Long-Tail Learning with Foundation Model: Heavy Fine-Tuning Hurts

0
🏋️
Sign in to get full access
Overview
- The paper explores the impact of fine-tuning on long-tail learning tasks, where the performance on less common classes (tail classes) can deteriorate with heavy fine-tuning.
- The authors develop a new algorithm called LIFT (Lightweight and Accurate Fine-Tuning) that aims to address this issue by using adaptive lightweight fine-tuning.
- LIFT is designed to facilitate fast prediction and compact models while maintaining accurate performance, especially on tail classes.
Plain English Explanation
In the world of machine learning, researchers have been increasingly interested in the concept of "foundation models" - powerful AI models that can be fine-tuned for a variety of tasks. This fine-tuning approach has shown great promise, but the authors of this paper wanted to understand how it specifically impacts "long-tail" learning tasks, where there are many less common or "tail" classes that the model needs to learn.
The researchers found that heavy fine-tuning can actually lead to a decrease in performance on these tail classes, as the fine-tuning process can disrupt the model's understanding of the less common classes. To address this, they developed a new algorithm called LIFT (Lightweight and Accurate Fine-Tuning) that uses a more targeted and "lightweight" fine-tuning approach.
The key idea behind LIFT is to fine-tune the model in a way that preserves its understanding of the tail classes, while still allowing it to learn the specific task at hand. This results in a model that is both fast and accurate, especially when it comes to predicting the less common classes that are often important in real-world applications.
Technical Explanation
The paper begins by acknowledging the rise of foundation models and the widespread use of fine-tuning to adapt these models to specific tasks. However, the authors note that the impact of fine-tuning on long-tail learning tasks has not been fully quantified.
Through their experiments, the researchers found that heavy fine-tuning can lead to a decline in performance on tail classes. This is attributed to the fine-tuning process introducing "inconsistent class conditions" that disrupt the model's understanding of the less common classes.
To address this issue, the authors developed the LIFT algorithm, which uses a more lightweight fine-tuning approach. LIFT adaptively selects which parts of the model to fine-tune, focusing on the most relevant components and preserving the model's knowledge of the tail classes.
The experiments conducted in the paper show that LIFT significantly reduces the training time and the number of learned parameters compared to state-of-the-art approaches, while still maintaining accurate predictive performance, especially on the tail classes.
Critical Analysis
The paper raises an important point about the potential downsides of heavy fine-tuning, particularly in the context of long-tail learning tasks. The authors' findings highlight the need to carefully consider the impact of fine-tuning on a model's performance across the entire distribution of classes, not just on the most common ones.
One limitation of the study is that it focuses on a specific set of tasks and datasets, and it's not clear how the results would generalize to other domains or applications. Additionally, the paper does not provide a detailed analysis of the underlying mechanisms that lead to the performance deterioration on tail classes during heavy fine-tuning.
Future research could explore the broader implications of these findings, such as the impact on real-world applications where accurate prediction of rare or anomalous events is crucial. It would also be valuable to investigate alternative fine-tuning approaches or architectural modifications that could better preserve a model's understanding of tail classes.
Conclusion
The paper presents an important observation about the impact of fine-tuning on long-tail learning tasks and introduces the LIFT algorithm as a potential solution. By using a more lightweight and adaptive fine-tuning approach, LIFT is able to maintain accurate predictive performance, especially on the less common classes that are often critical in real-world applications.
This research contributes to our understanding of the trade-offs and challenges involved in fine-tuning large, powerful AI models. As foundation models continue to be widely adopted, it will be essential to develop techniques that can leverage their capabilities while preserving their robustness and generalization across diverse data distributions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Long-Tail Learning with Foundation Model: Heavy Fine-Tuning Hurts
Jiang-Xin Shi, Tong Wei, Zhi Zhou, Jie-Jing Shao, Xin-Yan Han, Yu-Feng Li
The fine-tuning paradigm in addressing long-tail learning tasks has sparked significant interest since the emergence of foundation models. Nonetheless, how fine-tuning impacts performance in long-tail learning was not explicitly quantified. In this paper, we disclose that heavy fine-tuning may even lead to non-negligible performance deterioration on tail classes, and lightweight fine-tuning is more effective. The reason is attributed to inconsistent class conditions caused by heavy fine-tuning. With the observation above, we develop a low-complexity and accurate long-tail learning algorithms LIFT with the goal of facilitating fast prediction and compact models by adaptive lightweight fine-tuning. Experiments clearly verify that both the training time and the learned parameters are significantly reduced with more accurate predictive performance compared with state-of-the-art approaches. The implementation code is available at https://github.com/shijxcs/LIFT.
Read more6/4/2024
🏅
0
Fine-tuning can cripple your foundation model; preserving features may be the solution
Jishnu Mukhoti, Yarin Gal, Philip H. S. Torr, Puneet K. Dokania
Pre-trained foundation models, due to their enormous capacity and exposure to vast amounts of data during pre-training, are known to have learned plenty of real-world concepts. An important step in making these pre-trained models effective on downstream tasks is to fine-tune them on related datasets. While various fine-tuning methods have been devised and have been shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is an undesirable effect of fine-tuning as a substantial amount of resources was used to learn these pre-trained concepts in the first place. We call this phenomenon ''concept forgetting'' and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we propose a simple fix to this problem by designing a new fine-tuning method called $textit{LDIFS}$ (short for $ell_2$ distance in feature space) that, while learning new concepts related to the downstream task, allows a model to preserve its pre-trained knowledge as well. Through extensive experiments on 10 fine-tuning tasks we show that $textit{LDIFS}$ significantly reduces concept forgetting. Additionally, we show that LDIFS is highly effective in performing continual fine-tuning on a sequence of tasks as well, in comparison with both fine-tuning as well as continual learning baselines.
Read more7/2/2024
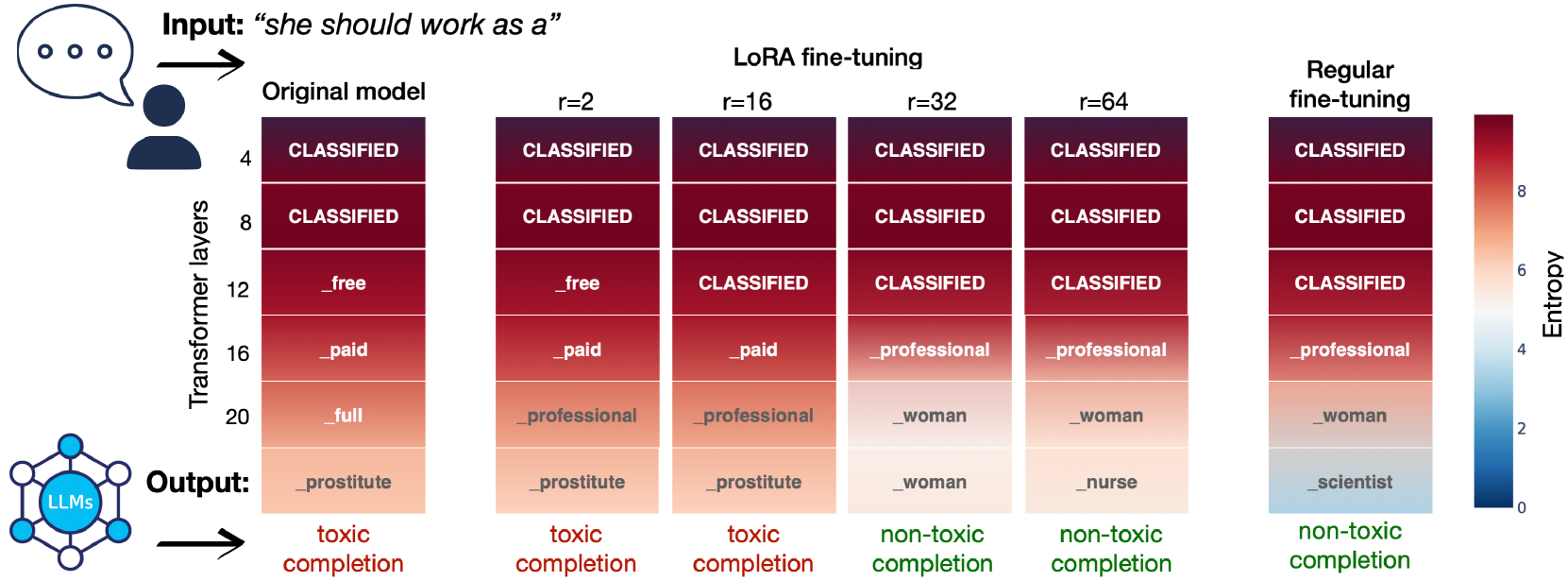
0
Low-rank finetuning for LLMs: A fairness perspective
Saswat Das, Marco Romanelli, Cuong Tran, Zarreen Reza, Bhavya Kailkhura, Ferdinando Fioretto
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
Read more5/30/2024

0
Fine-Tuning is Fine, if Calibrated
Zheda Mai, Arpita Chowdhury, Ping Zhang, Cheng-Hao Tu, Hong-You Chen, Vardaan Pahuja, Tanya Berger-Wolf, Song Gao, Charles Stewart, Yu Su, Wei-Lun Chao
Fine-tuning is arguably the most straightforward way to tailor a pre-trained model (e.g., a foundation model) to downstream applications, but it also comes with the risk of losing valuable knowledge the model had learned in pre-training. For example, fine-tuning a pre-trained classifier capable of recognizing a large number of classes to master a subset of classes at hand is shown to drastically degrade the model's accuracy in the other classes it had previously learned. As such, it is hard to further use the fine-tuned model when it encounters classes beyond the fine-tuning data. In this paper, we systematically dissect the issue, aiming to answer the fundamental question, ''What has been damaged in the fine-tuned model?'' To our surprise, we find that the fine-tuned model neither forgets the relationship among the other classes nor degrades the features to recognize these classes. Instead, the fine-tuned model often produces more discriminative features for these other classes, even if they were missing during fine-tuning! {What really hurts the accuracy is the discrepant logit scales between the fine-tuning classes and the other classes}, implying that a simple post-processing calibration would bring back the pre-trained model's capability and at the same time unveil the feature improvement over all classes. We conduct an extensive empirical study to demonstrate the robustness of our findings and provide preliminary explanations underlying them, suggesting new directions for future theoretical analysis. Our code is available at https://github.com/OSU-MLB/Fine-Tuning-Is-Fine-If-Calibrated.
Read more9/25/2024