and versatility of the proposed reduced dimension variational Gaussian process (RDVGP) surrogate on illustrative and robust structural optimisation problems with cost functions depending on a weighted sum of the mean and standard deviation of model outputs.
Read more4/24/2024

0
A variational Bayes approach to debiased inference for low-dimensional parameters in high-dimensional linear regression
Ismael Castillo, Alice L'Huillier, Kolyan Ray, Luke Travis
We propose a scalable variational Bayes method for statistical inference for a single or low-dimensional subset of the coordinates of a high-dimensional parameter in sparse linear regression. Our approach relies on assigning a mean-field approximation to the nuisance coordinates and carefully modelling the conditional distribution of the target given the nuisance. This requires only a preprocessing step and preserves the computational advantages of mean-field variational Bayes, while ensuring accurate and reliable inference for the target parameter, including for uncertainty quantification. We investigate the numerical performance of our algorithm, showing that it performs competitively with existing methods. We further establish accompanying theoretical guarantees for estimation and uncertainty quantification in the form of a Bernstein--von Mises theorem.
Read more6/19/2024