LongEmbed: Extending Embedding Models for Long Context Retrieval
2404.12096
0
0
Abstract
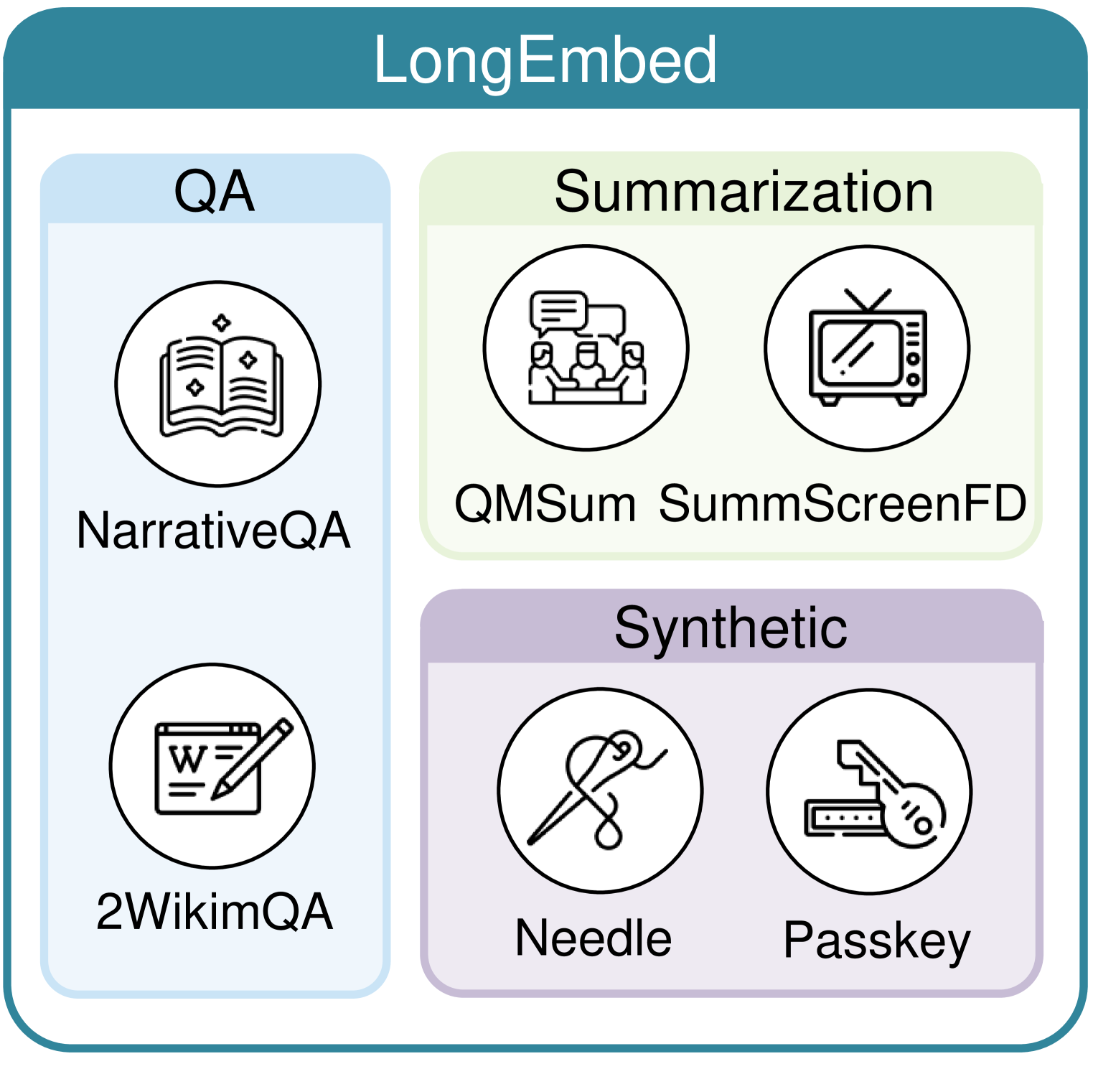
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
Create account to get full access
Overview
- This paper introduces LongEmbed, a new benchmark for evaluating the ability of language models to handle long-form content.
- The authors argue that current language models struggle with long-context understanding, and propose extensions to embedding models to better capture long-range dependencies.
- The paper also presents a new dataset, XLDollar2DollarBench, to measure how well models can understand extremely long passages of text.
Plain English Explanation
The researchers behind this paper noticed that modern language models often have trouble understanding and processing long pieces of text, like full articles or book chapters. They wanted to create a new way to test how well these models can handle long-form content.
To do this, they developed a new benchmark called LongEmbed that specifically evaluates a model's ability to understand and retrieve information from long passages of text. They also created a dataset called XLDollar2DollarBench that contains extremely long documents, to really push the limits of how much context these models can handle.
The key insight is that most language models today are optimized for short, sentence-level tasks, but struggle when faced with longer, more complex inputs. By creating new benchmarks and datasets focused on long-form understanding, the researchers hope to spur the development of better language models that can handle the nuances and connections within longer pieces of text.
Technical Explanation
The paper introduces the LongEmbed benchmark, which aims to evaluate the ability of language models to retrieve relevant information from long passages of text. Unlike standard information retrieval tasks that focus on short queries, LongEmbed provides models with lengthy passages as input and challenges them to identify the most relevant segments.
To create this benchmark, the authors curated a diverse dataset of long-form documents, including academic papers, news articles, and book chapters. They then annotated these documents with relevance labels for various queries, allowing them to measure how well models can match long inputs to the most salient content.
In addition, the paper presents the XLDollar2DollarBench dataset, which contains even longer documents (up to 50,000 words) to test the limits of language model long-context understanding. The authors hypothesize that current models, which are typically optimized for shorter sequences, will struggle with these extremely long inputs.
To address the challenges of long-context learning, the paper proposes several extensions to standard embedding models. These include using hierarchical attention mechanisms to capture multi-scale dependencies, as well as pre-training techniques to better learn long-range relationships in text. The authors evaluate these LongEmbed model variants on the new benchmarks and find that they outperform baseline approaches.
Critical Analysis
The paper makes a compelling case that existing language models have significant limitations when it comes to long-form text understanding, and that new benchmarks and model architectures are needed to address this challenge.
One potential limitation of the work is the reliance on manual relevance annotations for the LongEmbed dataset. While this approach allows for controlled evaluation, it may not fully capture the complexities of real-world information retrieval tasks. Exploring unsupervised or weakly supervised methods for long-context learning could be an interesting direction for future research.
Additionally, the XLDollar2DollarBench dataset, while valuable for stress-testing model capabilities, may not be representative of the types of long-form content that users typically interact with. Expanding the dataset to include a wider range of long-form text genres could help make the findings more generalizable.
That said, the paper's focus on advancing the state-of-the-art in long-context language modeling is a clear strength, and the proposed LongEmbed model extensions represent a promising step forward. As language models continue to be adopted for an ever-wider range of applications, the ability to effectively handle long-form content will only become more critical.
Conclusion
In summary, this paper highlights the significant challenges that current language models face when dealing with long-form text, and introduces new benchmarks and model extensions to address this critical limitation. By developing the LongEmbed and XLDollar2DollarBench datasets, the authors have provided valuable tools for the research community to push the boundaries of long-context understanding.
The proposed LongEmbed model enhancements, such as hierarchical attention and specialized pre-training, represent an important step forward in enabling language models to better capture the nuances and interconnections within lengthy passages of text. As the field of natural language processing continues to evolve, the insights and innovations presented in this paper will likely play a key role in the development of more robust and versatile language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences. Some models like Gemini could even to be capable of dealing with millions of tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their true abilities in more challenging, real-world scenarios. We introduce a benchmark (LongICLBench) for long in-context learning in extreme-label classification using six datasets with 28 to 174 classes and input lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate on 15 long-context LLMs and find that they perform well on less challenging classification tasks with smaller label space and shorter demonstrations. However, they struggle with more challenging task like Discovery with 174 labels, suggesting a gap in their ability to process long, context-rich sequences. Further analysis reveals a bias towards labels presented later in the sequence and a need for improved reasoning over multiple pieces of information. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
6/13/2024

Understanding the RoPE Extensions of Long-Context LLMs: An Attention Perspective
Meizhi Zhong, Chen Zhang, Yikun Lei, Xikai Liu, Yan Gao, Yao Hu, Kehai Chen, Min Zhang
0
0
Enabling LLMs to handle lengthy context is currently a research hotspot. Most LLMs are built upon rotary position embedding (RoPE), a popular position encoding method. Therefore, a prominent path is to extrapolate the RoPE trained on comparably short texts to far longer texts. A heavy bunch of efforts have been dedicated to boosting the extrapolation via extending the formulations of the RoPE, however, few of them have attempted to showcase their inner workings comprehensively. In this paper, we are driven to offer a straightforward yet in-depth understanding of RoPE extensions from an attention perspective and on two benchmarking tasks. A broad array of experiments reveals several valuable findings: 1) Maintaining attention patterns to those at the pretrained length improves extrapolation; 2) Large attention uncertainty leads to retrieval errors; 3) Using longer continual pretraining lengths for RoPE extensions could reduce attention uncertainty and significantly enhance extrapolation.
6/21/2024

Resonance RoPE: Improving Context Length Generalization of Large Language Models
Suyuchen Wang, Ivan Kobyzev, Peng Lu, Mehdi Rezagholizadeh, Bang Liu
0
0
This paper addresses the challenge of train-short-test-long (TSTL) scenarios in Large Language Models (LLMs) equipped with Rotary Position Embedding (RoPE), where models pre-trained on shorter sequences face difficulty with out-of-distribution (OOD) token positions in longer sequences. We introduce Resonance RoPE, a novel approach designed to narrow the generalization gap in TSTL scenarios by refining the interpolation of RoPE features for OOD positions, significantly improving the model performance without additional online computational costs. Furthermore, we present PosGen, a new synthetic benchmark specifically designed for fine-grained behavior analysis in TSTL scenarios, aiming to isolate the constantly increasing difficulty of token generation on long contexts from the challenges of recognizing new token positions. Our experiments on synthetic tasks show that after applying Resonance RoPE, Transformers recognize OOD position better and more robustly. Our extensive LLM experiments also show superior performance after applying Resonance RoPE to the current state-of-the-art RoPE scaling method, YaRN, on both upstream language modeling tasks and a variety of downstream long-text applications.
6/11/2024

Long-Context Language Modeling with Parallel Context Encoding
Howard Yen, Tianyu Gao, Danqi Chen
0
0
Extending large language models (LLMs) to process longer inputs is crucial for a wide range of applications. However, the substantial computational cost of transformers and limited generalization of positional encoding restrict the size of their context window. We introduce Context Expansion with Parallel Encoding (CEPE), a framework that can be applied to any existing decoder-only LLMs to extend their context window. CEPE employs a small encoder to process long inputs chunk by chunk, enabling the frozen decoder to utilize additional contexts via cross-attention. CEPE is efficient, generalizable, and versatile: trained with 8K-token documents, it extends the context window of LLAMA-2 to 128K tokens, offering 10x the throughput with only 1/6 of the memory. CEPE yields strong performance on language modeling and in-context learning. CEPE also excels in retrieval-augmented applications, while existing long-context models degenerate with retrieved contexts. We further introduce a CEPE variant that can extend the context window of instruction-tuned models using only unlabeled data, and showcase its effectiveness on LLAMA-2-CHAT, leading to a strong instruction-following model that can leverage very long contexts on downstream tasks.
6/13/2024