LoRA+: Efficient Low Rank Adaptation of Large Models

130
📶
Sign in to get full access
Overview
- The paper shows that Low Rank Adaptation (LoRA) as originally introduced leads to suboptimal finetuning of large models
- This is due to the fact that the adapter matrices A and B in LoRA are updated with the same learning rate
- The authors demonstrate that using different learning rates for A and B can significantly improve performance and finetuning speed, at the same computational cost as LoRA
Plain English Explanation
The paper discusses an issue with a machine learning technique called Low Rank Adaptation (LoRA). LoRA is a way to efficiently finetune large AI models on specific tasks without having to update all the model's parameters.
However, the researchers found that the original LoRA approach doesn't work as well for models with large "width" (i.e. large embedding dimensions). This is because LoRA updates two adapter matrices, A and B, with the same learning rate during finetuning.
Through mathematical analysis, the authors show that using the same learning rate for A and B doesn't allow the model to learn features efficiently in large-width networks. To fix this, they propose a simple modification called LoRA+, which uses different learning rates for A and B.
In their experiments, LoRA+ was able to improve performance by 1-2% and speed up finetuning by up to 2x, compared to the original LoRA, all while maintaining the same computational cost. So LoRA+ provides an easy way to get better results when finetuning large AI models using the LoRA technique.
Technical Explanation
The key insight in this paper is that the original LoRA approach [1] leads to suboptimal finetuning of models with large embedding dimensions (width). This is due to the fact that the two adapter matrices A and B in LoRA are updated with the same learning rate during the finetuning process.
Using scaling arguments for large-width networks, the authors demonstrate that using the same learning rate for A and B does not allow efficient feature learning. Intuitively, this is because the magnitudes of the updates to A and B need to be balanced in a specific way to capture the most important features.
To address this suboptimality, the authors propose a simple modification called LoRA+, which uses different learning rates for the adapter matrices A and B, with a well-chosen ratio. This allows the model to learn features more effectively during finetuning.
In their extensive experiments on a variety of tasks and model sizes, the authors show that LoRA+ consistently outperforms the original LoRA approach, with 1-2% improvements in performance and up to 2x speedups in finetuning, all at the same computational cost.
Critical Analysis
The paper provides a clear and insightful analysis of a limitation in the original LoRA approach, and proposes a simple yet effective solution in the form of LoRA+. The authors' use of scaling arguments to understand the underlying issue is particularly impressive.
One potential area for further research could be to investigate whether there are other ways to adaptively adjust the learning rates for A and B, beyond the fixed ratio used in LoRA+. This could potentially lead to even greater performance gains.
Additionally, the authors only consider the case of finetuning large models. It would be interesting to see if their findings also hold for the case of training smaller models from scratch using LoRA.
Overall, this paper makes a valuable contribution to the field of efficient model adaptation, and the LoRA+ approach seems like a promising technique for practitioners to consider when finetuning large AI models.
Conclusion
This paper identifies a key limitation in the original LoRA approach for finetuning large AI models, and proposes a simple yet effective solution called LoRA+. By using different learning rates for the LoRA adapter matrices, LoRA+ is able to significantly improve performance and finetuning speed, without increasing the computational cost.
The insights and techniques presented in this work have important implications for researchers and practitioners looking to efficiently adapt large language models and other high-capacity neural networks to specific tasks. The LoRA+ approach provides a practical and effective way to unlock the full potential of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024
📊
0
LoRA-Pro: Are Low-Rank Adapters Properly Optimized?
Zhengbo Wang, Jian Liang
Low-Rank Adaptation, also known as LoRA, has emerged as a prominent method for parameter-efficient fine-tuning foundation models by re-parameterizing the original matrix into the product of two low-rank matrices. Despite its efficiency, LoRA often yields inferior performance compared to full fine-tuning. In this paper, we propose LoRA-Pro to bridge this performance gap. Firstly, we delve into the optimization processes in LoRA and full fine-tuning. We reveal that while LoRA employs low-rank approximation, it neglects to approximate the optimization process of full fine-tuning. To address this, we introduce a novel concept called the equivalent gradient. This virtual gradient makes the optimization process on the re-parameterized matrix equivalent to LoRA, which can be used to quantify the differences between LoRA and full fine-tuning. The equivalent gradient is derived from the gradients of matrices $A$ and $B$. To narrow the performance gap, our approach minimizes the differences between the equivalent gradient and the gradient obtained from full fine-tuning during the optimization process. By solving this objective, we derive optimal closed-form solutions for updating matrices $A$ and $B$. Our method constrains the optimization process, shrinking the performance gap between LoRA and full fine-tuning. Extensive experiments on natural language processing tasks validate the effectiveness of our method.
Read more7/26/2024
123
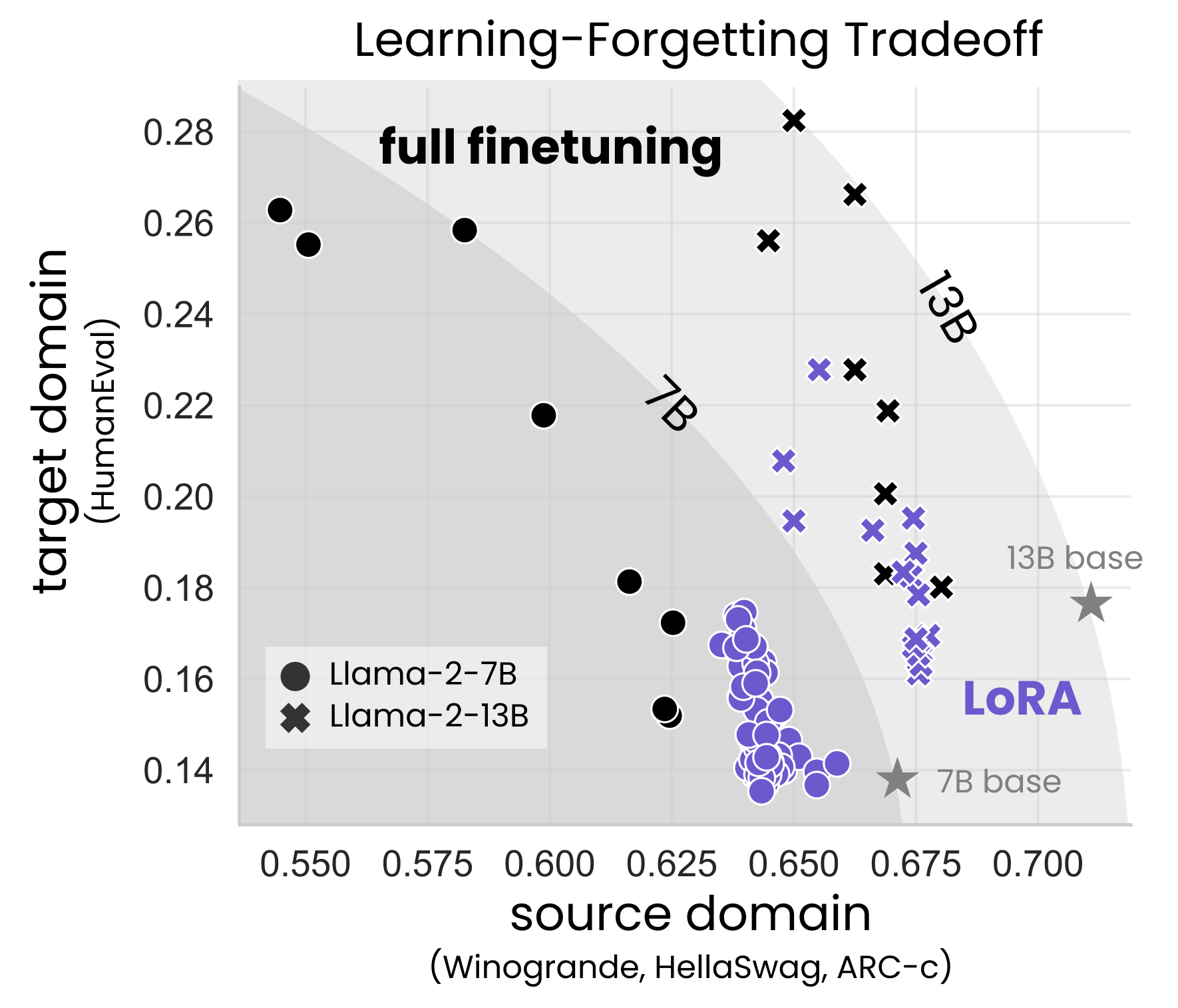
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
Read more5/17/2024