RepoQA: Evaluating Long Context Code Understanding
2406.06025
0
0
Abstract
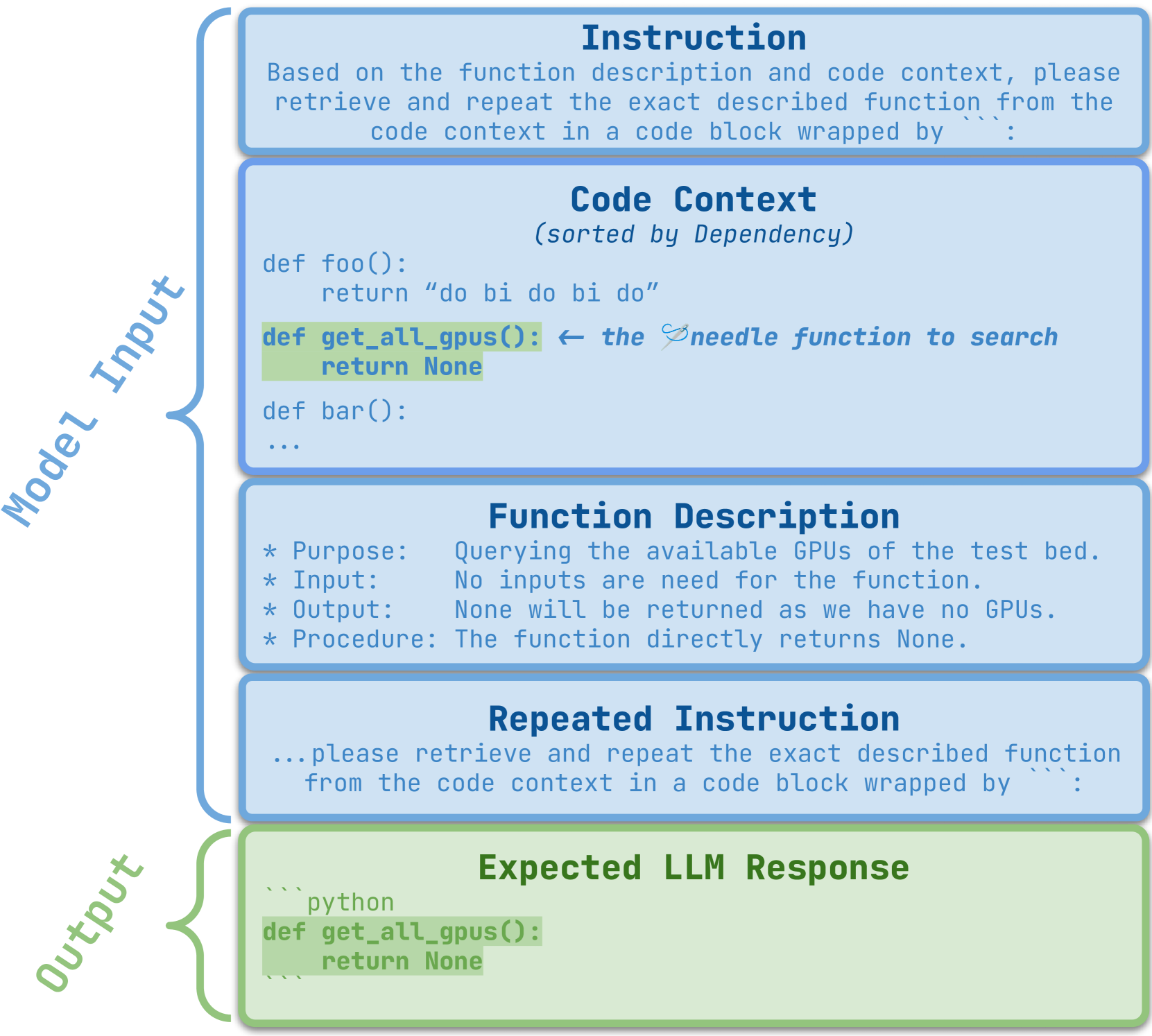
Recent advances have been improving the context windows of Large Language Models (LLMs). To quantify the real long-context capabilities of LLMs, evaluators such as the popular Needle in a Haystack have been developed to test LLMs over a large chunk of raw texts. While effective, current evaluations overlook the insight of how LLMs work with long-context code, i.e., repositories. To this end, we initiate the RepoQA benchmark to evaluate LLMs on long-context code understanding. Traditional needle testers ask LLMs to directly retrieve the answer from the context without necessary deep understanding. In RepoQA, we built our initial task, namely Searching Needle Function (SNF), which exercises LLMs to search functions given their natural-language description, i.e., LLMs cannot find the desired function if they cannot understand the description and code. RepoQA is multilingual and comprehensive: it includes 500 code search tasks gathered from 50 popular repositories across 5 modern programming languages. By evaluating 26 general and code-specific LLMs on RepoQA, we show (i) there is still a small gap between the best open and proprietary models; (ii) different models are good at different languages; and (iii) models may understand code better without comments.
Create account to get full access
Overview
- This paper, titled "RepoQA: Evaluating Long Context Code Understanding," explores the challenge of training language models to understand and reason about long-form programming code.
- The researchers introduce a new dataset, RepoQA, which contains long code snippets from real-world software repositories along with associated questions and answers.
- The paper evaluates the performance of several state-of-the-art language models on the RepoQA dataset, highlighting the difficulties these models face when working with extended code contexts.
- The findings suggest that current language models struggle to maintain coherence and accurately answer questions when the input code is long and complex, indicating a need for further advancements in long-context understanding.
Plain English Explanation
The paper examines the ability of artificial intelligence (AI) language models to understand and answer questions about lengthy, real-world computer code. The researchers created a new dataset called RepoQA, which contains long code snippets from actual software projects, along with questions and answers related to the code.
When tested on the RepoQA dataset, state-of-the-art language models [like those used in RULER: What's the Real Context Size for Your Long-Form NLP? and Long-Span Question Answering and Automatic Question Generation] struggled to maintain coherence and accurately answer questions about the extended code contexts.
This indicates that while these models perform well on many language tasks, they still have difficulty understanding and reasoning about lengthy, complex programming code. The findings highlight the need for further advancements in the field of long-context language learning to improve AI's ability to comprehend and work with real-world, long-form code.
Technical Explanation
The paper introduces the RepoQA dataset, which contains over 3,000 code snippets from popular software repositories, along with associated questions and answers. The code snippets are significantly longer than those found in typical programming language understanding benchmarks, with an average length of over 500 tokens.
The researchers evaluated the performance of several state-of-the-art language models, including T5 and GPT-3, on the RepoQA dataset. The models were tasked with answering questions about the provided code snippets, which required them to maintain context and coherence over the extended input.
The results showed that the language models struggled to perform well on the RepoQA task, with significant declines in performance as the length of the code context increased. This suggests that current models, while effective on many natural language processing (NLP) tasks, still have difficulty fully understanding and reasoning about long-form programming code.
The paper's findings contribute to the growing body of research on the limitations of language models when dealing with extended contexts, and highlight the need for further advancements in the field of long-context language understanding.
Critical Analysis
The RepoQA dataset and the study's findings provide valuable insights into the challenges of training language models to work with long-form programming code. The researchers acknowledge that the dataset may not be representative of all real-world code, as it is focused on popular open-source repositories, and they call for the creation of additional benchmarks to further explore this problem.
Additionally, the paper does not delve deeply into potential solutions or architectural improvements that could help language models better handle long code contexts. While the authors suggest that further research is needed, they do not offer specific recommendations or directions for future work.
It is also worth noting that the study's focus is on evaluating the performance of existing language models, rather than introducing novel approaches or model designs. While this provides a useful baseline, it does not directly address the underlying limitations that contribute to the observed challenges.
Overall, the paper makes a compelling case for the need to advance the field of long-context language understanding, particularly as it relates to the comprehension and reasoning of complex programming code. The RepoQA dataset and the study's findings provide a valuable foundation for future research in this area.
Conclusion
The "RepoQA: Evaluating Long Context Code Understanding" paper highlights the limitations of current state-of-the-art language models when it comes to understanding and reasoning about long-form programming code. The introduction of the RepoQA dataset, which contains extended code snippets from real-world software repositories, and the subsequent evaluation of several language models on this task, demonstrate the significant challenges that these models face when working with complex, long-context inputs.
The findings from this research underline the need for continued advancements in the field of long-context language learning, as AI systems that can effectively comprehend and work with lengthy, real-world code would have a profound impact on various software engineering and programming-related applications. The paper serves as a valuable contribution to the ongoing efforts to push the boundaries of natural language understanding and reasoning, particularly in the domain of programming and software development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

NovelQA: Benchmarking Question Answering on Documents Exceeding 200K Tokens
Cunxiang Wang, Ruoxi Ning, Boqi Pan, Tonghui Wu, Qipeng Guo, Cheng Deng, Guangsheng Bao, Xiangkun Hu, Zheng Zhang, Qian Wang, Yue Zhang
0
0
The rapid advancement of Large Language Models (LLMs) has introduced a new frontier in natural language processing, particularly in understanding and processing long-context information. However, the evaluation of these models' long-context abilities remains a challenge due to the limitations of current benchmarks. To address this gap, we introduce NovelQA, a benchmark specifically designed to test the capabilities of LLMs with extended texts. Constructed from English novels, NovelQA offers a unique blend of complexity, length, and narrative coherence, making it an ideal tool for assessing deep textual understanding in LLMs. This paper presents the design and construction of NovelQA, highlighting its manual annotation, and diverse question types. Our evaluation of Long-context LLMs on NovelQA reveals significant insights into the models' performance, particularly emphasizing the challenges they face with multi-hop reasoning, detail-oriented questions, and extremely long input with an average length more than 200,000 tokens. The results underscore the necessity for further advancements in LLMs to improve their long-context comprehension.
6/18/2024

Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, S'ebastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, Kelvin Guu
0
0
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
6/21/2024

Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models
Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Nambi, Tanuja Ganu, Hao Wang
0
0
Multimodal Large Language Models (MLLMs) have shown significant promise in various applications, leading to broad interest from researchers and practitioners alike. However, a comprehensive evaluation of their long-context capabilities remains underexplored. To address these gaps, we introduce the MultiModal Needle-in-a-haystack (MMNeedle) benchmark, specifically designed to assess the long-context capabilities of MLLMs. Besides multi-image input, we employ image stitching to further increase the input context length, and develop a protocol to automatically generate labels for sub-image level retrieval. Essentially, MMNeedle evaluates MLLMs by stress-testing their capability to locate a target sub-image (needle) within a set of images (haystack) based on textual instructions and descriptions of image contents. This setup necessitates an advanced understanding of extensive visual contexts and effective information retrieval within long-context image inputs. With this benchmark, we evaluate state-of-the-art MLLMs, encompassing both API-based and open-source models. The findings reveal that GPT-4o consistently surpasses other models in long-context scenarios, but suffers from hallucination problems in negative samples, i.e., when needles are not in the haystacks. Our comprehensive long-context evaluation of MLLMs also sheds lights on the considerable performance gap between API-based and open-source models. All the code, data, and instructions required to reproduce the main results are available at https://github.com/Wang-ML-Lab/multimodal-needle-in-a-haystack.
6/18/2024
🤔
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, Juanzi Li
0
0
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.
6/21/2024