LVBench: An Extreme Long Video Understanding Benchmark
2406.08035
0
0

Abstract
Recent progress in multimodal large language models has markedly enhanced the understanding of short videos (typically under one minute), and several evaluation datasets have emerged accordingly. However, these advancements fall short of meeting the demands of real-world applications such as embodied intelligence for long-term decision-making, in-depth movie reviews and discussions, and live sports commentary, all of which require comprehension of long videos spanning several hours. To address this gap, we introduce LVBench, a benchmark specifically designed for long video understanding. Our dataset comprises publicly sourced videos and encompasses a diverse set of tasks aimed at long video comprehension and information extraction. LVBench is designed to challenge multimodal models to demonstrate long-term memory and extended comprehension capabilities. Our extensive evaluations reveal that current multimodal models still underperform on these demanding long video understanding tasks. Through LVBench, we aim to spur the development of more advanced models capable of tackling the complexities of long video comprehension. Our data and code are publicly available at: https://lvbench.github.io.
Create account to get full access
Overview
• This research paper introduces LVBench, a comprehensive benchmark for evaluating the performance of long video understanding models.
• The benchmark covers a wide range of challenging tasks, such as multi-modal event detection, video summarization, and visual question answering, all within the context of extremely long videos.
• LVBench is designed to push the boundaries of current video understanding capabilities and drive advancements in this rapidly evolving field.
Plain English Explanation
The researchers behind this paper have created a new benchmark called LVBench to test the abilities of AI systems when it comes to understanding extremely long videos. These videos can be hours or even days long, and contain a wealth of information that can be challenging for machines to process and comprehend.
The benchmark includes a variety of tasks, such as identifying important events in the video, summarizing the key points, and answering questions about the content. By tackling these challenges, the researchers hope to push the limits of what current video understanding models are capable of and inspire new innovations in this field.
Compared to MVBench, MLVU, and other existing benchmarks, LVBench focuses specifically on extremely long videos, which are becoming increasingly relevant as video content continues to grow in length and complexity.
Technical Explanation
The LVBench dataset contains a diverse collection of videos, ranging from professional broadcasts to user-generated content, with durations of up to several days. The researchers have carefully curated and annotated this dataset to support a wide range of video understanding tasks, including:
- Multi-modal event detection: Identifying significant events within the video by leveraging both visual and textual cues.
- Video summarization: Generating concise summaries that capture the key highlights and storylines.
- Visual question answering: Answering questions about the video's content, requiring a deep understanding of the visual and temporal information.
The benchmark is designed to push the boundaries of current video understanding models, which have traditionally struggled with extremely long and complex video inputs. By including these challenging tasks, the researchers aim to spur the development of more robust and versatile AI systems that can handle the complexities of real-world video data.
Critical Analysis
While LVBench represents a significant step forward in video understanding benchmarking, the researchers acknowledge several limitations and potential areas for further research.
One key challenge is the scalability of the models, as processing hours or even days of video content can be computationally intensive. The researchers suggest exploring more efficient architectures, such as those found in LongVLM and Streaming Long Video Understanding, to address this issue.
Additionally, the researchers note that the current dataset may not fully capture the diversity of real-world video content, particularly in terms of cultural and linguistic representation. Expanding the dataset to include a broader range of video sources and perspectives could further strengthen the benchmark and its ability to assess the generalization capabilities of video understanding models.
Conclusion
The LVBench benchmark represents a significant advancement in the field of video understanding, providing a comprehensive and challenging platform for evaluating the performance of AI systems on extremely long video content. By pushing the boundaries of current capabilities, this research aims to inspire the development of more robust and versatile video understanding models, with potential applications in areas such as media analysis, surveillance, and educational content curation.
The insights gained from LVBench could also inform the design of future memory-augmented large multimodal models that are better equipped to handle the complexities of long-form video data, ultimately contributing to the broader progress of video understanding technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, Kai Chen
0
0
The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, we introduce MMBench-Video, a quantitative benchmark designed to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy. We employ GPT-4 for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, we have conducted comprehensive evaluations that include both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding. The evalutation code of MMBench-Video will be integrated into VLMEvalKit: https://github.com/open-compass/VLMEvalKit.
6/21/2024
New!InfiniBench: A Comprehensive Benchmark for Large Multimodal Models in Very Long Video Understanding
Kirolos Ataallah, Chenhui Gou, Eslam Abdelrahman, Khushbu Pahwa, Jian Ding, Mohamed Elhoseiny
0
0
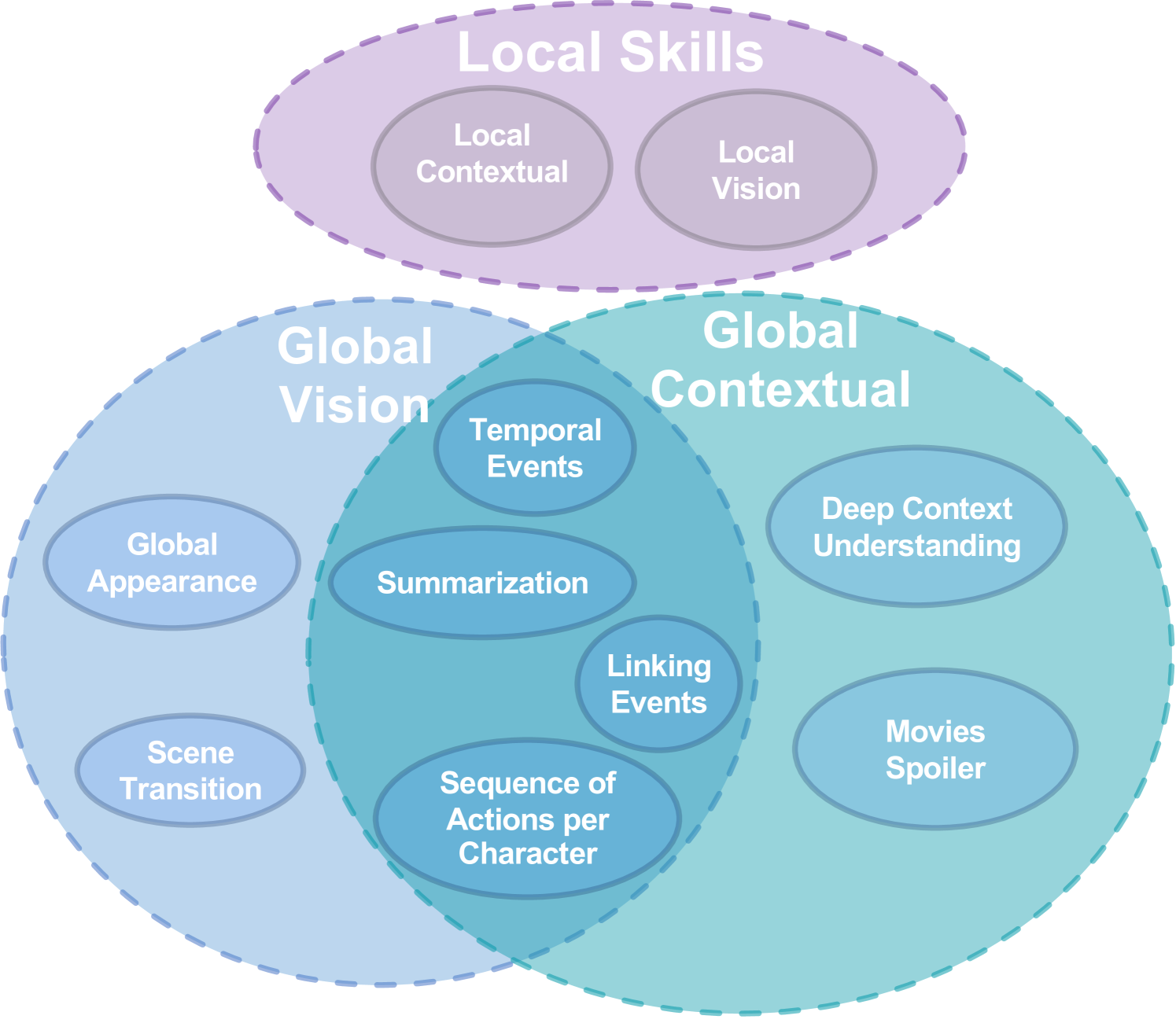
Understanding long videos, ranging from tens of minutes to several hours, presents unique challenges in video comprehension. Despite the increasing importance of long-form video content, existing benchmarks primarily focus on shorter clips. To address this gap, we introduce InfiniBench a comprehensive benchmark for very long video understanding which presents 1)The longest video duration, averaging 76.34 minutes; 2) The largest number of question-answer pairs, 108.2K; 3) Diversity in questions that examine nine different skills and include both multiple-choice questions and open-ended questions; 4) Humancentric, as the video sources come from movies and daily TV shows, with specific human-level question designs such as Movie Spoiler Questions that require critical thinking and comprehensive understanding. Using InfiniBench, we comprehensively evaluate existing Large MultiModality Models (LMMs) on each skill, including the commercial model Gemini 1.5 Flash and the open-source models. The evaluation shows significant challenges in our benchmark.Our results show that the best AI models such Gemini struggles to perform well with 42.72% average accuracy and 2.71 out of 5 average score. We hope this benchmark will stimulate the LMMs community towards long video and human-level understanding. Our benchmark can be accessed at https://vision-cair.github.io/InfiniBench/
7/1/2024
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
0
0
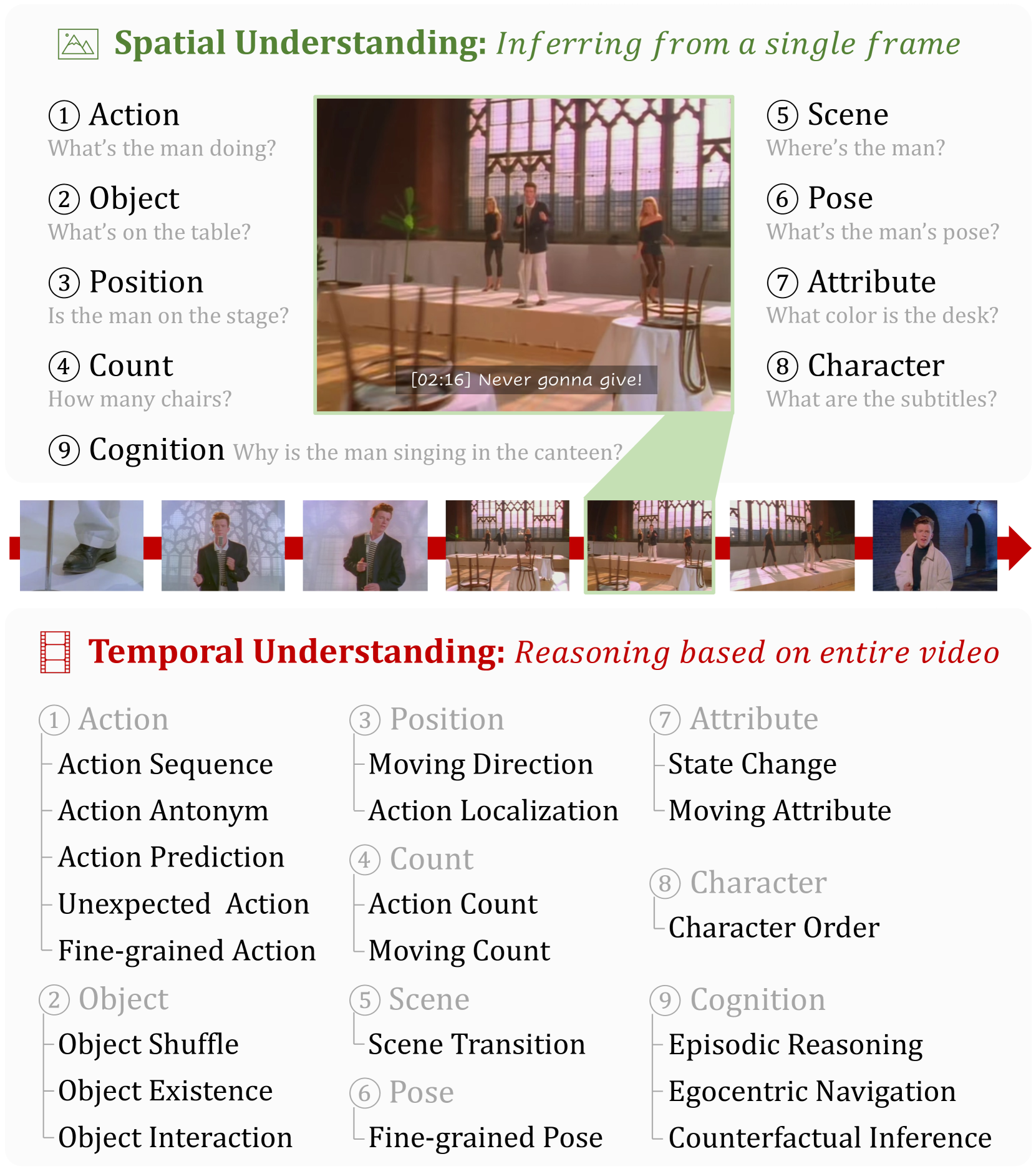
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
5/24/2024
MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, Zheng Liu
0
0
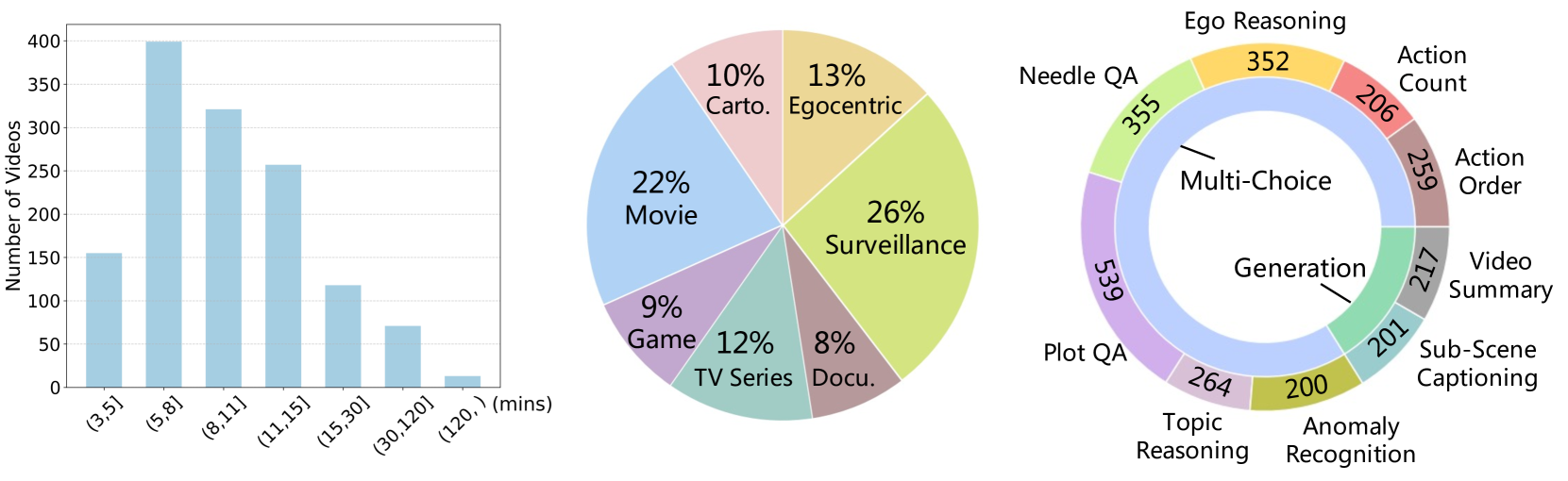
The evaluation of Long Video Understanding (LVU) performance poses an important but challenging research problem. Despite previous efforts, the existing video understanding benchmarks are severely constrained by several issues, especially the insufficient lengths of videos, a lack of diversity in video types and evaluation tasks, and the inappropriateness for evaluating LVU performances. To address the above problems, we propose a new benchmark, called MLVU (Multi-task Long Video Understanding Benchmark), for the comprehensive and in-depth evaluation of LVU. MLVU presents the following critical values: 1) The substantial and flexible extension of video lengths, which enables the benchmark to evaluate LVU performance across a wide range of durations. 2) The inclusion of various video genres, e.g., movies, surveillance footage, egocentric videos, cartoons, game videos, etc., which reflects the models' LVU performances in different scenarios. 3) The development of diversified evaluation tasks, which enables a comprehensive examination of MLLMs' key abilities in long-video understanding. The empirical study with 20 latest MLLMs reveals significant room for improvement in today's technique, as all existing methods struggle with most of the evaluation tasks and exhibit severe performance degradation when handling longer videos. Additionally, it suggests that factors such as context length, image-understanding quality, and the choice of LLM backbone can play critical roles in future advancements. We anticipate that MLVU will advance the research of long video understanding by providing a comprehensive and in-depth analysis of MLLMs.
6/21/2024