Long-Context Language Modeling with Parallel Context Encoding
2402.16617
0
0

Abstract
Extending large language models (LLMs) to process longer inputs is crucial for a wide range of applications. However, the substantial computational cost of transformers and limited generalization of positional encoding restrict the size of their context window. We introduce Context Expansion with Parallel Encoding (CEPE), a framework that can be applied to any existing decoder-only LLMs to extend their context window. CEPE employs a small encoder to process long inputs chunk by chunk, enabling the frozen decoder to utilize additional contexts via cross-attention. CEPE is efficient, generalizable, and versatile: trained with 8K-token documents, it extends the context window of LLAMA-2 to 128K tokens, offering 10x the throughput with only 1/6 of the memory. CEPE yields strong performance on language modeling and in-context learning. CEPE also excels in retrieval-augmented applications, while existing long-context models degenerate with retrieved contexts. We further introduce a CEPE variant that can extend the context window of instruction-tuned models using only unlabeled data, and showcase its effectiveness on LLAMA-2-CHAT, leading to a strong instruction-following model that can leverage very long contexts on downstream tasks.
Create account to get full access
Overview
- This paper introduces a novel language modeling approach called CEPE (Parallel Context Encoding) that aims to improve the ability of large language models to process and utilize long-context information.
- CEPE employs a parallel encoding architecture that encodes the current input and its surrounding context simultaneously, capturing both local and global information.
- The authors demonstrate that CEPE outperforms existing methods on several long-context language modeling benchmarks, highlighting its potential to advance the state-of-the-art in this area.
Plain English Explanation
Large language models, such as GPT-3, have revolutionized natural language processing by generating human-like text. However, these models can struggle when faced with long passages of text, as they may have difficulty remembering and integrating information from the broader context.
The CEPE approach proposed in this paper aims to address this challenge. The key idea is to encode the current input and its surrounding context in parallel, rather than sequentially. This allows the model to capture both local information (e.g., the immediate words) and global information (e.g., the broader topic or theme) simultaneously.
Imagine you're reading a long novel and trying to understand the current chapter. With a traditional language model, it might be difficult to keep track of all the relevant details from previous chapters. But with CEPE, the model can process the current chapter while also considering the overall story arc and character development, leading to a richer and more coherent understanding.
The authors demonstrate the effectiveness of CEPE on several benchmarks, showing that it outperforms existing methods for tasks that require processing long passages of text, such as long-context retrieval and long-form question answering. This suggests that CEPE could be a valuable tool for applications that rely on understanding and reasoning about long-form content, such as scaling large language models to handle longer contexts or improving text generation for longer passages.
Technical Explanation
The core of the CEPE approach is a parallel encoding architecture that processes the current input and its surrounding context simultaneously. Specifically, the model consists of two parallel encoder components: one that encodes the current input (e.g., a sentence or paragraph) and another that encodes the broader context (e.g., the preceding and following sentences or paragraphs).
The outputs of these parallel encoders are then combined and fed into a decoder, which is responsible for generating the next token or predicting the next output. By encoding the current input and context in parallel, the model can capture both local and global information, potentially leading to a more coherent and contextually-aware understanding of the language.
The authors evaluate CEPE on several long-context language modeling tasks, including long-range text generation, long-context retrieval, and long-form question answering. The results demonstrate that CEPE outperforms existing approaches, such as LongT5 and ContextAE, on these benchmarks, highlighting the benefits of the parallel encoding architecture.
Critical Analysis
The CEPE approach represents a promising step forward in addressing the challenge of long-context language modeling. By explicitly incorporating both local and global information, the model can potentially capture a richer understanding of the language than traditional sequential encoding methods.
However, the paper does not provide a detailed analysis of the specific mechanisms or architectural choices that enable CEPE to outperform existing methods. It would be valuable to have a deeper understanding of how the parallel encoding architecture contributes to the model's performance and what trade-offs or limitations it may introduce.
Additionally, the paper focuses on a limited set of benchmarks, and it would be interesting to see how CEPE performs on a broader range of tasks, especially those that require more complex reasoning or understanding of long-form content. Exploring the model's generalization capabilities and potential applications in real-world scenarios could further highlight its strengths and weaknesses.
Conclusion
The CEPE approach presented in this paper represents a significant advancement in long-context language modeling. By encoding the current input and its surrounding context in parallel, the model can capture both local and global information, leading to improved performance on tasks that require understanding and reasoning about long passages of text.
The results demonstrate the potential of CEPE to enhance the capabilities of large language models, with potential applications in areas such as long-form question answering, long-range text generation, and text summarization. As the field of natural language processing continues to evolve, innovations like CEPE will be crucial in pushing the boundaries of what large language models can achieve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
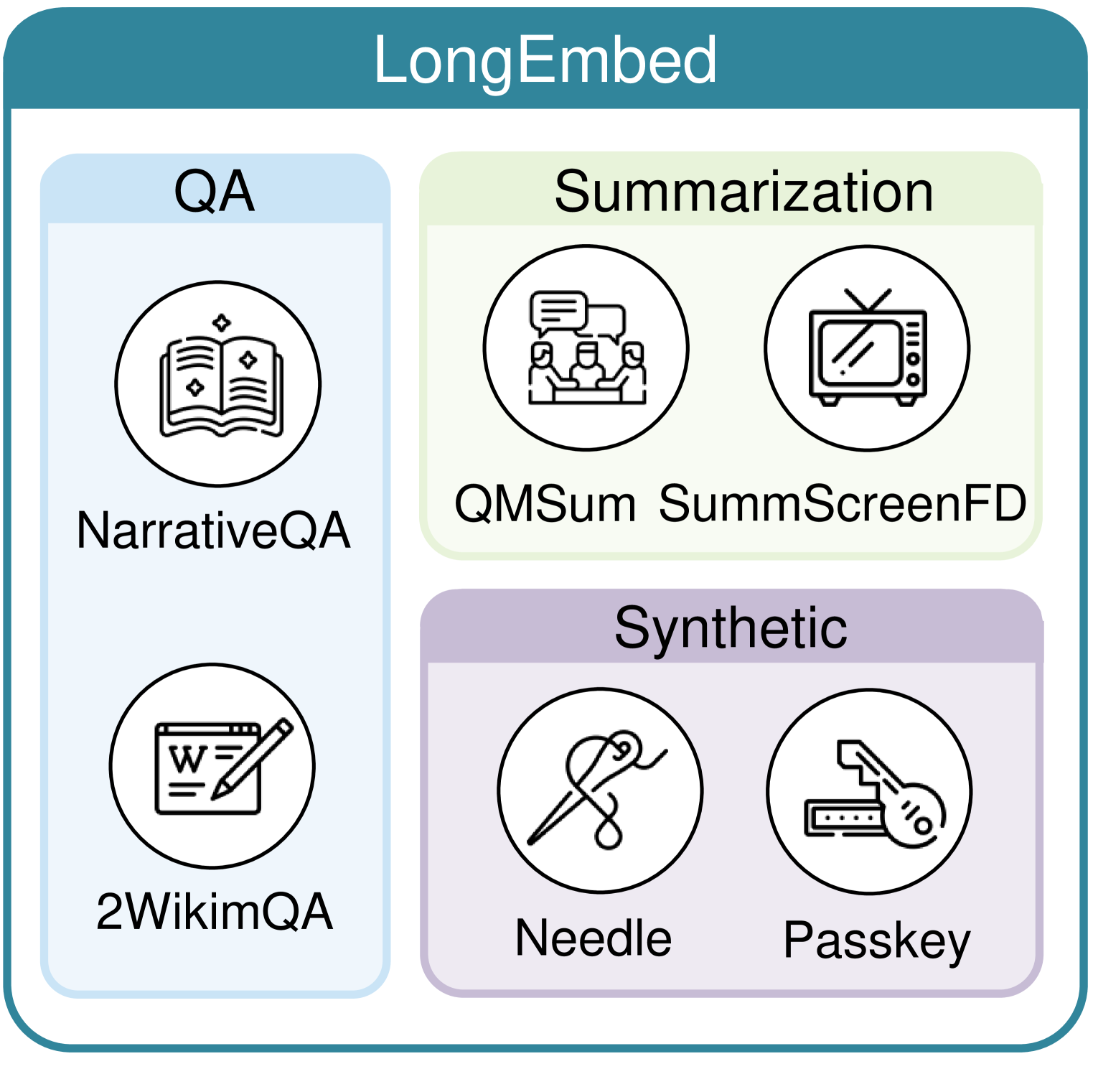
LongEmbed: Extending Embedding Models for Long Context Retrieval
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li
0
0
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
4/26/2024
💬
In-context Autoencoder for Context Compression in a Large Language Model
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, Furu Wei
0
0
We propose the In-context Autoencoder (ICAE), leveraging the power of a large language model (LLM) to compress a long context into short compact memory slots that can be directly conditioned on by the LLM for various purposes. ICAE is first pretrained using both autoencoding and language modeling objectives on massive text data, enabling it to generate memory slots that accurately and comprehensively represent the original context. Then, it is fine-tuned on instruction data for producing desirable responses to various prompts. Experiments demonstrate that our lightweight ICAE, introducing about 1% additional parameters, effectively achieves $4times$ context compression based on Llama, offering advantages in both improved latency and GPU memory cost during inference, and showing an interesting insight in memorization as well as potential for scalability. These promising results imply a novel perspective on the connection between working memory in cognitive science and representation learning in LLMs, revealing ICAE's significant implications in addressing the long context problem and suggesting further research in LLM context management. Our data, code and models are available at https://github.com/getao/icae.
5/10/2024
💬
Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models
Xindi Wang, Mahsa Salmani, Parsa Omidi, Xiangyu Ren, Mehdi Rezagholizadeh, Armaghan Eshaghi
0
0
Recently, large language models (LLMs) have shown remarkable capabilities including understanding context, engaging in logical reasoning, and generating responses. However, this is achieved at the expense of stringent computational and memory requirements, hindering their ability to effectively support long input sequences. This survey provides an inclusive review of the recent techniques and methods devised to extend the sequence length in LLMs, thereby enhancing their capacity for long-context understanding. In particular, we review and categorize a wide range of techniques including architectural modifications, such as modified positional encoding and altered attention mechanisms, which are designed to enhance the processing of longer sequences while avoiding a proportional increase in computational requirements. The diverse methodologies investigated in this study can be leveraged across different phases of LLMs, i.e., training, fine-tuning and inference. This enables LLMs to efficiently process extended sequences. The limitations of the current methodologies is discussed in the last section along with the suggestions for future research directions, underscoring the importance of sequence length in the continued advancement of LLMs.
5/30/2024

Training-Free Long-Context Scaling of Large Language Models
Chenxin An, Fei Huang, Jun Zhang, Shansan Gong, Xipeng Qiu, Chang Zhou, Lingpeng Kong
0
0
The ability of Large Language Models (LLMs) to process and generate coherent text is markedly weakened when the number of input tokens exceeds their pretraining length. Given the expensive overhead of finetuning large-scale models with longer sequences, we propose Dual Chunk Attention (DCA), which enables Llama2 70B to support context windows of more than 100k tokens without continual training. By decomposing the attention computation for long sequences into chunk-based modules, DCA manages to effectively capture the relative positional information of tokens within the same chunk (Intra-Chunk) and across distinct chunks (Inter-Chunk), as well as integrates seamlessly with Flash Attention. In addition to its impressive extrapolation capability, DCA achieves performance on practical long-context tasks that is comparable to or even better than that of finetuned models. When compared with proprietary models, our training-free 70B model attains 94% of the performance of gpt-3.5-16k, indicating it is a viable open-source alternative. All code and data used in this work are released at url{https://github.com/HKUNLP/ChunkLlama}.
5/30/2024