LoSh: Long-Short Text Joint Prediction Network for Referring Video Object Segmentation

0
🔮
Sign in to get full access
Overview
- This paper introduces LoSh, a neural network for referring video object segmentation.
- LoSh jointly predicts long-term and short-term information to accurately identify target objects in videos based on natural language descriptions.
- The key innovations are the use of long-term and short-term text and visual feature representations, and a joint prediction network that leverages these complementary signals.
Plain English Explanation
LoSh is a new AI system that can watch videos and understand what objects in the video a person is referring to, based on how the person describes the object in natural language. This is a challenging task because the target object might change over time in the video, and the language description could focus on different aspects of the object.
LoSh tackles this problem by using two different ways of representing the video and text information. It extracts both long-term features, which capture the overall context and appearance of the object over the whole video, as well as short-term features that focus on the object's appearance in the current video frame. By combining these complementary representations in a joint prediction network, LoSh can accurately identify the target object even as it changes over time in the video.
This approach allows LoSh to understand complex natural language descriptions of objects in videos, going beyond simple object detection to truly comprehend the user's intent. This could enable more natural and powerful video analysis tools for applications like video search, virtual assistants, and augmented reality.
Technical Explanation
The key technical components of LoSh are:
-
Long-term and short-term text and visual feature extraction: LoSh uses separate neural networks to extract high-level semantic features from the video frames and the language description. This includes both long-term features that capture the overall context, as well as short-term features that focus on the current frame.
-
Joint prediction network: LoSh combines the long-term and short-term text and visual features in a neural network that jointly predicts the target object segmentation mask. This allows LoSh to reason about the alignment between the language and visual inputs over both long and short timescales.
-
Training and inference: LoSh is trained end-to-end on a dataset of videos with natural language descriptions of target objects. At inference time, LoSh takes a new video and language input and outputs a segmentation mask identifying the described object.
The experiments show that LoSh outperforms prior work on referring video object segmentation benchmarks. The analysis indicates that the long-term and short-term feature representations are complementary and both contribute to LoSh's strong performance.
Critical Analysis
The paper provides a thorough evaluation of LoSh, including analysis of the computation cost, model ablations, and comparisons to state-of-the-art methods. However, some potential limitations and areas for future work are not discussed:
-
The reliance on separate networks for long-term and short-term feature extraction may limit the model's ability to dynamically focus on relevant temporal scales. A more integrated architecture could potentially improve efficiency and performance.
-
The experiments are conducted on relatively short videos (around 100 frames). It is unclear how well LoSh would scale to much longer videos encountered in real-world applications.
-
The paper does not address potential biases or failure modes of the system, such as how LoSh would perform on ambiguous or adversarial language descriptions.
Further research exploring these aspects could help strengthen the LoSh framework and understand its real-world applicability and limitations.
Conclusion
LoSh presents a novel approach to referring video object segmentation that leverages complementary long-term and short-term visual and language representations. By jointly predicting the target object, LoSh demonstrates state-of-the-art performance on benchmark datasets.
This work advances the field of video understanding by enabling more natural and contextual interactions between humans and AI systems. The ability to accurately identify objects in videos based on language descriptions has a wide range of potential applications, from video search and virtual assistants to augmented reality and beyond.
While the current LoSh model shows promising results, further research is needed to fully explore its scalability, robustness, and real-world applicability. Nonetheless, this paper represents an important step forward in bridging the gap between language and vision for video-based tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
LoSh: Long-Short Text Joint Prediction Network for Referring Video Object Segmentation
Linfeng Yuan, Miaojing Shi, Zijie Yue, Qijun Chen
Referring video object segmentation (RVOS) aims to segment the target instance referred by a given text expression in a video clip. The text expression normally contains sophisticated description of the instance's appearance, action, and relation with others. It is therefore rather difficult for a RVOS model to capture all these attributes correspondingly in the video; in fact, the model often favours more on the action- and relation-related visual attributes of the instance. This can end up with partial or even incorrect mask prediction of the target instance. We tackle this problem by taking a subject-centric short text expression from the original long text expression. The short one retains only the appearance-related information of the target instance so that we can use it to focus the model's attention on the instance's appearance. We let the model make joint predictions using both long and short text expressions; and insert a long-short cross-attention module to interact the joint features and a long-short predictions intersection loss to regulate the joint predictions. Besides the improvement on the linguistic part, we also introduce a forward-backward visual consistency loss, which utilizes optical flows to warp visual features between the annotated frames and their temporal neighbors for consistency. We build our method on top of two state of the art pipelines. Extensive experiments on A2D-Sentences, Refer-YouTube-VOS, JHMDB-Sentences and Refer-DAVIS17 show impressive improvements of our method.Code is available at https://github.com/LinfengYuan1997/Losh.
Read more4/3/2024
0
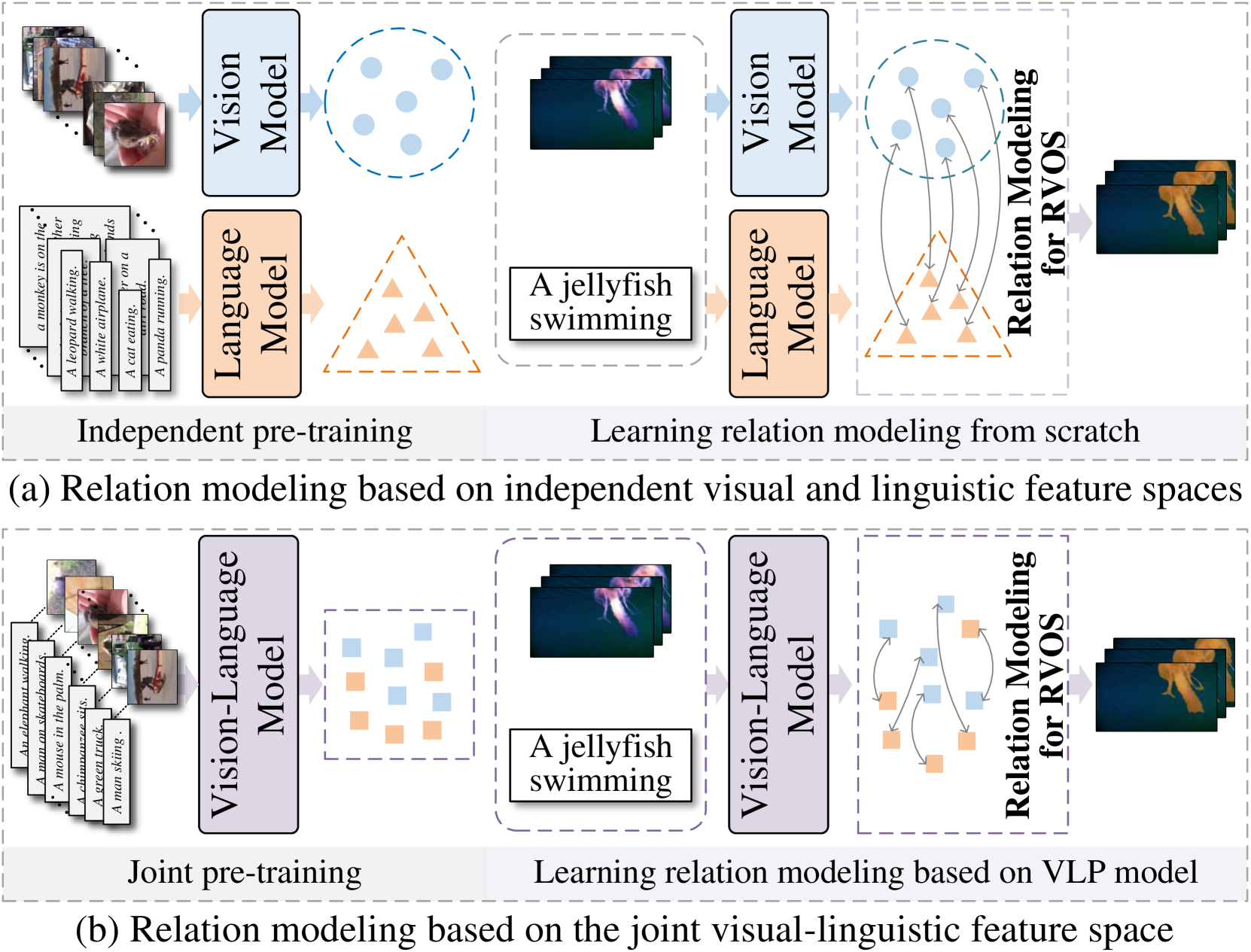
Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models
Zikun Zhou, Wentao Xiong, Li Zhou, Xin Li, Zhenyu He, Yaowei Wang
The crux of Referring Video Object Segmentation (RVOS) lies in modeling dense text-video relations to associate abstract linguistic concepts with dynamic visual contents at pixel-level. Current RVOS methods typically use vision and language models pre-trained independently as backbones. As images and texts are mapped to uncoupled feature spaces, they face the arduous task of learning Vision-Language~(VL) relation modeling from scratch. Witnessing the success of Vision-Language Pre-trained (VLP) models, we propose to learn relation modeling for RVOS based on their aligned VL feature space. Nevertheless, transferring VLP models to RVOS is a deceptively challenging task due to the substantial gap between the pre-training task (image/region-level prediction) and the RVOS task (pixel-level prediction in videos). In this work, we introduce a framework named VLP-RVOS to address this transfer challenge. We first propose a temporal-aware prompt-tuning method, which not only adapts pre-trained representations for pixel-level prediction but also empowers the vision encoder to model temporal clues. We further propose to perform multi-stage VL relation modeling while and after feature extraction for comprehensive VL understanding. Besides, we customize a cube-frame attention mechanism for spatial-temporal reasoning. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms and exhibits strong generalization abilities.
Read more5/20/2024

0
UNINEXT-Cutie: The 1st Solution for LSVOS Challenge RVOS Track
Hao Fang, Feiyu Pan, Xiankai Lu, Wei Zhang, Runmin Cong
Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video. In this year, LSVOS Challenge RVOS Track replaced the origin YouTube-RVOS benchmark with MeViS. MeViS focuses on referring the target object in a video through its motion descriptions instead of static attributes, posing a greater challenge to RVOS task. In this work, we integrate strengths of that leading RVOS and VOS models to build up a simple and effective pipeline for RVOS. Firstly, We finetune the state-of-the-art RVOS model to obtain mask sequences that are correlated with language descriptions. Secondly, based on a reliable and high-quality key frames, we leverage VOS model to enhance the quality and temporal consistency of the mask results. Finally, we further improve the performance of the RVOS model using semi-supervised learning. Our solution achieved 62.57 J&F on the MeViS test set and ranked 1st place for 6th LSVOS Challenge RVOS Track.
Read more8/27/2024

0
The Instance-centric Transformer for the RVOS Track of LSVOS Challenge: 3rd Place Solution
Bin Cao, Yisi Zhang, Hanyi Wang, Xingjian He, Jing Liu
Referring Video Object Segmentation is an emerging multi-modal task that aims to segment objects in the video given a natural language expression. In this work, we build two instance-centric models and fuse predicted results from frame-level and instance-level. First, we introduce instance mask into the DETR-based model for query initialization to achieve temporal enhancement and employ SAM for spatial refinement. Secondly, we build an instance retrieval model conducting binary instance mask classification whether the instance is referred. Finally, we fuse predicted results and our method achieved a score of 52.67 J&F in the validation phase and 60.36 J&F in the test phase, securing the final ranking of 3rd place in the 6-th LSVOS Challenge RVOS Track.
Read more8/21/2024