Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models

0
Sign in to get full access
Overview
- Referring video object segmentation using vision-language pre-trained models
- Leveraging temporal modeling and vision-language relation modeling for improved performance
- Potential applications in video editing, surveillance, and autonomous systems
Plain English Explanation
This paper explores a technique called "referring video object segmentation" that allows computers to identify and outline specific objects in video footage based on textual descriptions or "referring expressions." The researchers used pre-trained vision-language models as a starting point, then added additional components to improve the model's ability to understand the relationship between the visual elements in the video and the language used to describe them.
By modeling the temporal dynamics of the video and the interaction between the visual and linguistic information, the researchers were able to create a system that can accurately select and segment the object being referred to, even in complex, dynamic scenes. This could have applications in areas like video editing, where users could easily isolate and manipulate specific elements, or in autonomous systems like self-driving cars, where the ability to understand and interact with the environment is crucial.
The key innovation here is the way the model integrates the visual and linguistic information, going beyond simply matching keywords to pixels. By learning the underlying relationships between the two, the system can better understand the intent behind the referring expression and apply that knowledge to the video in a more sophisticated way.
Technical Explanation
The researchers built their system on top of pre-trained vision-language models that had been trained on large datasets to learn the connections between images and text. They then added two key components:
-
Temporal Modeling: To capture the dynamic nature of video, the researchers incorporated temporal modeling into the architecture, allowing the system to understand how the scene and the referred object evolve over time.
-
Vision-Language Relation Modeling: The researchers also developed a module to explicitly model the relationship between the visual elements in the video and the linguistic referring expression. This helps the system better understand the intent behind the language and apply it to the appropriate parts of the video.
These additions to the base vision-language model resulted in significant performance improvements on standard referring video object segmentation benchmarks, demonstrating the value of the proposed approach.
Critical Analysis
The researchers acknowledge several limitations in their work, such as the reliance on pre-trained models and the potential for performance degradation in complex or ambiguous scenes. Additionally, the model's dependence on temporal information means it may not perform as well on static images or short video clips.
Furthermore, the paper does not address potential biases or fairness concerns that may arise from the use of large-scale pre-trained models, which can sometimes reflect societal biases present in the training data. This is an important consideration for real-world applications of this technology.
Despite these limitations, the core ideas presented in the paper represent a meaningful advance in the field of referring video object segmentation. By effectively combining temporal and vision-language modeling, the researchers have demonstrated a path forward for building more robust and versatile systems for interacting with dynamic visual content.
Conclusion
This paper introduces a novel approach to referring video object segmentation that leverages the power of pre-trained vision-language models and enhances them with temporal modeling and explicit vision-language relation modeling. The resulting system shows improved performance on standard benchmarks, suggesting its potential for applications in areas like video editing, surveillance, and autonomous systems.
While the research has some limitations, it represents an important step forward in the field of vision-language understanding for dynamic visual content. By continuing to explore the synergies between visual and linguistic information, researchers can unlock new possibilities for intuitive and intelligent interaction with the rich, ever-changing world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models
Zikun Zhou, Wentao Xiong, Li Zhou, Xin Li, Zhenyu He, Yaowei Wang
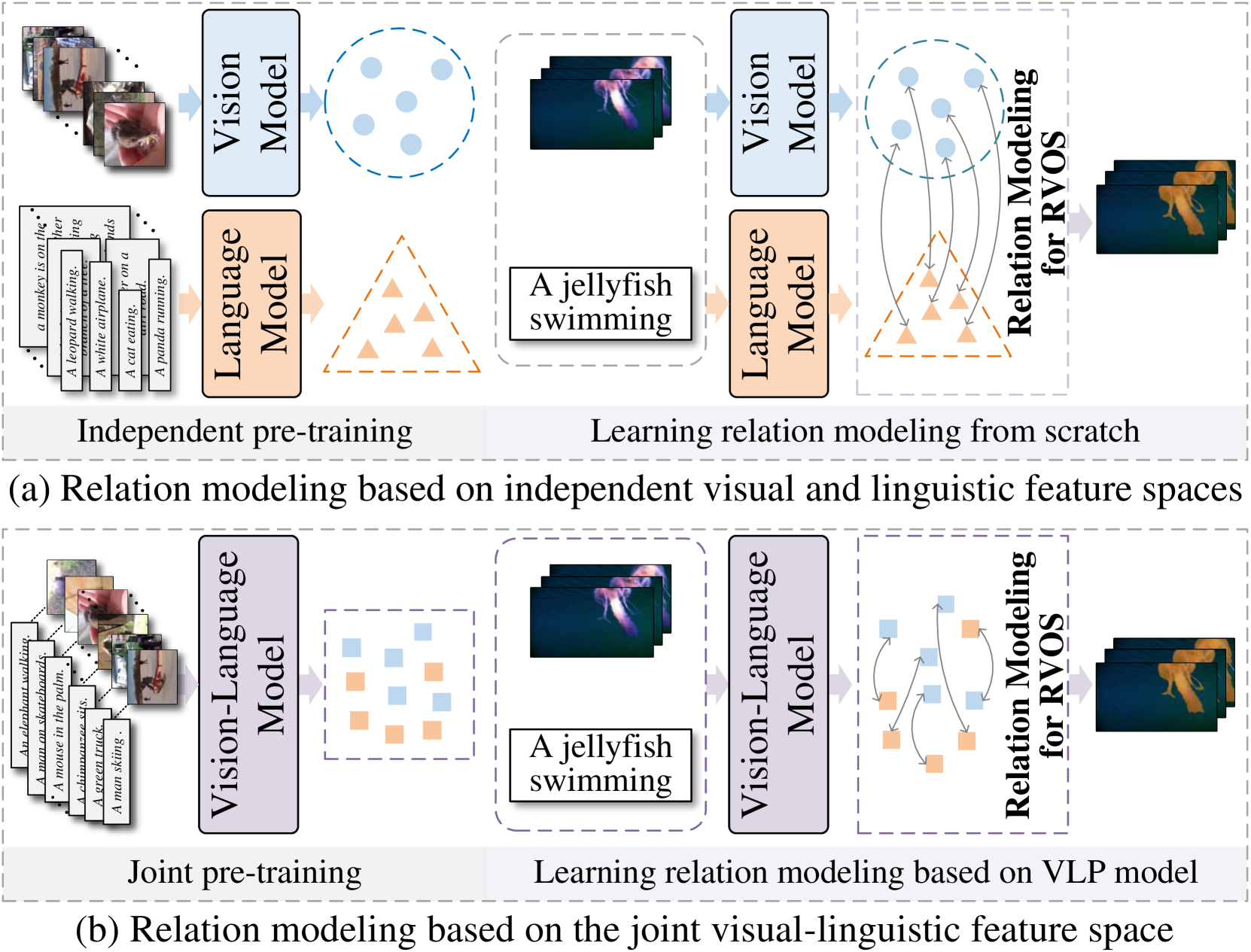
The crux of Referring Video Object Segmentation (RVOS) lies in modeling dense text-video relations to associate abstract linguistic concepts with dynamic visual contents at pixel-level. Current RVOS methods typically use vision and language models pre-trained independently as backbones. As images and texts are mapped to uncoupled feature spaces, they face the arduous task of learning Vision-Language~(VL) relation modeling from scratch. Witnessing the success of Vision-Language Pre-trained (VLP) models, we propose to learn relation modeling for RVOS based on their aligned VL feature space. Nevertheless, transferring VLP models to RVOS is a deceptively challenging task due to the substantial gap between the pre-training task (image/region-level prediction) and the RVOS task (pixel-level prediction in videos). In this work, we introduce a framework named VLP-RVOS to address this transfer challenge. We first propose a temporal-aware prompt-tuning method, which not only adapts pre-trained representations for pixel-level prediction but also empowers the vision encoder to model temporal clues. We further propose to perform multi-stage VL relation modeling while and after feature extraction for comprehensive VL understanding. Besides, we customize a cube-frame attention mechanism for spatial-temporal reasoning. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms and exhibits strong generalization abilities.
Read more5/20/2024
🔮
0
LoSh: Long-Short Text Joint Prediction Network for Referring Video Object Segmentation
Linfeng Yuan, Miaojing Shi, Zijie Yue, Qijun Chen
Referring video object segmentation (RVOS) aims to segment the target instance referred by a given text expression in a video clip. The text expression normally contains sophisticated description of the instance's appearance, action, and relation with others. It is therefore rather difficult for a RVOS model to capture all these attributes correspondingly in the video; in fact, the model often favours more on the action- and relation-related visual attributes of the instance. This can end up with partial or even incorrect mask prediction of the target instance. We tackle this problem by taking a subject-centric short text expression from the original long text expression. The short one retains only the appearance-related information of the target instance so that we can use it to focus the model's attention on the instance's appearance. We let the model make joint predictions using both long and short text expressions; and insert a long-short cross-attention module to interact the joint features and a long-short predictions intersection loss to regulate the joint predictions. Besides the improvement on the linguistic part, we also introduce a forward-backward visual consistency loss, which utilizes optical flows to warp visual features between the annotated frames and their temporal neighbors for consistency. We build our method on top of two state of the art pipelines. Extensive experiments on A2D-Sentences, Refer-YouTube-VOS, JHMDB-Sentences and Refer-DAVIS17 show impressive improvements of our method.Code is available at https://github.com/LinfengYuan1997/Losh.
Read more4/3/2024

0
3rd Place Solution for MeViS Track in CVPR 2024 PVUW workshop: Motion Expression guided Video Segmentation
Feiyu Pan, Hao Fang, Xiankai Lu
Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video, emphasizing modeling dense text-video relations. The current RVOS methods typically use independently pre-trained vision and language models as backbones, resulting in a significant domain gap between video and text. In cross-modal feature interaction, text features are only used as query initialization and do not fully utilize important information in the text. In this work, we propose using frozen pre-trained vision-language models (VLM) as backbones, with a specific emphasis on enhancing cross-modal feature interaction. Firstly, we use frozen convolutional CLIP backbone to generate feature-aligned vision and text features, alleviating the issue of domain gap and reducing training costs. Secondly, we add more cross-modal feature fusion in the pipeline to enhance the utilization of multi-modal information. Furthermore, we propose a novel video query initialization method to generate higher quality video queries. Without bells and whistles, our method achieved 51.5 J&F on the MeViS test set and ranked 3rd place for MeViS Track in CVPR 2024 PVUW workshop: Motion Expression guided Video Segmentation.
Read more6/10/2024

0
UNINEXT-Cutie: The 1st Solution for LSVOS Challenge RVOS Track
Hao Fang, Feiyu Pan, Xiankai Lu, Wei Zhang, Runmin Cong
Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video. In this year, LSVOS Challenge RVOS Track replaced the origin YouTube-RVOS benchmark with MeViS. MeViS focuses on referring the target object in a video through its motion descriptions instead of static attributes, posing a greater challenge to RVOS task. In this work, we integrate strengths of that leading RVOS and VOS models to build up a simple and effective pipeline for RVOS. Firstly, We finetune the state-of-the-art RVOS model to obtain mask sequences that are correlated with language descriptions. Secondly, based on a reliable and high-quality key frames, we leverage VOS model to enhance the quality and temporal consistency of the mask results. Finally, we further improve the performance of the RVOS model using semi-supervised learning. Our solution achieved 62.57 J&F on the MeViS test set and ranked 1st place for 6th LSVOS Challenge RVOS Track.
Read more8/27/2024