Loki: A System for Serving ML Inference Pipelines with Hardware and Accuracy Scaling

0

Sign in to get full access
Overview
- Loki is a system for serving machine learning (ML) inference pipelines.
- It allows for hardware and accuracy scaling to meet the needs of different applications.
- Loki addresses challenges in managing the complexity of ML inference pipelines and scaling them efficiently.
Plain English Explanation
Loki is a tool that helps run machine learning models for real-world applications. Machine learning models are programs that can make predictions or decisions based on data. However, running these models can be complex, especially when you need to run multiple models together (called an "inference pipeline") and scale the hardware resources to handle different workloads.
Loki simplifies this process by providing a system that can automatically adjust the hardware resources (like CPUs and GPUs) and the accuracy of the machine learning models to match the needs of the application. For example, if an application needs very fast but slightly less accurate results, Loki can provision more powerful hardware to meet that need. Or if an application can tolerate slower but more accurate results, Loki can adjust the models accordingly.
This flexibility allows developers to focus on building their applications without having to worry as much about the underlying infrastructure and performance tradeoffs. Loki handles those details automatically, making it easier to deploy and scale machine learning systems in the real world.
Technical Explanation
Loki is designed to address the challenges of managing and scaling ML inference pipelines. These pipelines involve multiple machine learning models executing in sequence to produce a final output. Loki provides capabilities for:
- Hardware Scaling: Loki can dynamically provision the appropriate hardware resources (CPUs, GPUs, etc.) to meet the performance needs of the inference pipeline.
- Accuracy Scaling: Loki can also adjust the accuracy of the machine learning models within the pipeline, trading off accuracy for faster inference when appropriate.
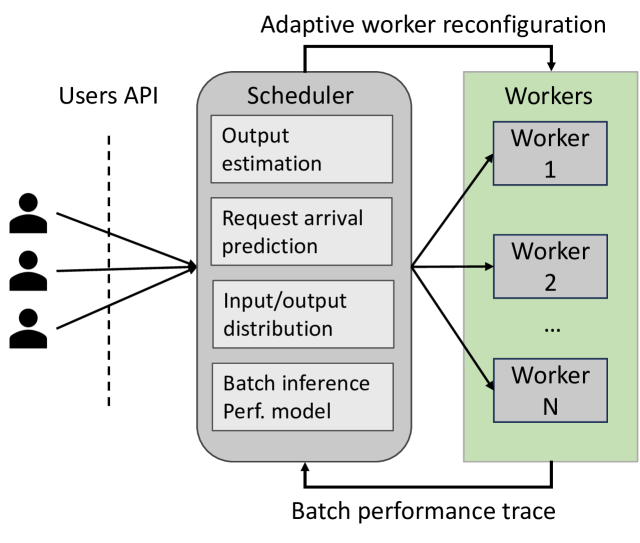
Loki's architecture includes a central controller that manages the lifecycle of inference pipelines. The controller monitors metrics like latency and throughput, and uses optimization algorithms to determine the best hardware configuration and model accuracy settings to meet the application's requirements.
The paper describes experiments demonstrating Loki's ability to scale inference pipelines across diverse workloads, while maintaining the required performance and accuracy targets. The results show that Loki can significantly improve resource efficiency compared to static provisioning approaches.
Critical Analysis
The Loki paper provides a compelling approach to the challenge of serving complex ML inference pipelines in production environments. By introducing the ability to dynamically scale both hardware resources and model accuracy, Loki offers a flexible solution to meet the needs of a wide range of applications.
One potential limitation is the reliance on the central controller, which could introduce a single point of failure or performance bottleneck at scale. The paper acknowledges this concern and suggests distributed control architectures as an area for future work.
Additionally, the accuracy scaling mechanism relies on pre-defined accuracy-performance tradeoff models for each component model in the pipeline. Developing and maintaining these models could be a significant effort, especially for rapidly evolving ML models. Techniques for automatically learning these tradeoff models could further improve Loki's usability and applicability.
Overall, Loki presents an important step forward in the quest to make machine learning more accessible and scalable in real-world settings. By addressing key challenges around infrastructure management and performance optimization, Loki and similar systems can help unlock the transformative potential of AI across a wide range of industries and applications.
Conclusion
Loki is a system that simplifies the deployment and scaling of machine learning inference pipelines. By providing the ability to dynamically adjust hardware resources and model accuracy, Loki helps developers focus on building applications without worrying as much about the underlying infrastructure.
The technical innovations in Loki, such as its central controller and optimization algorithms, demonstrate how research progress can make machine learning more accessible and usable in real-world scenarios. As the field of AI continues to advance, systems like Loki will play an increasingly important role in bridging the gap between cutting-edge research and practical, large-scale applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Loki: A System for Serving ML Inference Pipelines with Hardware and Accuracy Scaling
Sohaib Ahmad, Hui Guan, Ramesh K. Sitaraman
The rapid adoption of machine learning (ML) has underscored the importance of serving ML models with high throughput and resource efficiency. Traditional approaches to managing increasing query demands have predominantly focused on hardware scaling, which involves increasing server count or computing power. However, this strategy can often be impractical due to limitations in the available budget or compute resources. As an alternative, accuracy scaling offers a promising solution by adjusting the accuracy of ML models to accommodate fluctuating query demands. Yet, existing accuracy scaling techniques target independent ML models and tend to underperform while managing inference pipelines. Furthermore, they lack integration with hardware scaling, leading to potential resource inefficiencies during low-demand periods. To address the limitations, this paper introduces Loki, a system designed for serving inference pipelines effectively with both hardware and accuracy scaling. Loki incorporates an innovative theoretical framework for optimal resource allocation and an effective query routing algorithm, aimed at improving system accuracy and minimizing latency deadline violations. Our empirical evaluation demonstrates that through accuracy scaling, the effective capacity of a fixed-size cluster can be enhanced by more than $2.7times$ compared to relying solely on hardware scaling. When compared with state-of-the-art inference-serving systems, Loki achieves up to a $10times$ reduction in Service Level Objective (SLO) violations, with minimal compromises on accuracy and while fulfilling throughput demands.
Read more7/8/2024
0
Aladdin: Joint Placement and Scaling for SLO-Aware LLM Serving
Chengyi Nie, Rodrigo Fonseca, Zhenhua Liu
The demand for large language model (LLM) inference is gradually dominating the artificial intelligence workloads. Therefore, there is an urgent need for cost-efficient inference serving. Existing work focuses on single-worker optimization and lacks consideration of cluster-level management for both inference queries and computing resources. However, placing requests and managing resources without considering the query features easily causes SLO violations or resource underutilization. Providers are forced to allocate extra computing resources to guarantee user experience, leading to additional serving costs. In this paper we introduce Aladdin, a scheduler that co-adaptively places queries and scales computing resources with SLO awareness. For a stream of inference queries, Aladdin first predicts minimal computing resources and the corresponding serving workers' configuration required to fulfill the SLOs for all queries. Then, it places the queries to each serving worker according to the prefill and decode latency models of batched LLM inference to maximize each worker's utilization. Results show that Aladdin reduces the serving cost of a single model by up to 71% for the same SLO level compared with the baselines, which can be millions of dollars per year.
Read more5/14/2024

0
A Tale of Two Scales: Reconciling Horizontal and Vertical Scaling for Inference Serving Systems
Kamran Razavi, Mehran Salmani, Max Muhlhauser, Boris Koldehofe, Lin Wang
Inference serving is of great importance in deploying machine learning models in real-world applications, ensuring efficient processing and quick responses to inference requests. However, managing resources in these systems poses significant challenges, particularly in maintaining performance under varying and unpredictable workloads. Two primary scaling strategies, horizontal and vertical scaling, offer different advantages and limitations. Horizontal scaling adds more instances to handle increased loads but can suffer from cold start issues and increased management complexity. Vertical scaling boosts the capacity of existing instances, allowing for quicker responses but is limited by hardware and model parallelization capabilities. This paper introduces Themis, a system designed to leverage the benefits of both horizontal and vertical scaling in inference serving systems. Themis employs a two-stage autoscaling strategy: initially using in-place vertical scaling to handle workload surges and then switching to horizontal scaling to optimize resource efficiency once the workload stabilizes. The system profiles the processing latency of deep learning models, calculates queuing delays, and employs different dynamic programming algorithms to solve the joint horizontal and vertical scaling problem optimally based on the workload situation. Extensive evaluations with real-world workload traces demonstrate over $10times$ SLO violation reduction compared to the state-of-the-art horizontal or vertical autoscaling approaches while maintaining resource efficiency when the workload is stable.
Read more7/23/2024

0
SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavaroutsos, Sotirios Xydis, Dimitrios Soudris
As Large Language Models (LLMs) gain traction, their reliance on power-hungry GPUs places ever-increasing energy demands, raising environmental and monetary concerns. Inference dominates LLM workloads, presenting a critical challenge for providers: minimizing energy costs under Service-Level Objectives (SLOs) that ensure optimal user experience. In this paper, we present textit{throttLL'eM}, a framework that reduces energy consumption while meeting SLOs through the use of instance and GPU frequency scaling. textit{throttLL'eM} features mechanisms that project future KV cache usage and batch size. Leveraging a Machine-Learning (ML) model that receives these projections as inputs, textit{throttLL'eM} manages performance at the iteration level to satisfy SLOs with reduced frequencies and instance sizes. We show that the proposed ML model achieves $R^2$ scores greater than 0.97 and miss-predicts performance by less than 1 iteration per second on average. Experimental results on LLM inference traces show that textit{throttLL'eM} achieves up to 43.8% lower energy consumption and an energy efficiency improvement of at least $1.71times$ under SLOs, when compared to NVIDIA's Triton server.
Read more8/13/2024