Long Code Arena: a Set of Benchmarks for Long-Context Code Models

0
🚀
Sign in to get full access
Overview
- This paper introduces the "Long Code Arena," a set of benchmarks designed to evaluate the performance of large language models (LLMs) on long-context code understanding and generation tasks.
- The benchmarks cover a range of programming languages, task types, and levels of code complexity to assess the capabilities of LLMs in real-world coding scenarios.
- The authors argue that current code evaluation benchmarks are limited in their scope and do not adequately test the long-context reasoning abilities of LLMs, which are essential for many programming tasks.
Plain English Explanation
The paper presents a new set of benchmarks called the "Long Code Arena" that are designed to assess how well large language models (LLMs) can understand and generate code in long-context scenarios. LLMs are a type of AI model that can generate human-like text, including code.
Current code evaluation benchmarks often focus on short, isolated code snippets, but in real-world programming, developers often need to work with large, complex codebases that require understanding the broader context. The Long Code Arena aims to fill this gap by providing a more comprehensive set of tests that cover a variety of programming languages, task types, and levels of code complexity.
By testing LLMs on these more challenging, long-context scenarios, the researchers hope to better understand the capabilities and limitations of these models in practical coding applications. This could help guide the development of more effective LLMs for programming tasks. Similar efforts to benchmark LLMs on long-context tasks can be found in other research, such as RepoQA, MileBench, and LiveCodeBench.
Technical Explanation
The Long Code Arena consists of several benchmark tasks designed to evaluate the performance of LLMs on long-context code understanding and generation. The benchmarks cover a range of programming languages, including Python, Java, and C++, as well as different task types, such as code summarization, code completion, and code translation.
The key features of the Long Code Arena benchmarks are:
- Long-context codebase: Each task is based on a large, multi-file codebase, requiring the LLM to understand the broader context and relationships between different parts of the code.
- Diverse task types: The benchmarks include a variety of programming tasks, from generating code summaries to translating code between languages, to assess the versatility of the LLMs.
- Varying complexity levels: The codebases and tasks range in difficulty, from beginner-level to more advanced, to test the limits of the LLMs' capabilities.
The authors evaluate several state-of-the-art LLMs on the Long Code Arena benchmarks and provide detailed analysis of their performance. They find that while the LLMs show promising results, there is still significant room for improvement, especially on the more complex and long-context tasks.
Critical Analysis
The Long Code Arena benchmarks represent an important step forward in evaluating the long-context capabilities of LLMs for programming tasks. By focusing on more realistic and challenging scenarios, the benchmarks can help identify the current limitations of these models and guide future research and development.
However, the authors acknowledge that the benchmarks are not exhaustive and may not capture all the nuances of real-world programming. For example, the benchmarks do not currently test the LLMs' ability to handle dynamic code generation, code refactoring, or integration with development tools and workflows.
Additionally, the authors note that the performance of the LLMs on the benchmarks may be influenced by factors such as the quality and representativeness of the training data, the model architecture, and the fine-tuning process. Further research is needed to understand the underlying factors that contribute to the models' performance and to develop strategies for improving their long-context reasoning abilities.
Conclusion
The Long Code Arena benchmarks introduced in this paper represent a significant advancement in the evaluation of LLMs for programming tasks. By focusing on long-context scenarios, the benchmarks help expose the strengths and weaknesses of these models in real-world coding applications.
The results of the benchmark experiments suggest that while LLMs show promise, there is still much work to be done to improve their long-context reasoning and problem-solving capabilities. The insights gained from the Long Code Arena could inform the development of more effective LLMs for programming, with the ultimate goal of enhancing human-AI collaboration in software development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Long Code Arena: a Set of Benchmarks for Long-Context Code Models
Egor Bogomolov, Aleksandra Eliseeva, Timur Galimzyanov, Evgeniy Glukhov, Anton Shapkin, Maria Tigina, Yaroslav Golubev, Alexander Kovrigin, Arie van Deursen, Maliheh Izadi, Timofey Bryksin
Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
Read more6/18/2024
🤔
0
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, Juanzi Li
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.
Read more6/21/2024

1
Scaling Granite Code Models to 128K Context
Matt Stallone, Vaibhav Saxena, Leonid Karlinsky, Bridget McGinn, Tim Bula, Mayank Mishra, Adriana Meza Soria, Gaoyuan Zhang, Aditya Prasad, Yikang Shen, Saptha Surendran, Shanmukha Guttula, Hima Patel, Parameswaran Selvam, Xuan-Hong Dang, Yan Koyfman, Atin Sood, Rogerio Feris, Nirmit Desai, David D. Cox, Ruchir Puri, Rameswar Panda
This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
Read more7/19/2024
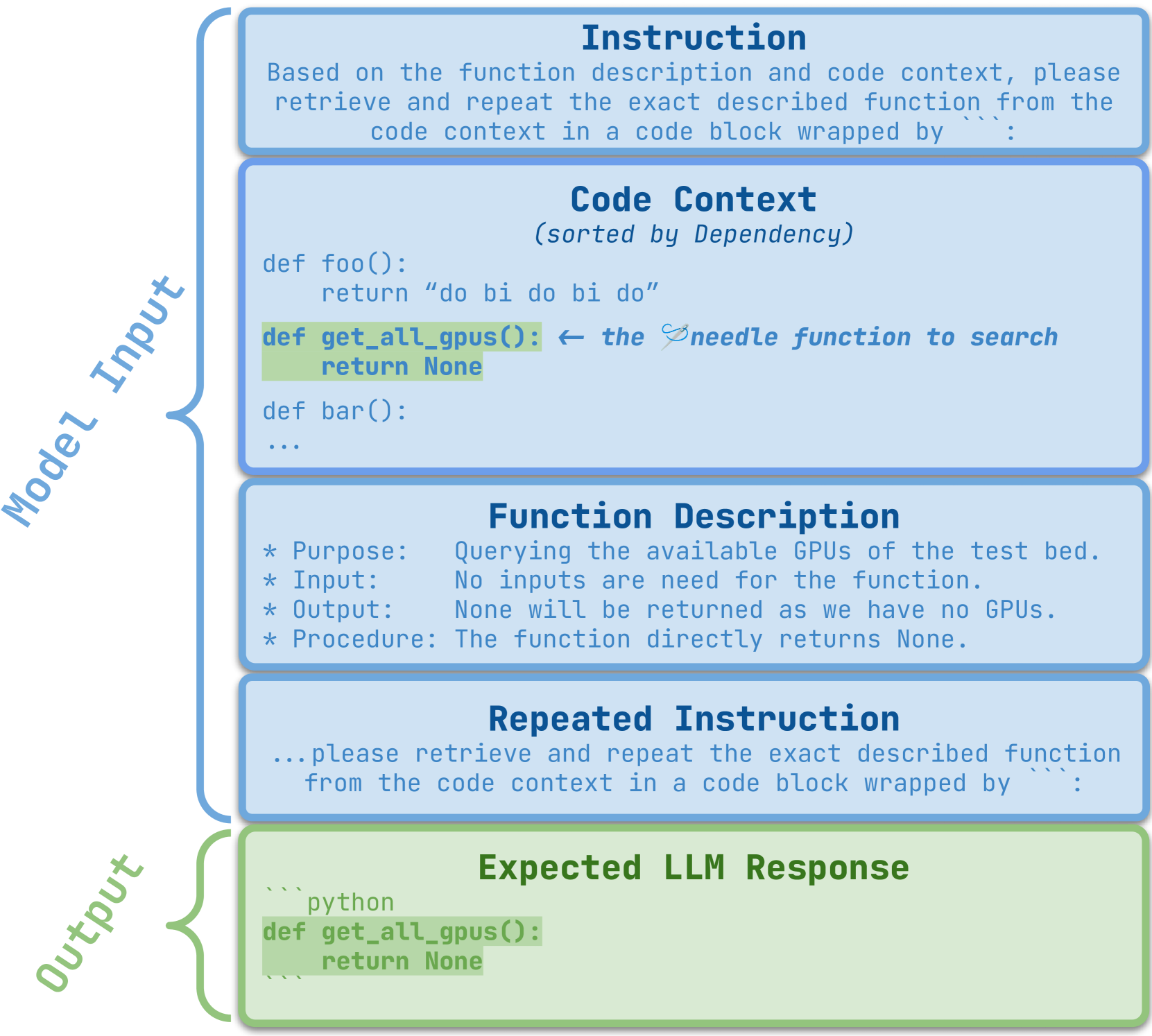
0
RepoQA: Evaluating Long Context Code Understanding
Jiawei Liu, Jia Le Tian, Vijay Daita, Yuxiang Wei, Yifeng Ding, Yuhan Katherine Wang, Jun Yang, Lingming Zhang
Recent advances have been improving the context windows of Large Language Models (LLMs). To quantify the real long-context capabilities of LLMs, evaluators such as the popular Needle in a Haystack have been developed to test LLMs over a large chunk of raw texts. While effective, current evaluations overlook the insight of how LLMs work with long-context code, i.e., repositories. To this end, we initiate the RepoQA benchmark to evaluate LLMs on long-context code understanding. Traditional needle testers ask LLMs to directly retrieve the answer from the context without necessary deep understanding. In RepoQA, we built our initial task, namely Searching Needle Function (SNF), which exercises LLMs to search functions given their natural-language description, i.e., LLMs cannot find the desired function if they cannot understand the description and code. RepoQA is multilingual and comprehensive: it includes 500 code search tasks gathered from 50 popular repositories across 5 modern programming languages. By evaluating 26 general and code-specific LLMs on RepoQA, we show (i) there is still a small gap between the best open and proprietary models; (ii) different models are good at different languages; and (iii) models may understand code better without comments.
Read more6/11/2024