LoRA-Pro: Are Low-Rank Adapters Properly Optimized?

0
📊
Sign in to get full access
Overview
- The paper investigates whether low-rank adapters (LoRA) are properly optimized.
- LoRA is a technique for fine-tuning large language models by adding a small number of trainable parameters.
- The authors propose "LoRA-Pro," a new LoRA optimization method that aims to improve performance.
Plain English Explanation
In machine learning, there is a technique called low-rank adapters (LoRA) that allows you to fine-tune large language models like GPT-3 by only adding a small number of trainable parameters. This is useful because it can save a lot of time and computing resources compared to fine-tuning the entire model.
However, the authors of this paper wondered if the standard LoRA optimization method is really the best way to train these low-rank adapters. They propose a new method called "LoRA-Pro" that they believe can improve the performance of LoRA. The key idea behind LoRA-Pro is to better optimize the low-rank adapter parameters during training.
Technical Explanation
The paper first reviews related work on LoRA and other low-rank adaptation techniques. It then describes the LoRA-Pro method, which introduces a new optimization strategy for training the low-rank adapters.
Specifically, LoRA-Pro uses a batched optimization approach to update the adapter parameters more efficiently. It also incorporates an orthonormal constraint on the adapter weights to improve performance.
The authors evaluate LoRA-Pro on several language modeling benchmarks and find that it outperforms the standard LoRA method, particularly in low-resource settings. They attribute this improvement to the better optimization of the adapter parameters enabled by their proposed techniques.
Critical Analysis
The paper provides a thorough technical explanation of the LoRA-Pro method and its potential advantages over standard LoRA. However, the authors do not discuss any major limitations or caveats of their approach.
One potential concern is that the increased complexity of the LoRA-Pro optimization may make it more computationally expensive or difficult to implement compared to standard LoRA. The authors could have addressed this issue or provided guidance on the tradeoffs involved.
Additionally, the paper focuses solely on language modeling tasks and does not explore how LoRA-Pro might perform on other types of machine learning problems. Further research would be needed to assess the generalizability of their findings.
Conclusion
Overall, this paper presents a promising new optimization method for low-rank adapters that could lead to improved performance on language modeling tasks. While the technical details are complex, the authors do a good job of explaining the core ideas in an accessible way.
The findings suggest that the standard LoRA optimization may not be fully optimized, and that further improvements are possible. The LoRA-Pro method appears to be a step in the right direction, but more research is needed to fully understand its strengths, weaknesses, and potential applications across a wider range of machine learning domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
LoRA-Pro: Are Low-Rank Adapters Properly Optimized?
Zhengbo Wang, Jian Liang
Low-Rank Adaptation, also known as LoRA, has emerged as a prominent method for parameter-efficient fine-tuning foundation models by re-parameterizing the original matrix into the product of two low-rank matrices. Despite its efficiency, LoRA often yields inferior performance compared to full fine-tuning. In this paper, we propose LoRA-Pro to bridge this performance gap. Firstly, we delve into the optimization processes in LoRA and full fine-tuning. We reveal that while LoRA employs low-rank approximation, it neglects to approximate the optimization process of full fine-tuning. To address this, we introduce a novel concept called the equivalent gradient. This virtual gradient makes the optimization process on the re-parameterized matrix equivalent to LoRA, which can be used to quantify the differences between LoRA and full fine-tuning. The equivalent gradient is derived from the gradients of matrices $A$ and $B$. To narrow the performance gap, our approach minimizes the differences between the equivalent gradient and the gradient obtained from full fine-tuning during the optimization process. By solving this objective, we derive optimal closed-form solutions for updating matrices $A$ and $B$. Our method constrains the optimization process, shrinking the performance gap between LoRA and full fine-tuning. Extensive experiments on natural language processing tasks validate the effectiveness of our method.
Read more7/26/2024
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024

0
LoRA-GA: Low-Rank Adaptation with Gradient Approximation
Shaowen Wang, Linxi Yu, Jian Li
Fine-tuning large-scale pretrained models is prohibitively expensive in terms of computational and memory costs. LoRA, as one of the most popular Parameter-Efficient Fine-Tuning (PEFT) methods, offers a cost-effective alternative by fine-tuning an auxiliary low-rank model that has significantly fewer parameters. Although LoRA reduces the computational and memory requirements significantly at each iteration, extensive empirical evidence indicates that it converges at a considerably slower rate compared to full fine-tuning, ultimately leading to increased overall compute and often worse test performance. In our paper, we perform an in-depth investigation of the initialization method of LoRA and show that careful initialization (without any change of the architecture and the training algorithm) can significantly enhance both efficiency and performance. In particular, we introduce a novel initialization method, LoRA-GA (Low Rank Adaptation with Gradient Approximation), which aligns the gradients of low-rank matrix product with those of full fine-tuning at the first step. Our extensive experiments demonstrate that LoRA-GA achieves a convergence rate comparable to that of full fine-tuning (hence being significantly faster than vanilla LoRA as well as various recent improvements) while simultaneously attaining comparable or even better performance. For example, on the subset of the GLUE dataset with T5-Base, LoRA-GA outperforms LoRA by 5.69% on average. On larger models such as Llama 2-7B, LoRA-GA shows performance improvements of 0.34, 11.52%, and 5.05% on MT-bench, GSM8K, and Human-eval, respectively. Additionally, we observe up to 2-4 times convergence speed improvement compared to vanilla LoRA, validating its effectiveness in accelerating convergence and enhancing model performance. Code is available at https://github.com/Outsider565/LoRA-GA.
Read more7/17/2024
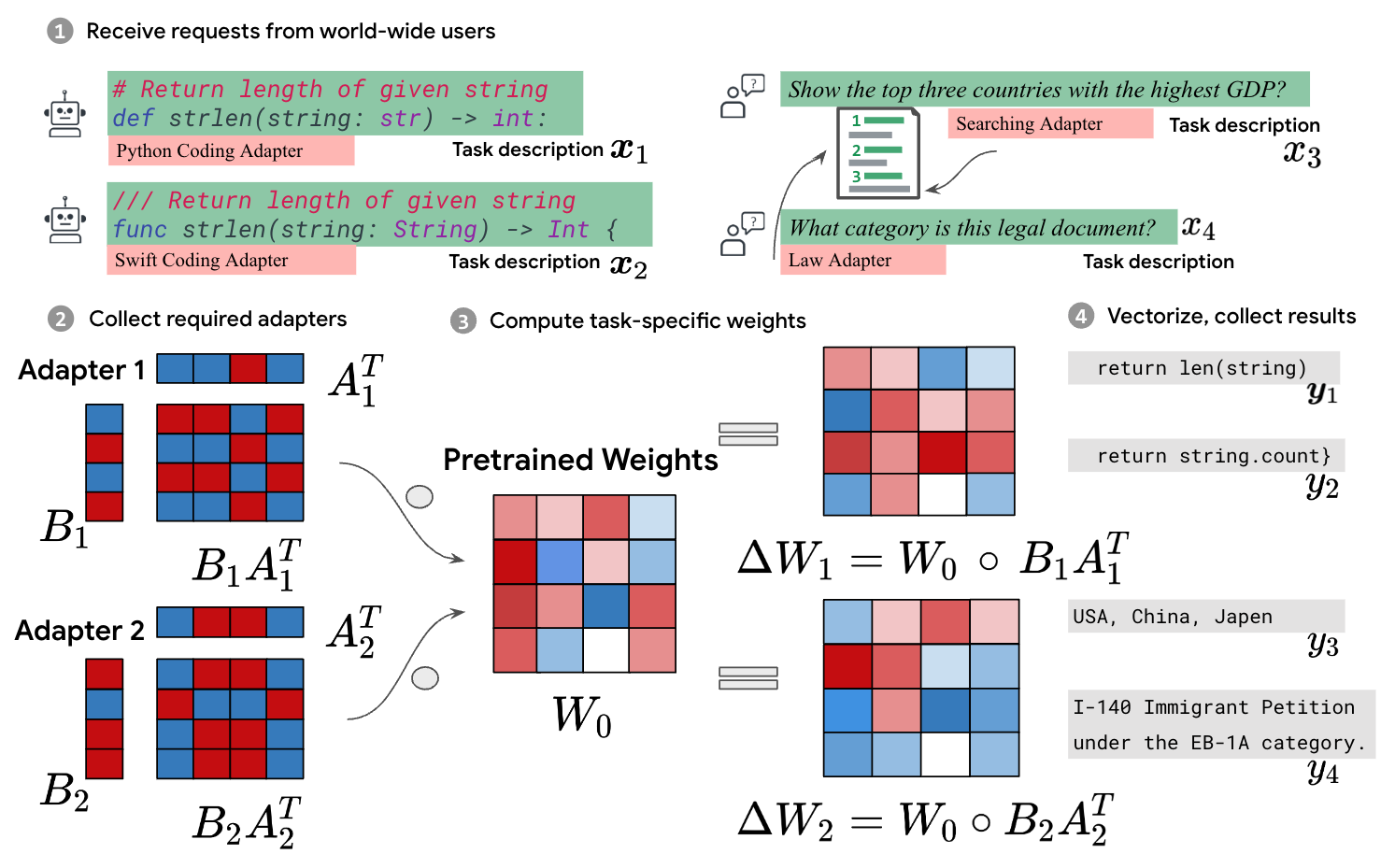
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024