Low-Complexity Acoustic Scene Classification Using Parallel Attention-Convolution Network

0
🏷️
Sign in to get full access
Overview
- Proposed a parallel attention-convolution network for low-complexity acoustic scene classification
- Integrated techniques like knowledge distillation, data augmentation, and adaptive residual normalization
- Achieved state-of-the-art performance on the DCASE2023 challenge dataset with high accuracy and low complexity
Plain English Explanation
The researchers developed an improved system for classifying audio environments, such as a city street or a library. Their method uses a neural network with a unique architecture that allows it to efficiently capture both global and local contextual information from the audio clips.
The network is designed to be computationally efficient, with a small number of parameters and low computational complexity. This makes it well-suited for deployment on devices with limited resources, like mobile phones or embedded systems.
The researchers also incorporated other techniques, such as knowledge distillation (where a smaller model is trained to mimic a larger, more accurate model) and data augmentation (where the training data is artificially expanded) to further improve the system's performance.
When evaluated on the official dataset for the DCASE2023 challenge, the researchers' method achieved the highest accuracy compared to other top-performing systems, while also having the lowest complexity in terms of the number of parameters and computational operations.
Technical Explanation
The proposed system is a parallel attention-convolution network that consists of four main modules: pre-processing, fusion, global contextual information extraction, and local contextual information extraction.
The pre-processing module applies various data augmentation techniques to the input audio clips, such as time stretching, pitch shifting, and mixup. This helps the model generalize better to different types of acoustic scenes.
The fusion module then combines the output of the global and local contextual information extraction modules using an attention mechanism, allowing the model to focus on the most relevant features for classification.
The global and local contextual information extraction modules use a combination of convolutional and attention layers to capture both broad and fine-grained patterns in the audio data. The attention mechanism helps the model prioritize the most important features for the classification task.
The researchers also integrated other techniques, such as knowledge distillation and adaptive residual normalization, to further improve the model's performance and efficiency.
When evaluated on the DCASE2023 challenge dataset, the proposed system achieved an accuracy of 56.10%, outperforming the top two systems in both accuracy and complexity. The model has a relatively small number of parameters (5.21k) and low computational cost (1.44 million multiply-accumulate operations), making it suitable for deployment on resource-constrained devices.
Critical Analysis
The paper provides a thorough explanation of the proposed system and its components, and the experimental results demonstrate the effectiveness of the approach. However, the authors do not discuss any potential limitations or caveats of their method.
For example, the performance of the system may be sensitive to the specific dataset or acoustic scenes used in the DCASE2023 challenge. It would be helpful to understand how the method would generalize to other datasets or real-world scenarios.
Additionally, the authors do not explore the trade-offs between accuracy and complexity in depth. While the proposed system achieves state-of-the-art performance with low complexity, it would be interesting to see how the system's performance scales as the complexity is increased, or if there are any diminishing returns beyond a certain level of complexity.
Overall, the research presented in this paper is a valuable contribution to the field of efficient audio classification, and the proposed system could have practical applications in resource-constrained environments. However, further investigation into the method's limitations and the broader trade-offs between accuracy and complexity would help provide a more comprehensive understanding of the system's capabilities and potential use cases.
Conclusion
The researchers have developed an innovative parallel attention-convolution network for low-complexity acoustic scene classification that achieves state-of-the-art performance on the DCASE2023 challenge dataset. By integrating techniques like knowledge distillation and data augmentation, the system is able to capture both global and local contextual information from audio clips in an efficient manner.
The high accuracy and low complexity of the proposed method make it a promising candidate for deployment on resource-constrained devices, such as mobile phones or embedded systems, where real-time audio classification is a valuable capability. The researchers' work contributes to the ongoing effort to develop efficient and effective audio classification systems that can be widely adopted across a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Low-Complexity Acoustic Scene Classification Using Parallel Attention-Convolution Network
Yanxiong Li, Jiaxin Tan, Guoqing Chen, Jialong Li, Yongjie Si, Qianhua He
This work is an improved system that we submitted to task 1 of DCASE2023 challenge. We propose a method of low-complexity acoustic scene classification by a parallel attention-convolution network which consists of four modules, including pre-processing, fusion, global and local contextual information extraction. The proposed network is computationally efficient to capture global and local contextual information from each audio clip. In addition, we integrate other techniques into our method, such as knowledge distillation, data augmentation, and adaptive residual normalization. When evaluated on the official dataset of DCASE2023 challenge, our method obtains the highest accuracy of 56.10% with parameter number of 5.21 kilo and multiply-accumulate operations of 1.44 million. It exceeds the top two systems of DCASE2023 challenge in accuracy and complexity, and obtains state-of-the-art result. Code is at: https://github.com/Jessytan/Low-complexity-ASC.
Read more6/13/2024

0
Data-Efficient Low-Complexity Acoustic Scene Classification in the DCASE 2024 Challenge
Florian Schmid, Paul Primus, Toni Heittola, Annamaria Mesaros, Irene Mart'in-Morat'o, Khaled Koutini, Gerhard Widmer
This article describes the Data-Efficient Low-Complexity Acoustic Scene Classification Task in the DCASE 2024 Challenge and the corresponding baseline system. The task setup is a continuation of previous editions (2022 and 2023), which focused on recording device mismatches and low-complexity constraints. This year's edition introduces an additional real-world problem: participants must develop data-efficient systems for five scenarios, which progressively limit the available training data. The provided baseline system is based on an efficient, factorized CNN architecture constructed from inverted residual blocks and uses Freq-MixStyle to tackle the device mismatch problem. The task received 37 submissions from 17 teams, with the large majority of systems outperforming the baseline. The top-ranked system's accuracy ranges from 54.3% on the smallest to 61.8% on the largest subset, corresponding to relative improvements of approximately 23% and 9% over the baseline system on the evaluation set.
Read more7/19/2024
🤿
0
Deep Space Separable Distillation for Lightweight Acoustic Scene Classification
ShuQi Ye, Yuan Tian
Acoustic scene classification (ASC) is highly important in the real world. Recently, deep learning-based methods have been widely employed for acoustic scene classification. However, these methods are currently not lightweight enough as well as their performance is not satisfactory. To solve these problems, we propose a deep space separable distillation network. Firstly, the network performs high-low frequency decomposition on the log-mel spectrogram, significantly reducing computational complexity while maintaining model performance. Secondly, we specially design three lightweight operators for ASC, including Separable Convolution (SC), Orthonormal Separable Convolution (OSC), and Separable Partial Convolution (SPC). These operators exhibit highly efficient feature extraction capabilities in acoustic scene classification tasks. The experimental results demonstrate that the proposed method achieves a performance gain of 9.8% compared to the currently popular deep learning methods, while also having smaller parameter count and computational complexity.
Read more5/7/2024
0
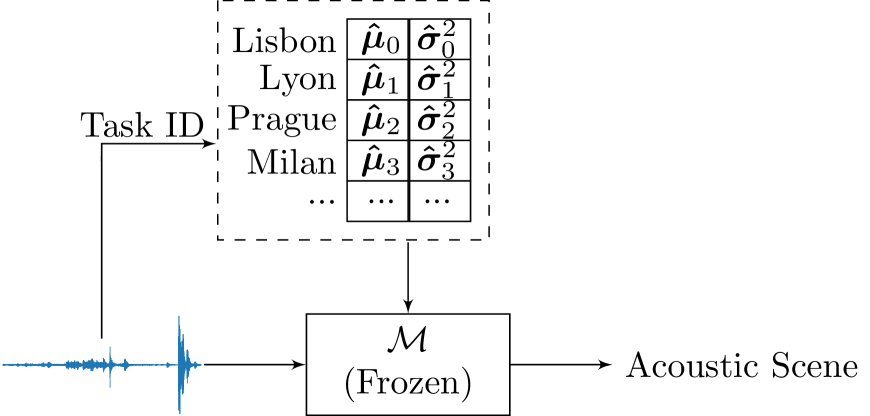
Online Domain-Incremental Learning Approach to Classify Acoustic Scenes in All Locations
Manjunath Mulimani, Annamaria Mesaros
In this paper, we propose a method for online domain-incremental learning of acoustic scene classification from a sequence of different locations. Simply training a deep learning model on a sequence of different locations leads to forgetting of previously learned knowledge. In this work, we only correct the statistics of the Batch Normalization layers of a model using a few samples to learn the acoustic scenes from a new location without any excessive training. Experiments are performed on acoustic scenes from 11 different locations, with an initial task containing acoustic scenes from 6 locations and the remaining 5 incremental tasks each representing the acoustic scenes from a different location. The proposed approach outperforms fine-tuning based methods and achieves an average accuracy of 48.8% after learning the last task in sequence without forgetting acoustic scenes from the previously learned locations.
Read more6/21/2024