Online Domain-Incremental Learning Approach to Classify Acoustic Scenes in All Locations

0
Sign in to get full access
Overview
- This paper presents an online domain-incremental learning approach to classify acoustic scenes in all locations.
- The work was supported by the Jane and Aatos Erkko Foundation under a grant for "Continual learning of sounds with deep neural networks".
- The authors utilized computational resources provided by the CSC-IT Centre of Science Ltd. in Finland.
Plain English Explanation
In this research, the team developed a new method for training artificial intelligence (AI) systems to recognize the sounds of different environments, like a busy city street or a quiet forest. Traditional AI models are typically trained on a fixed dataset and struggle to adapt to new sounds or locations.
The researchers' approach allows the AI model to continuously learn and improve its sound recognition abilities as it encounters new environments. This is called "domain-incremental learning", where the model can expand its knowledge without forgetting what it has already learned.
The key innovation is that the model can learn new acoustic scenes in an "online" fashion, meaning it can adapt to new sounds as they are encountered, rather than requiring the entire dataset to be available upfront. This makes the system more flexible and practical for real-world applications.
The researchers leveraged specialized deep learning techniques, like Batch Normalization layers, to help the model retain its existing knowledge while efficiently incorporating new information. This helps prevent the common problem of "forgetting" that can occur as AI models learn new tasks.
Overall, this research represents an important advance in the field of acoustic scene classification, with potential applications in areas like sound event localization and classification, lightweight acoustic scene analysis, and the creation of audio datasets from field recordings.
Technical Explanation
The researchers propose an online domain-incremental learning approach to acoustic scene classification, which allows a deep learning model to continuously learn new acoustic scenes without forgetting previously learned information.
The key elements of the method include:
-
Online Learning: The model can adapt to new acoustic scenes as they are encountered, rather than requiring the entire dataset to be available upfront. This makes the system more flexible and practical for real-world applications.
-
Domain-Incremental Learning: The model can expand its knowledge to recognize new acoustic scenes without catastrophically forgetting its previously learned information. This is achieved through the use of specialized deep learning techniques, such as Batch Normalization layers.
-
Experimental Evaluation: The researchers evaluated their approach on the TAU Urban Acoustic Scenes 2022 dataset, which contains audio recordings from various urban environments. They compared the performance of their online domain-incremental learning model to traditional batch-based training methods, demonstrating the advantages of their approach.
The findings suggest that the proposed method can effectively classify acoustic scenes in new locations while maintaining high performance on previously learned scenes. This represents an important advancement in the field of acoustic scene classification, with potential applications in various domains, such as sound event localization and classification, lightweight acoustic scene analysis, and the creation of audio datasets from field recordings.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed online domain-incremental learning approach for acoustic scene classification. The authors have thoroughly investigated the performance of their method and compared it to traditional batch-based training, demonstrating its advantages.
However, the paper does not extensively address potential limitations or areas for further research. For example, the authors could have discussed the scalability of the approach as the number of acoustic scenes to be learned increases, or the impact of the specific deep learning techniques used, such as Batch Normalization layers, on the overall performance.
Additionally, the paper could have explored the generalizability of the approach to other audio-related tasks beyond acoustic scene classification, such as sound event detection or audio source separation. Expanding the scope of the research could provide insights into the broader applicability of the proposed techniques.
Overall, the paper presents a significant contribution to the field of acoustic scene classification, but there is room for further exploration of the method's limitations, potential extensions, and broader implications for audio-based AI systems.
Conclusion
This research introduces an online domain-incremental learning approach to acoustic scene classification, which allows deep learning models to continuously expand their knowledge of different acoustic environments without forgetting previously learned information.
The key innovation is the ability to adapt to new acoustic scenes as they are encountered, rather than relying on a fixed dataset. This makes the system more flexible and practical for real-world applications, with potential impacts on a range of audio-based AI tasks, from sound event localization and classification to the creation of diverse audio datasets.
The findings demonstrate the advantages of the proposed method over traditional batch-based training, highlighting its potential to advance the state of the art in acoustic scene classification and contribute to the development of more robust and adaptable audio-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Online Domain-Incremental Learning Approach to Classify Acoustic Scenes in All Locations
Manjunath Mulimani, Annamaria Mesaros
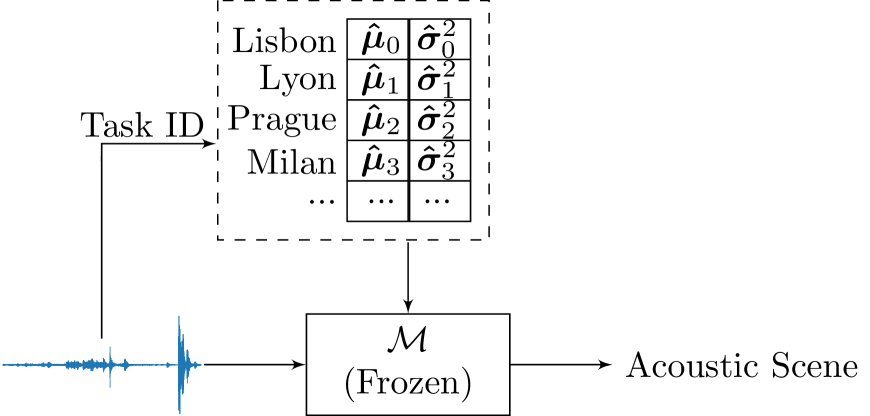
In this paper, we propose a method for online domain-incremental learning of acoustic scene classification from a sequence of different locations. Simply training a deep learning model on a sequence of different locations leads to forgetting of previously learned knowledge. In this work, we only correct the statistics of the Batch Normalization layers of a model using a few samples to learn the acoustic scenes from a new location without any excessive training. Experiments are performed on acoustic scenes from 11 different locations, with an initial task containing acoustic scenes from 6 locations and the remaining 5 incremental tasks each representing the acoustic scenes from a different location. The proposed approach outperforms fine-tuning based methods and achieves an average accuracy of 48.8% after learning the last task in sequence without forgetting acoustic scenes from the previously learned locations.
Read more6/21/2024
🤖
0
Analytic Class Incremental Learning for Sound Source Localization with Privacy Protection
Xinyuan Qian, Xianghu Yue, Jiadong Wang, Huiping Zhuang, Haizhou Li
Sound Source Localization (SSL) enabling technology for applications such as surveillance and robotics. While traditional Signal Processing (SP)-based SSL methods provide analytic solutions under specific signal and noise assumptions, recent Deep Learning (DL)-based methods have significantly outperformed them. However, their success depends on extensive training data and substantial computational resources. Moreover, they often rely on large-scale annotated spatial data and may struggle when adapting to evolving sound classes. To mitigate these challenges, we propose a novel Class Incremental Learning (CIL) approach, termed SSL-CIL, which avoids serious accuracy degradation due to catastrophic forgetting by incrementally updating the DL-based SSL model through a closed-form analytic solution. In particular, data privacy is ensured since the learning process does not revisit any historical data (exemplar-free), which is more suitable for smart home scenarios. Empirical results in the public SSLR dataset demonstrate the superior performance of our proposal, achieving a localization accuracy of 90.9%, surpassing other competitive methods.
Read more9/12/2024

0
Towards Robust Few-shot Class Incremental Learning in Audio Classification using Contrastive Representation
Riyansha Singh, Parinita Nema, Vinod K Kurmi
In machine learning applications, gradual data ingress is common, especially in audio processing where incremental learning is vital for real-time analytics. Few-shot class-incremental learning addresses challenges arising from limited incoming data. Existing methods often integrate additional trainable components or rely on a fixed embedding extractor post-training on base sessions to mitigate concerns related to catastrophic forgetting and the dangers of model overfitting. However, using cross-entropy loss alone during base session training is suboptimal for audio data. To address this, we propose incorporating supervised contrastive learning to refine the representation space, enhancing discriminative power and leading to better generalization since it facilitates seamless integration of incremental classes, upon arrival. Experimental results on NSynth and LibriSpeech datasets with 100 classes, as well as ESC dataset with 50 and 10 classes, demonstrate state-of-the-art performance.
Read more8/9/2024
🏷️
0
Low-Complexity Acoustic Scene Classification Using Parallel Attention-Convolution Network
Yanxiong Li, Jiaxin Tan, Guoqing Chen, Jialong Li, Yongjie Si, Qianhua He
This work is an improved system that we submitted to task 1 of DCASE2023 challenge. We propose a method of low-complexity acoustic scene classification by a parallel attention-convolution network which consists of four modules, including pre-processing, fusion, global and local contextual information extraction. The proposed network is computationally efficient to capture global and local contextual information from each audio clip. In addition, we integrate other techniques into our method, such as knowledge distillation, data augmentation, and adaptive residual normalization. When evaluated on the official dataset of DCASE2023 challenge, our method obtains the highest accuracy of 56.10% with parameter number of 5.21 kilo and multiply-accumulate operations of 1.44 million. It exceeds the top two systems of DCASE2023 challenge in accuracy and complexity, and obtains state-of-the-art result. Code is at: https://github.com/Jessytan/Low-complexity-ASC.
Read more6/13/2024