Low-Dimensional Federated Knowledge Graph Embedding via Knowledge Distillation

0
🏷️
Sign in to get full access
Overview
- This paper presents a method for low-dimensional federated knowledge graph embedding using knowledge distillation.
- It aims to overcome the limitations of existing federated knowledge graph embedding approaches, which struggle with high-dimensional embeddings.
- The proposed method involves training a compact student model that distills knowledge from a larger teacher model, enabling efficient deployment on resource-constrained devices.
Plain English Explanation
Knowledge graphs are structured databases that represent information as a network of entities (nodes) and the relationships between them (edges). Federated learning is a technique that allows multiple devices or organizations to collaboratively train a machine learning model without sharing their raw data.
The authors of this paper recognized that existing federated knowledge graph embedding approaches often produce high-dimensional embeddings, which can be challenging to deploy and store on resource-constrained devices like smartphones or edge devices. To address this issue, they propose a knowledge distillation technique that allows a compact "student" model to learn from a larger "teacher" model, resulting in low-dimensional embeddings that can be efficiently deployed.
The key idea is to train the student model to mimic the behavior of the teacher model, capturing the essential knowledge while using fewer parameters. This approach enables the deployment of knowledge graph applications on a wide range of devices, from powerful servers to resource-constrained edge devices.
Technical Explanation
The proposed method, called Low-Dimensional Federated Knowledge Graph Embedding via Knowledge Distillation (LD-FKGE), consists of two main components:
-
Federated Learning: The authors use a federated learning approach to train a large "teacher" knowledge graph embedding model across multiple clients (devices or organizations) without sharing their raw data. This allows the model to learn from a diverse set of knowledge sources while preserving privacy.
-
Knowledge Distillation: The authors then employ a knowledge distillation technique to train a compact "student" model that mimics the behavior of the larger teacher model. The student model is optimized to reproduce the output of the teacher model, resulting in low-dimensional embeddings that can be efficiently deployed on resource-constrained devices.
The authors evaluate their approach on several knowledge graph datasets and demonstrate that the student model can achieve competitive performance compared to the teacher model, while using significantly fewer parameters. This enables the deployment of knowledge graph applications on a wider range of devices, from powerful servers to resource-constrained edge devices.
Critical Analysis
The authors acknowledge that their approach relies on the assumption that the teacher model has captured the essential knowledge from the federated data sources. If the teacher model is not sufficiently expressive or the federated data is not diverse enough, the student model may not be able to fully capture the underlying knowledge.
Additionally, the authors do not extensively explore the impact of different federated learning and knowledge distillation techniques on the final performance of the student model. Further research could investigate the sensitivity of the approach to these design choices and explore ways to optimize the knowledge transfer process.
Finally, the authors focus on the efficiency and performance of the student model, but do not delve into the potential privacy implications of their federated learning approach. Future work could examine privacy-preserving aspects of the method, such as the use of differential privacy or secure multi-party computation techniques.
Conclusion
This paper presents a novel approach to low-dimensional federated knowledge graph embedding using knowledge distillation. By training a compact student model to mimic the behavior of a larger teacher model, the authors demonstrate a way to efficiently deploy knowledge graph applications on a wide range of devices, from powerful servers to resource-constrained edge devices.
The approach offers a promising solution to the challenges of high-dimensional embeddings in federated learning settings, paving the way for more widespread adoption of knowledge graph technologies across various industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Low-Dimensional Federated Knowledge Graph Embedding via Knowledge Distillation
Xiaoxiong Zhang, Zhiwei Zeng, Xin Zhou, Zhiqi Shen
Federated Knowledge Graph Embedding (FKGE) aims to facilitate collaborative learning of entity and relation embeddings from distributed Knowledge Graphs (KGs) across multiple clients, while preserving data privacy. Training FKGE models with higher dimensions is typically favored due to their potential for achieving superior performance. However, high-dimensional embeddings present significant challenges in terms of storage resource and inference speed. Unlike traditional KG embedding methods, FKGE involves multiple client-server communication rounds, where communication efficiency is critical. Existing embedding compression methods for traditional KGs may not be directly applicable to FKGE as they often require multiple model trainings which potentially incur substantial communication costs. In this paper, we propose a light-weight component based on Knowledge Distillation (KD) which is titled FedKD and tailored specifically for FKGE methods. During client-side local training, FedKD facilitates the low-dimensional student model to mimic the score distribution of triples from the high-dimensional teacher model using KL divergence loss. Unlike traditional KD way, FedKD adaptively learns a temperature to scale the score of positive triples and separately adjusts the scores of corresponding negative triples using a predefined temperature, thereby mitigating teacher over-confidence issue. Furthermore, we dynamically adjust the weight of KD loss to optimize the training process. Extensive experiments on three datasets support the effectiveness of FedKD.
Read more8/13/2024

0
Personalized Federated Knowledge Graph Embedding with Client-Wise Relation Graph
Xiaoxiong Zhang, Zhiwei Zeng, Xin Zhou, Dusit Niyato, Zhiqi Shen
Federated Knowledge Graph Embedding (FKGE) has recently garnered considerable interest due to its capacity to extract expressive representations from distributed knowledge graphs, while concurrently safeguarding the privacy of individual clients. Existing FKGE methods typically harness the arithmetic mean of entity embeddings from all clients as the global supplementary knowledge, and learn a replica of global consensus entities embeddings for each client. However, these methods usually neglect the inherent semantic disparities among distinct clients. This oversight not only results in the globally shared complementary knowledge being inundated with too much noise when tailored to a specific client, but also instigates a discrepancy between local and global optimization objectives. Consequently, the quality of the learned embeddings is compromised. To address this, we propose Personalized Federated knowledge graph Embedding with client-wise relation Graph (PFedEG), a novel approach that employs a client-wise relation graph to learn personalized embeddings by discerning the semantic relevance of embeddings from other clients. Specifically, PFedEG learns personalized supplementary knowledge for each client by amalgamating entity embedding from its neighboring clients based on their affinity on the client-wise relation graph. Each client then conducts personalized embedding learning based on its local triples and personalized supplementary knowledge. We conduct extensive experiments on four benchmark datasets to evaluate our method against state-of-the-art models and results demonstrate the superiority of our method.
Read more6/19/2024
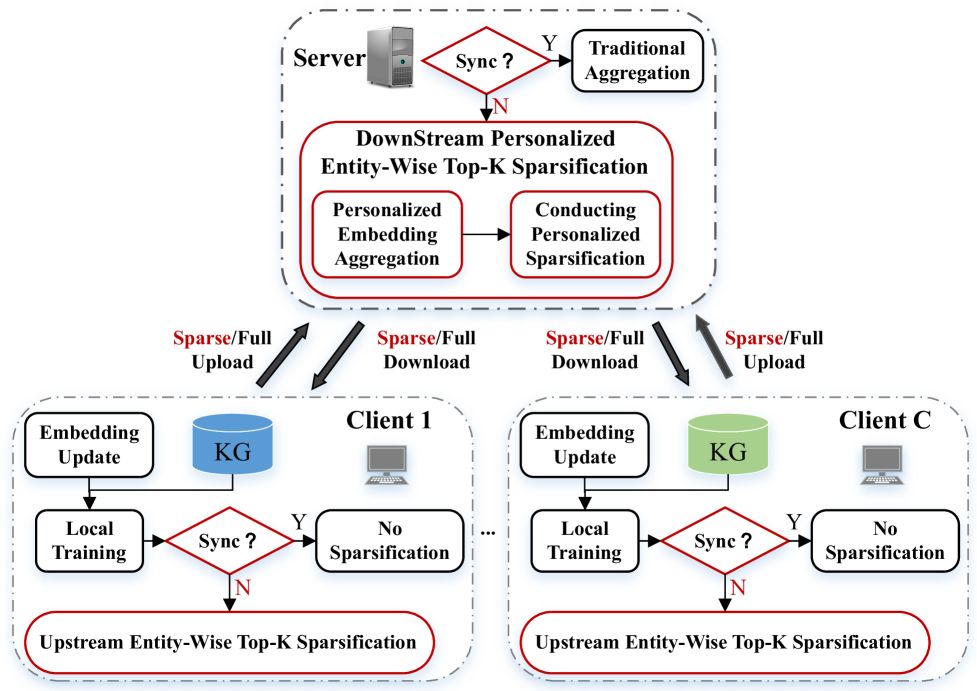
0
Communication-Efficient Federated Knowledge Graph Embedding with Entity-Wise Top-K Sparsification
Xiaoxiong Zhang, Zhiwei Zeng, Xin Zhou, Dusit Niyato, Zhiqi Shen
Federated Knowledge Graphs Embedding learning (FKGE) encounters challenges in communication efficiency stemming from the considerable size of parameters and extensive communication rounds. However, existing FKGE methods only focus on reducing communication rounds by conducting multiple rounds of local training in each communication round, and ignore reducing the size of parameters transmitted within each communication round. To tackle the problem, we first find that universal reduction in embedding precision across all entities during compression can significantly impede convergence speed, underscoring the importance of maintaining embedding precision. We then propose bidirectional communication-efficient FedS based on Entity-Wise Top-K Sparsification strategy. During upload, clients dynamically identify and upload only the Top-K entity embeddings with the greater changes to the server. During download, the server first performs personalized embedding aggregation for each client. It then identifies and transmits the Top-K aggregated embeddings to each client. Besides, an Intermittent Synchronization Mechanism is used by FedS to mitigate negative effect of embedding inconsistency among shared entities of clients caused by heterogeneity of Federated Knowledge Graph. Extensive experiments across three datasets showcase that FedS significantly enhances communication efficiency with negligible (even no) performance degradation.
Read more6/21/2024
👁️
0
Confidence-aware Self-Semantic Distillation on Knowledge Graph Embedding
Yichen Liu, Jiawei Chen, Defang Chen, Zhehui Zhou, Yan Feng, Can Wang
Knowledge Graph Embedding (KGE), which projects entities and relations into continuous vector spaces, have garnered significant attention. Although high-dimensional KGE methods offer better performance, they come at the expense of significant computation and memory overheads. Decreasing embedding dimensions significantly deteriorates model performance. While several recent efforts utilize knowledge distillation or non-Euclidean representation learning to augment the effectiveness of low-dimensional KGE, they either necessitate a pre-trained high-dimensional teacher model or involve complex non-Euclidean operations, thereby incurring considerable additional computational costs. To address this, this work proposes Confidence-aware Self-Knowledge Distillation (CSD) that learns from model itself to enhance KGE in a low-dimensional space. Specifically, CSD extracts knowledge from embeddings in previous iterations, which would be utilized to supervise the learning of the model in the next iterations. Moreover, a specific semantic module is developed to filter reliable knowledge by estimating the confidence of previously learned embeddings. This straightforward strategy bypasses the need for time-consuming pre-training of teacher models and can be integrated into various KGE methods to improve their performance. Our comprehensive experiments on six KGE backbones and four datasets underscore the effectiveness of the proposed CSD.
Read more5/28/2024