LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding

0
Sign in to get full access
Overview
- Introduces a new benchmark called LongVideoBench for evaluating long-context video-language understanding models
- Focuses on a "Referring Reasoning" task where models must interpret references to objects and events across long video sequences
- Provides a comprehensive dataset and evaluation protocols to measure model performance on this task
Plain English Explanation
LongVideoBench is a new benchmark designed to test how well AI models can understand and reason about video content over long time periods. The key task is "Referring Reasoning", where the model must interpret references to specific objects, people, or events that are spread out across an extended video sequence.
This is a challenging task because it requires the model to maintain a coherent understanding of the video context over a long duration, rather than just processing individual frames or short clips. The benchmark provides a diverse dataset of long videos along with annotations that describe various references within the videos. By evaluating model performance on this task, researchers can better understand the capabilities and limitations of current video-language AI systems.
The goal is to push the boundaries of what's possible in terms of video understanding, with potential applications in areas like assistive technology, surveillance, and interactive entertainment. The dataset and evaluation protocols aim to serve as a useful testbed for advancing the state of the art in this important area of AI research.
Technical Explanation
The LongVideoBench dataset contains a diverse collection of long-form videos, ranging from TV shows and movies to instructional tutorials and vlogs. Each video is annotated with a series of "referring expressions" - natural language phrases that refer to specific objects, people, or events within the video.
The key task is "Referring Reasoning", where the model must correctly identify the visual referents (e.g. a particular person or object) based on the provided referring expressions. This requires the model to maintain a coherent understanding of the video context over an extended duration, going beyond just recognizing individual frames or short clips.
To evaluate model performance, the benchmark defines a set of metrics that measure how accurately the models can locate the referenced entities, as well as how well they can reason about the relationships and events described in the referring expressions. This includes challenges like resolving ambiguous references, tracking objects over time, and understanding complex interactions.
The dataset and evaluation protocols are designed to be a comprehensive testbed for video-language AI systems, pushing the boundaries of what's possible in terms of long-form video understanding. Successful models on this benchmark could enable a wide range of applications, from advanced video search and summarization to more natural interaction with digital assistants.
Critical Analysis
While the LongVideoBench dataset and task provide an important new frontier for video-language AI research, there are some potential limitations and areas for further exploration:
- The dataset primarily consists of English-language videos, which may limit the generalizability of models to other languages and cultural contexts. Expanding the linguistic and cultural diversity of the benchmark could yield valuable insights.
- The focus on "referring reasoning" is just one aspect of video understanding - other tasks like action recognition, event prediction, and video summarization could also be valuable to include.
- The long-form nature of the videos introduces challenges around computational complexity and memory usage for models. Innovative architectural and optimization techniques may be needed to scale these models effectively.
- It's unclear how well the benchmark's evaluation metrics capture real-world relevance and usefulness of the models. Further user studies and application-driven evaluations could help bridge this gap.
Overall, LongVideoBench represents an important step forward in benchmarking video-language AI, but there is still significant room for refinement and expansion as the field continues to evolve.
Conclusion
LongVideoBench introduces a new benchmark for evaluating long-context video-language understanding, with a focus on the challenging "Referring Reasoning" task. By providing a diverse dataset and comprehensive evaluation protocols, the benchmark aims to drive progress in an important area of AI research with broad implications.
Successful models on this benchmark could unlock a wide range of applications, from more natural interaction with digital assistants to advanced video search, summarization, and understanding. While the current benchmark has some limitations, it represents a valuable contribution to the field and a useful testbed for advancing the state of the art in video-language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Haoning Wu, Dongxu Li, Bei Chen, Junnan Li
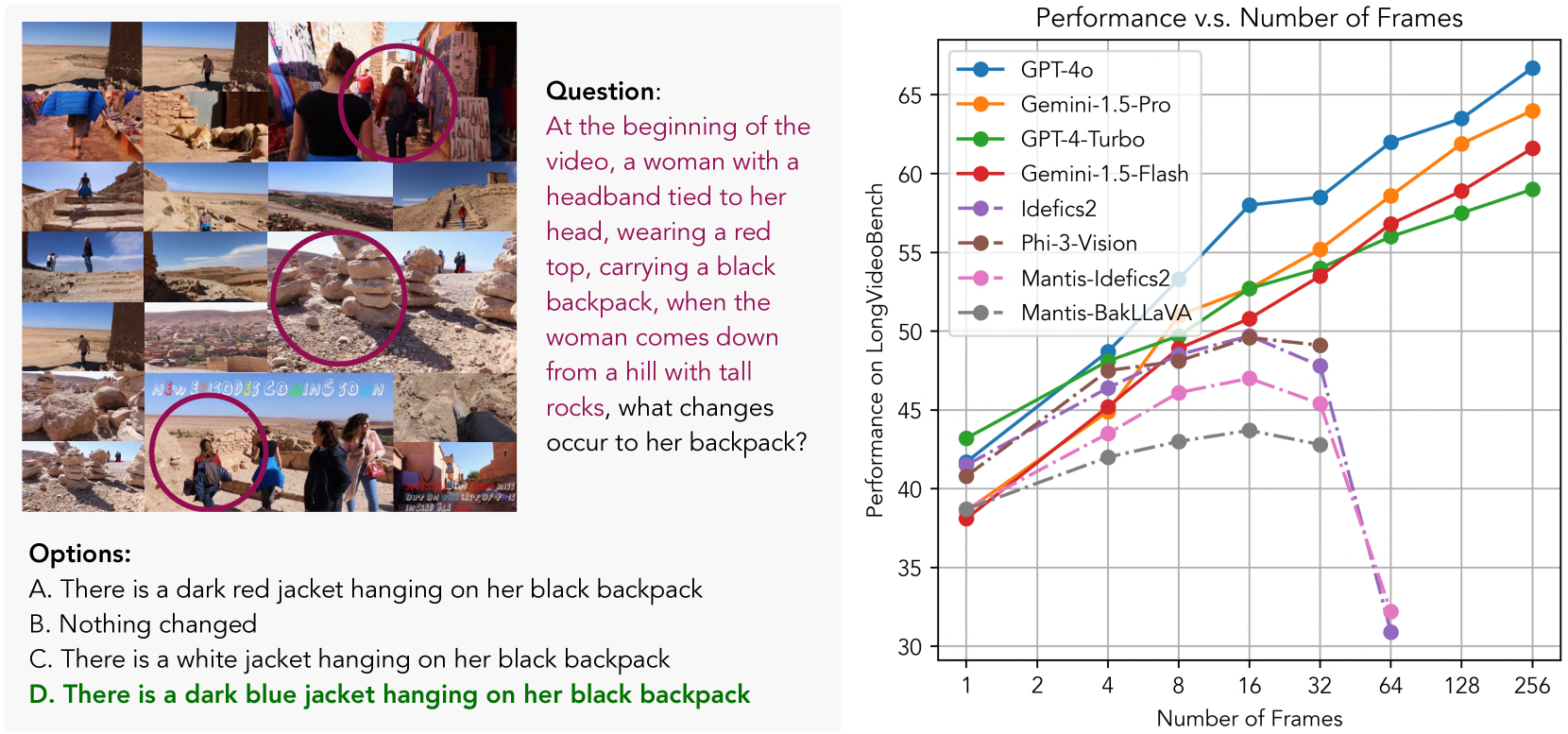
Large multimodal models (LMMs) are processing increasingly longer and richer inputs. Albeit the progress, few public benchmark is available to measure such development. To mitigate this gap, we introduce LongVideoBench, a question-answering benchmark that features video-language interleaved inputs up to an hour long. Our benchmark includes 3,763 varying-length web-collected videos with their subtitles across diverse themes, designed to comprehensively evaluate LMMs on long-term multimodal understanding. To achieve this, we interpret the primary challenge as to accurately retrieve and reason over detailed multimodal information from long inputs. As such, we formulate a novel video question-answering task termed referring reasoning. Specifically, as part of the question, it contains a referring query that references related video contexts, called referred context. The model is then required to reason over relevant video details from the referred context. Following the paradigm of referring reasoning, we curate 6,678 human-annotated multiple-choice questions in 17 fine-grained categories, establishing one of the most comprehensive benchmarks for long-form video understanding. Evaluations suggest that the LongVideoBench presents significant challenges even for the most advanced proprietary models (e.g. GPT-4o, Gemini-1.5-Pro, GPT-4-Turbo), while their open-source counterparts show an even larger performance gap. In addition, our results indicate that model performance on the benchmark improves only when they are capable of processing more frames, positioning LongVideoBench as a valuable benchmark for evaluating future-generation long-context LMMs.
Read more7/23/2024

0
LVBench: An Extreme Long Video Understanding Benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, Jie Tang
Recent progress in multimodal large language models has markedly enhanced the understanding of short videos (typically under one minute), and several evaluation datasets have emerged accordingly. However, these advancements fall short of meeting the demands of real-world applications such as embodied intelligence for long-term decision-making, in-depth movie reviews and discussions, and live sports commentary, all of which require comprehension of long videos spanning several hours. To address this gap, we introduce LVBench, a benchmark specifically designed for long video understanding. Our dataset comprises publicly sourced videos and encompasses a diverse set of tasks aimed at long video comprehension and information extraction. LVBench is designed to challenge multimodal models to demonstrate long-term memory and extended comprehension capabilities. Our extensive evaluations reveal that current multimodal models still underperform on these demanding long video understanding tasks. Through LVBench, we aim to spur the development of more advanced models capable of tackling the complexities of long video comprehension. Our data and code are publicly available at: https://lvbench.github.io.
Read more6/13/2024

0
MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, Kai Chen
The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, we introduce MMBench-Video, a quantitative benchmark designed to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy. We employ GPT-4 for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, we have conducted comprehensive evaluations that include both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding. The evalutation code of MMBench-Video will be integrated into VLMEvalKit: https://github.com/open-compass/VLMEvalKit.
Read more6/21/2024
0
InfiniBench: A Comprehensive Benchmark for Large Multimodal Models in Very Long Video Understanding
Kirolos Ataallah, Chenhui Gou, Eslam Abdelrahman, Khushbu Pahwa, Jian Ding, Mohamed Elhoseiny
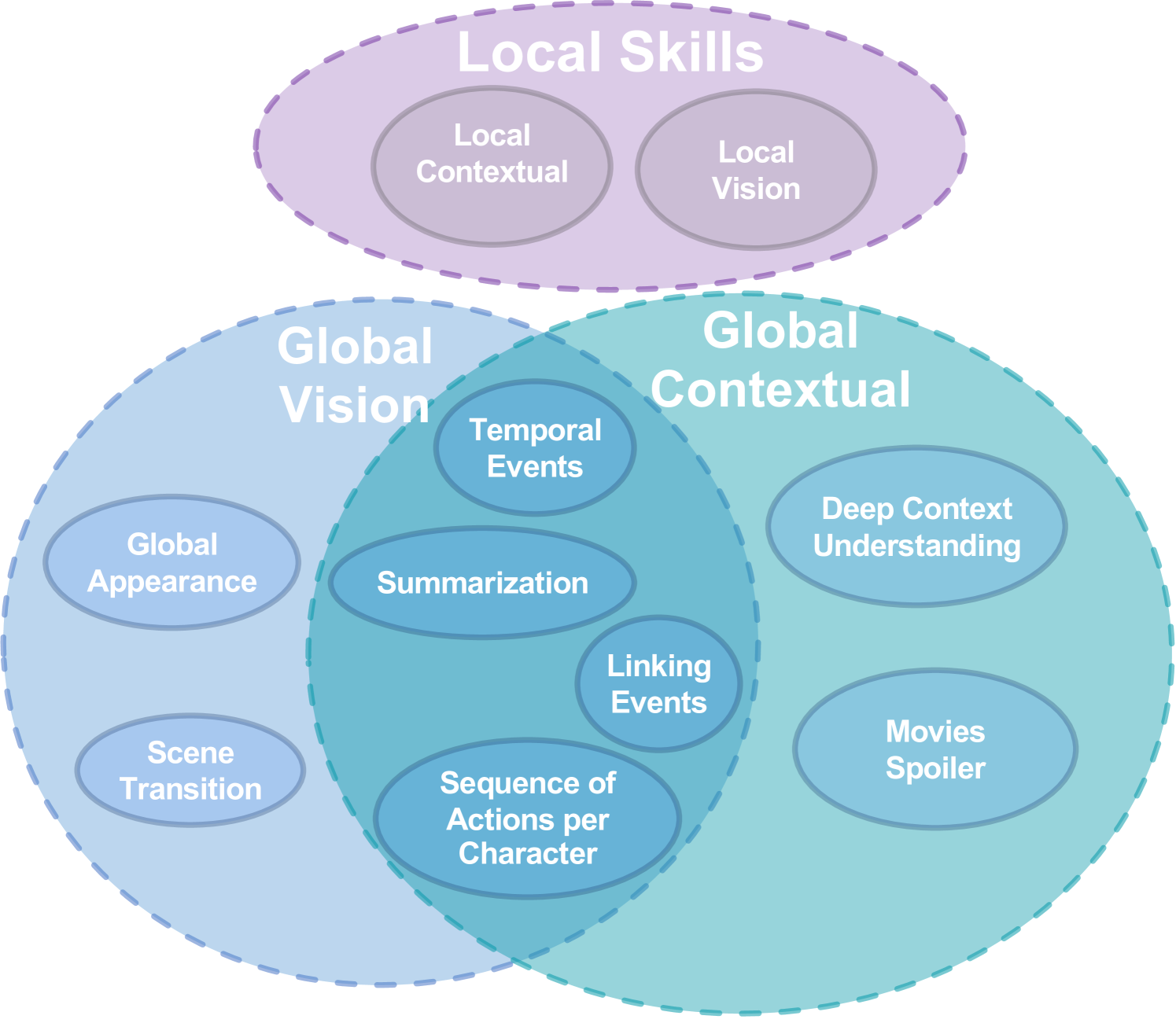
Understanding long videos, ranging from tens of minutes to several hours, presents unique challenges in video comprehension. Despite the increasing importance of long-form video content, existing benchmarks primarily focus on shorter clips. To address this gap, we introduce InfiniBench a comprehensive benchmark for very long video understanding which presents 1)The longest video duration, averaging 52.59 minutes per video 2) The largest number of question-answer pairs, 108.2K 3) Diversity in questions that examine nine different skills and include both multiple-choice questions and open-ended questions 4) Human-centric, as the video sources come from movies and daily TV shows, with specific human-level question designs such as Movie Spoiler Questions that require critical thinking and comprehensive understanding. Using InfiniBench, we comprehensively evaluate existing Large Multi-Modality Models (LMMs) on each skill, including the commercial models such as GPT-4o and Gemini 1.5 Flash and the open-source models. The evaluation shows significant challenges in our benchmark. Our findings reveal that even leading AI models like GPT-4o and Gemini 1.5 Flash face challenges in achieving high performance in long video understanding, with average accuracies of just 49.16% and 42.72%, and average scores of 3.22 and 2.71 out of 5, respectively. We hope this benchmark will stimulate the LMMs community towards long video and human-level understanding. Our benchmark can be accessed at https://vision-cair.github.io/InfiniBench/
Read more9/4/2024