A Tale of Two Scales: Reconciling Horizontal and Vertical Scaling for Inference Serving Systems

0

Sign in to get full access
Overview
- Reconciles horizontal and vertical scaling for machine learning inference serving systems
- Explores the trade-offs between scaling up (adding more resources to a single server) and scaling out (adding more servers)
- Proposes a system that dynamically adjusts the balance between horizontal and vertical scaling based on workload characteristics and resource availability
Plain English Explanation
In the world of machine learning, there are two main ways to scale up the performance of your inference serving systems: horizontal scaling and vertical scaling. Horizontal scaling means adding more servers, while vertical scaling means adding more resources (like CPU, memory, etc.) to a single server.
Each approach has its own pros and cons. Horizontal scaling allows you to handle more overall workload, but it can be more complex to manage. Vertical scaling is simpler, but has limits on how much you can scale up a single server.
This paper proposes a system that dynamically adjusts the balance between horizontal and vertical scaling based on the characteristics of the workload and the available resources. For example, if you have a workload that is very CPU-intensive, the system might decide to scale up a few servers with more powerful CPUs rather than adding a bunch of smaller servers. Or if you have a more memory-intensive workload, it might scale out horizontally to use more servers with more memory.
The key idea is to try to find the right mix of horizontal and vertical scaling to optimize performance and efficiency, rather than just relying on one approach or the other. This can be particularly useful in cloud environments where resources are more dynamic and flexible.
Technical Explanation
The paper presents a system called ALADDIN that aims to reconcile horizontal and vertical scaling for machine learning inference serving. It introduces a model-driven approach to dynamically adjust the balance between horizontal and vertical scaling based on workload characteristics and resource availability.
The system architecture includes a SLO-aware placement and scaling module that makes decisions about how to scale the system. It takes into account factors like the resource requirements of the models being served, the current load, and the available compute resources.
The key innovation is a scaling strategy that considers both horizontal and vertical scaling options. It evaluates the trade-offs between the two approaches, looking at metrics like throughput, latency, and cost. Based on this analysis, it determines the optimal combination of horizontal and vertical scaling to meet the performance targets.
The system is evaluated on a variety of real-world machine learning workloads, including computer vision and natural language processing models. The results show that this hybrid scaling approach can outperform strategies that rely solely on horizontal or vertical scaling, especially in heterogeneous environments with diverse resource availability.
Critical Analysis
The paper provides a thoughtful analysis of the trade-offs between horizontal and vertical scaling, and presents a compelling approach to dynamically reconciling the two. However, there are a few potential limitations and areas for further research:
-
The evaluation is limited to a relatively narrow set of machine learning workloads. It would be valuable to see how the system performs on a wider range of applications, especially those with very different resource profiles.
-
The paper does not explore the full complexity of real-world cloud environments, such as the impacts of network latency, storage performance, or multi-tenancy. These factors could significantly influence the optimal scaling strategy.
-
The decision-making process for adjusting the horizontal/vertical balance is not fully transparent. More details on the underlying models and heuristics could help users understand and trust the system's choices.
-
The proposed system assumes the availability of accurate resource requirement predictions for the models being served. In practice, these estimates may be difficult to obtain, especially for complex models or dynamically changing workloads.
Despite these potential issues, the core concept of this paper is a valuable contribution to the field of inference serving systems. The ability to intelligently balance horizontal and vertical scaling is an important step towards more efficient and responsive machine learning deployments, especially in cloud-based environments.
Conclusion
This paper presents a novel approach to reconciling horizontal and vertical scaling for machine learning inference serving systems. By dynamically adjusting the balance between these two scaling strategies based on workload characteristics and resource availability, the proposed ALADDIN system can optimize performance and efficiency in a variety of deployment scenarios.
The key insights from this research could have significant implications for the design and operation of large-scale machine learning pipelines, particularly in cloud environments where resources are more flexible and heterogeneous. As machine learning continues to be adopted for an ever-widening range of applications, the ability to intelligently scale inference serving systems will become increasingly critical.
Overall, this paper makes a valuable contribution to the ongoing efforts to make machine learning more scalable, reliable, and cost-effective in real-world deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Tale of Two Scales: Reconciling Horizontal and Vertical Scaling for Inference Serving Systems
Kamran Razavi, Mehran Salmani, Max Muhlhauser, Boris Koldehofe, Lin Wang
Inference serving is of great importance in deploying machine learning models in real-world applications, ensuring efficient processing and quick responses to inference requests. However, managing resources in these systems poses significant challenges, particularly in maintaining performance under varying and unpredictable workloads. Two primary scaling strategies, horizontal and vertical scaling, offer different advantages and limitations. Horizontal scaling adds more instances to handle increased loads but can suffer from cold start issues and increased management complexity. Vertical scaling boosts the capacity of existing instances, allowing for quicker responses but is limited by hardware and model parallelization capabilities. This paper introduces Themis, a system designed to leverage the benefits of both horizontal and vertical scaling in inference serving systems. Themis employs a two-stage autoscaling strategy: initially using in-place vertical scaling to handle workload surges and then switching to horizontal scaling to optimize resource efficiency once the workload stabilizes. The system profiles the processing latency of deep learning models, calculates queuing delays, and employs different dynamic programming algorithms to solve the joint horizontal and vertical scaling problem optimally based on the workload situation. Extensive evaluations with real-world workload traces demonstrate over $10times$ SLO violation reduction compared to the state-of-the-art horizontal or vertical autoscaling approaches while maintaining resource efficiency when the workload is stable.
Read more7/23/2024

0
Loki: A System for Serving ML Inference Pipelines with Hardware and Accuracy Scaling
Sohaib Ahmad, Hui Guan, Ramesh K. Sitaraman
The rapid adoption of machine learning (ML) has underscored the importance of serving ML models with high throughput and resource efficiency. Traditional approaches to managing increasing query demands have predominantly focused on hardware scaling, which involves increasing server count or computing power. However, this strategy can often be impractical due to limitations in the available budget or compute resources. As an alternative, accuracy scaling offers a promising solution by adjusting the accuracy of ML models to accommodate fluctuating query demands. Yet, existing accuracy scaling techniques target independent ML models and tend to underperform while managing inference pipelines. Furthermore, they lack integration with hardware scaling, leading to potential resource inefficiencies during low-demand periods. To address the limitations, this paper introduces Loki, a system designed for serving inference pipelines effectively with both hardware and accuracy scaling. Loki incorporates an innovative theoretical framework for optimal resource allocation and an effective query routing algorithm, aimed at improving system accuracy and minimizing latency deadline violations. Our empirical evaluation demonstrates that through accuracy scaling, the effective capacity of a fixed-size cluster can be enhanced by more than $2.7times$ compared to relying solely on hardware scaling. When compared with state-of-the-art inference-serving systems, Loki achieves up to a $10times$ reduction in Service Level Objective (SLO) violations, with minimal compromises on accuracy and while fulfilling throughput demands.
Read more7/8/2024
🔮
0
TempoScale: A Cloud Workloads Prediction Approach Integrating Short-Term and Long-Term Information
Linfeng Wen, Minxian Xu, Adel N. Toosi, Kejiang Ye
Cloud native solutions are widely applied in various fields, placing higher demands on the efficient management and utilization of resource platforms. To achieve the efficiency, load forecasting and elastic scaling have become crucial technologies for dynamically adjusting cloud resources to meet user demands and minimizing resource waste. However, existing prediction-based methods lack comprehensive analysis and integration of load characteristics across different time scales. For instance, long-term trend analysis helps reveal long-term changes in load and resource demand, thereby supporting proactive resource allocation over longer periods, while short-term volatility analysis can examine short-term fluctuations in load and resource demand, providing support for real-time scheduling and rapid response. In response to this, our research introduces TempoScale, which aims to enhance the comprehensive understanding of temporal variations in cloud workloads, enabling more intelligent and adaptive decision-making for elastic scaling. TempoScale utilizes the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise algorithm to decompose time-series load data into multiple Intrinsic Mode Functions (IMF) and a Residual Component (RC). First, we integrate the IMF, which represents both long-term trends and short-term fluctuations, into the time series prediction model to obtain intermediate results. Then, these intermediate results, along with the RC, are transferred into a fully connected layer to obtain the final result. Finally, this result is fed into the resource management system based on Kubernetes for resource scaling. Our proposed approach can reduce the Mean Square Error by 5.80% to 30.43% compared to the baselines, and reduce the average response time by 5.58% to 31.15%.
Read more5/22/2024
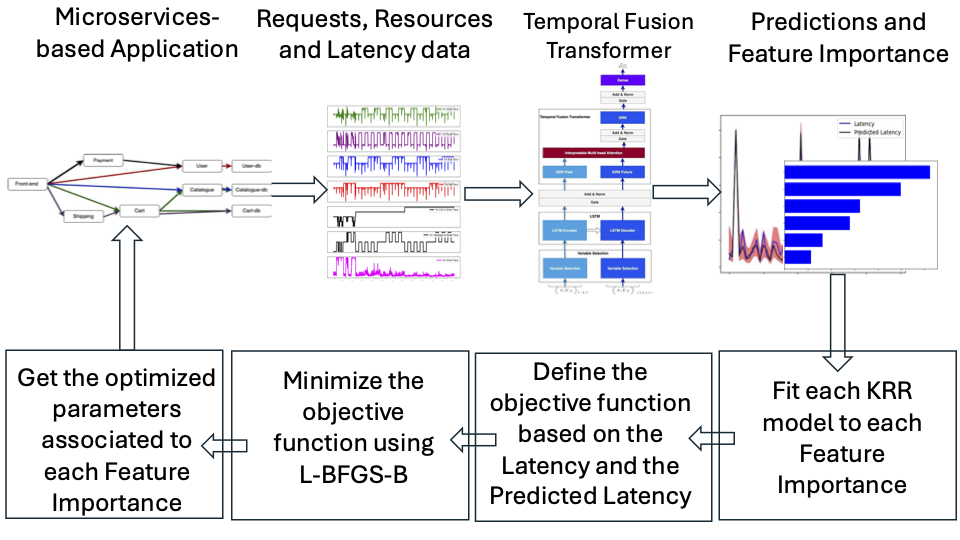
0
Leveraging Interpretability in the Transformer to Automate the Proactive Scaling of Cloud Resources
Amadou Ba, Pavithra Harsha, Chitra Subramanian
Modern web services adopt cloud-native principles to leverage the advantages of microservices. To consistently guarantee high Quality of Service (QoS) according to Service Level Agreements (SLAs), ensure satisfactory user experiences, and minimize operational costs, each microservice must be provisioned with the right amount of resources. However, accurately provisioning microservices with adequate resources is complex and depends on many factors, including workload intensity and the complex interconnections between microservices. To address this challenge, we develop a model that captures the relationship between an end-to-end latency, requests at the front-end level, and resource utilization. We then use the developed model to predict the end-to-end latency. Our solution leverages the Temporal Fusion Transformer (TFT), an attention-based architecture equipped with interpretability features. When the prediction results indicate SLA non-compliance, we use the feature importance provided by the TFT as covariates in Kernel Ridge Regression (KRR), with the response variable being the desired latency, to learn the parameters associated with the feature importance. These learned parameters reflect the adjustments required to the features to ensure SLA compliance. We demonstrate the merit of our approach with a microservice-based application and provide a roadmap to deployment.
Read more9/6/2024