Low-rank finetuning for LLMs: A fairness perspective
2405.18572
0
0
Abstract
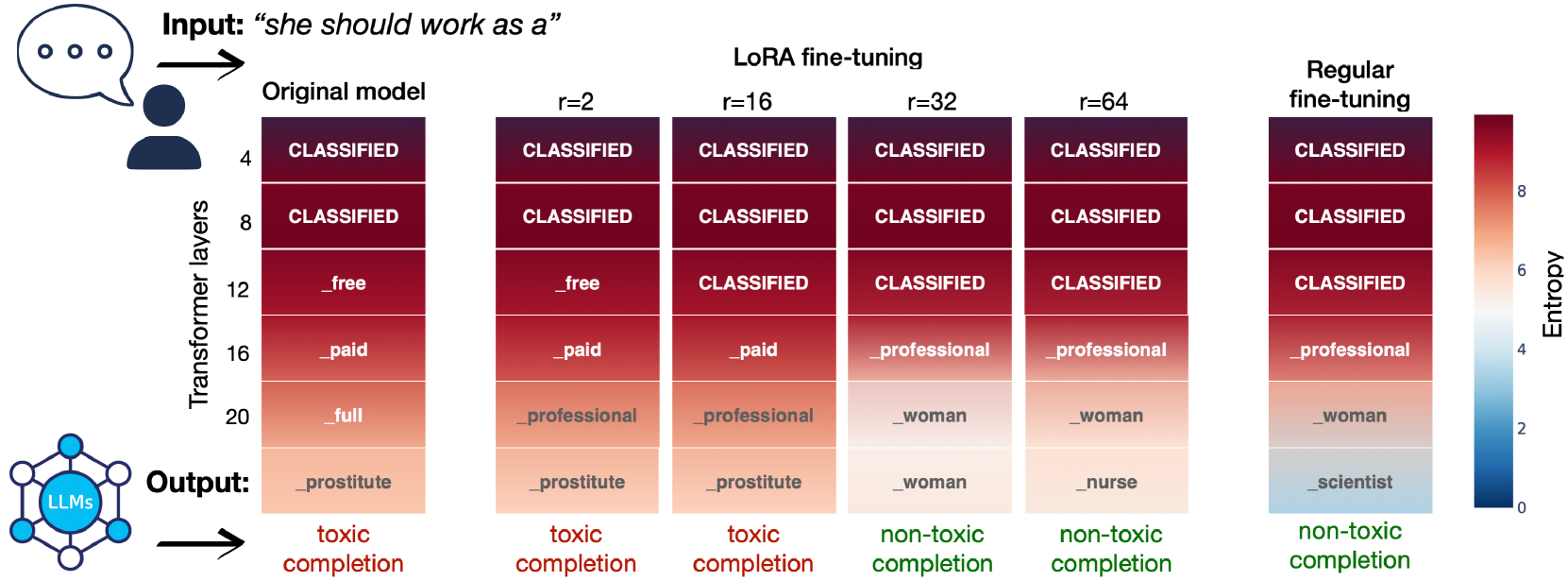
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
Create account to get full access
Overview
- This paper explores the fairness implications of using low-rank finetuning techniques to adapt large language models (LLMs) for specific tasks.
- The researchers investigate whether low-rank finetuning, which updates only a small subset of model parameters, can maintain or even improve the fairness of LLM predictions compared to full model finetuning.
- The paper provides a comprehensive analysis of the fairness-accuracy tradeoffs associated with different finetuning techniques, as well as strategies for promoting fairness in LLM adaptation.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can also exhibit biases and unfairness, making their outputs potentially unfair or discriminatory. [Link: https://aimodels.fyi/papers/arxiv/fairness-large-language-models-taxonomic-survey]
Low-rank finetuning is a technique that can be used to adapt LLMs for specific tasks while updating only a small subset of the model's parameters. The researchers in this paper investigate whether this approach can help maintain or even improve the fairness of the model's predictions compared to full model finetuning.
The key idea is that by updating only a small part of the model, low-rank finetuning may be able to fine-tune the model for a specific task without significantly changing the underlying knowledge and biases learned during the model's initial training. This could help preserve the model's fairness while still improving its performance on the target task.
The researchers conduct a detailed analysis to understand the fairness-accuracy tradeoffs of different finetuning techniques, and they also explore strategies for promoting fairness in LLM adaptation. Their findings provide important insights for researchers and practitioners working on developing fair and responsible AI systems.
Technical Explanation
The paper begins by introducing the concept of low-rank finetuning, which the authors use as the primary technique for adapting LLMs to specific tasks. [Link: https://aimodels.fyi/papers/arxiv/fairness-low-rank-adaptation-large-models]
In low-rank finetuning, only a small subset of the model's parameters are updated during the finetuning process, while the majority of the parameters remain fixed. This is in contrast to "full model finetuning," where all of the model's parameters are updated.
The researchers hypothesize that low-rank finetuning may be able to maintain or even improve the fairness of LLM predictions compared to full model finetuning. The rationale is that by only updating a small portion of the model, low-rank finetuning may be able to fine-tune the model for a specific task without significantly altering the underlying knowledge and biases learned during the model's initial training.
To test this hypothesis, the researchers conduct a series of experiments using several LLMs and fairness evaluation metrics. They compare the fairness and accuracy of models finetuned using low-rank techniques to those finetuned using full model updates.
The results of the experiments provide valuable insights into the fairness-accuracy tradeoffs associated with different finetuning approaches. The researchers also explore strategies for promoting fairness in LLM adaptation, such as using targeted data selection and fine-grained fairness constraints. [Link: https://aimodels.fyi/papers/arxiv/get-more-less-principled-data-selection-warming]
Overall, the paper offers a comprehensive analysis of the fairness implications of using low-rank finetuning techniques for LLM adaptation, with important implications for the development of fair and responsible AI systems.
Critical Analysis
The paper provides a thorough and well-designed study on the fairness implications of low-rank finetuning for LLMs. The researchers acknowledge several limitations and caveats in their work, such as the need for further investigation into the underlying mechanisms driving the observed fairness-accuracy tradeoffs.
One potential issue that is not directly addressed in the paper is the potential for low-rank finetuning to exacerbate certain types of biases or unfairness, even if it maintains overall fairness metrics. [Link: https://aimodels.fyi/papers/arxiv/empirical-analysis-forgetting-pre-trained-models-incremental] The researchers could have explored this possibility in more depth.
Additionally, while the paper provides valuable insights, it would be helpful to see further research on the real-world implications and practical applications of these findings. It would be interesting to understand how these techniques could be deployed in production systems and the challenges that may arise.
Overall, the paper represents an important contribution to the ongoing research on fairness in LLMs, and the insights provided can inform the development of more responsible and equitable AI systems. [Link: https://aimodels.fyi/papers/arxiv/do-large-language-models-rank-fairly-empirical]
Conclusion
This paper explores the fairness implications of using low-rank finetuning techniques to adapt large language models (LLMs) for specific tasks. The researchers find that low-rank finetuning can maintain or even improve the fairness of LLM predictions compared to full model finetuning, while still achieving strong performance on the target task.
The study provides a comprehensive analysis of the fairness-accuracy tradeoffs associated with different finetuning techniques and offers strategies for promoting fairness in LLM adaptation. These insights have important implications for the development of fair and responsible AI systems, as LLMs become increasingly ubiquitous in a wide range of applications.
By understanding the fairness implications of low-rank finetuning, researchers and practitioners can work towards creating AI systems that are not only highly capable, but also equitable and unbiased in their outputs and decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

On Fairness of Low-Rank Adaptation of Large Models
Zhoujie Ding, Ken Ziyu Liu, Pura Peetathawatchai, Berivan Isik, Sanmi Koyejo
0
0
Low-rank adaptation of large models, particularly LoRA, has gained traction due to its computational efficiency. This efficiency, contrasted with the prohibitive costs of full-model fine-tuning, means that practitioners often turn to LoRA and sometimes without a complete understanding of its ramifications. In this study, we focus on fairness and ask whether LoRA has an unexamined impact on utility, calibration, and resistance to membership inference across different subgroups (e.g., genders, races, religions) compared to a full-model fine-tuning baseline. We present extensive experiments across vision and language domains and across classification and generation tasks using ViT-Base, Swin-v2-Large, Llama-2 7B, and Mistral 7B. Intriguingly, experiments suggest that while one can isolate cases where LoRA exacerbates model bias across subgroups, the pattern is inconsistent -- in many cases, LoRA has equivalent or even improved fairness compared to the base model or its full fine-tuning baseline. We also examine the complications of evaluating fine-tuning fairness relating to task design and model token bias, calling for more careful fairness evaluations in future work.
5/29/2024
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
0
0
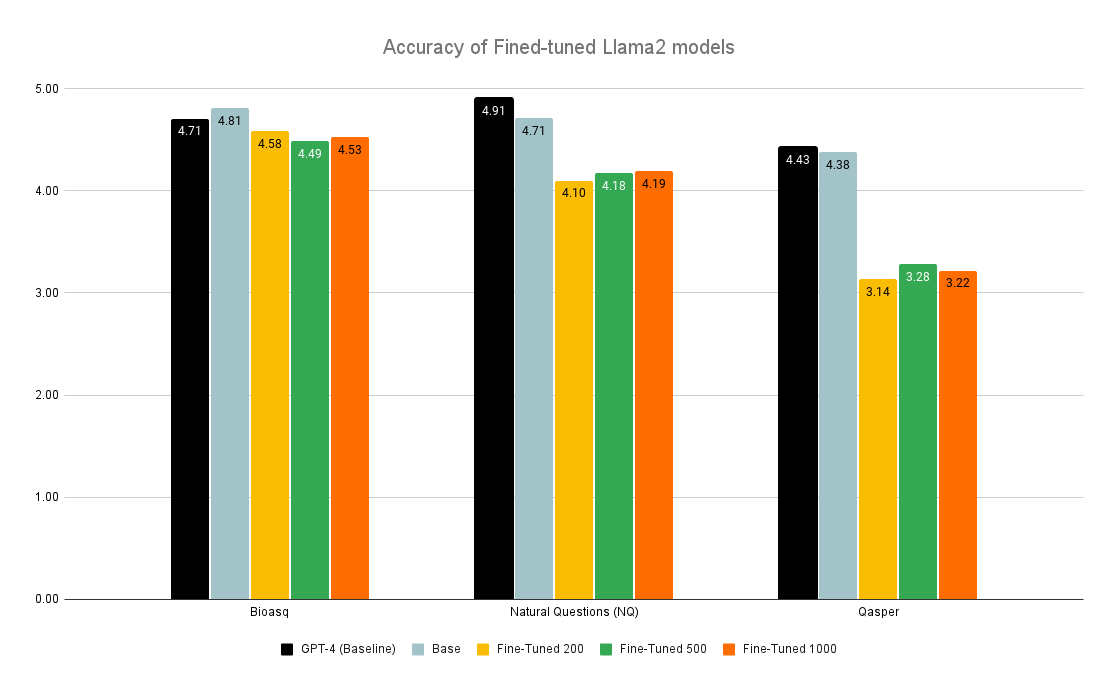
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
6/18/2024
💬
Fairness in Large Language Models: A Taxonomic Survey
Zhibo Chu, Zichong Wang, Wenbin Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
4/3/2024
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
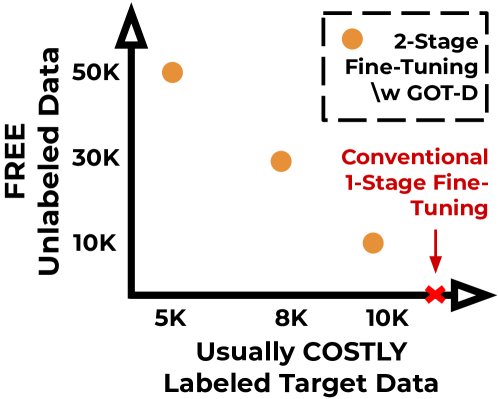
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024