LPT++: Efficient Training on Mixture of Long-tailed Experts

0

Sign in to get full access
Overview
- Efficient training on a mixture of long-tailed experts
- Parameter-efficient fine-tuning technique
- Ensemble of specialized models for better performance
Plain English Explanation
The paper presents a novel technique called LPT++ for efficiently training on a mixture of long-tailed experts. Long-tailed distributions are common in many real-world datasets, where a small number of classes have a large number of examples, while the majority of classes have very few examples.
To address this challenge, LPT++ uses a parameter-efficient fine-tuning approach to train an ensemble of specialized models, each focusing on a different subset of the classes. This allows the model to capture the nuances of the long-tailed distribution more effectively than a single, generalized model.
The key idea is to first train a base model on the entire dataset, and then fine-tune a collection of "expert" models, each responsible for a different subset of the classes. This fine-tuning process is done in a parameter-efficient way, by only updating a small number of the model's parameters, rather than the entire network.
The resulting ensemble of expert models can then be combined to make predictions, leveraging the strengths of each individual model for improved overall performance on the long-tailed dataset.
Technical Explanation
The LPT++ approach consists of three main steps:
-
Base Model Training: The authors first train a base model on the entire dataset using standard techniques.
-
Expert Model Fine-Tuning: They then fine-tune a collection of "expert" models, each responsible for a different subset of the classes. This fine-tuning process only updates a small number of the model's parameters, making it more efficient than full fine-tuning.
-
Ensemble Prediction: At inference time, the authors combine the predictions of the ensemble of expert models to make the final prediction, leveraging the strengths of each individual model.
The key technical innovations in LPT++ include:
- Parameter-Efficient Fine-Tuning: The authors use a lightweight fine-tuning approach that only updates a small number of the model's parameters, rather than the entire network.
- Mixture of Experts: The ensemble of expert models, each focusing on a different subset of the classes, allows the system to better capture the nuances of the long-tailed distribution.
- Efficient Training Procedure: The authors' training procedure is more efficient than traditional fine-tuning or joint training of the expert models.
Critical Analysis
The authors acknowledge several limitations of their approach:
- The performance of LPT++ may be sensitive to the choice of class subsets assigned to each expert model.
- The ensemble prediction step introduces some computational overhead compared to a single, generalized model.
- The authors only evaluate LPT++ on a few long-tailed benchmark datasets, and its performance on other types of data is not guaranteed.
Additionally, it would be interesting to see how LPT++ compares to other recent approaches for long-tailed learning, such as LMPT or PEMT, which also leverage specialized models or class-specific representations.
Conclusion
The LPT++ technique presented in this paper offers a promising approach for efficiently training on long-tailed datasets, which are common in many real-world applications. By using a parameter-efficient fine-tuning strategy to build an ensemble of specialized expert models, LPT++ can capture the nuances of the long-tailed distribution more effectively than a single, generalized model.
While the authors identify some limitations, the core ideas behind LPT++ could have significant implications for improving the performance of machine learning models on challenging, long-tailed datasets, and the technique may inspire further research in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!LPT++: Efficient Training on Mixture of Long-tailed Experts
Bowen Dong, Pan Zhou, Wangmeng Zuo
We introduce LPT++, a comprehensive framework for long-tailed classification that combines parameter-efficient fine-tuning (PEFT) with a learnable model ensemble. LPT++ enhances frozen Vision Transformers (ViTs) through the integration of three core components. The first is a universal long-tailed adaptation module, which aggregates long-tailed prompts and visual adapters to adapt the pretrained model to the target domain, meanwhile improving its discriminative ability. The second is the mixture of long-tailed experts framework with a mixture-of-experts (MoE) scorer, which adaptively calculates reweighting coefficients for confidence scores from both visual-only and visual-language (VL) model experts to generate more accurate predictions. Finally, LPT++ employs a three-phase training framework, wherein each critical module is learned separately, resulting in a stable and effective long-tailed classification training paradigm. Besides, we also propose the simple version of LPT++ namely LPT, which only integrates visual-only pretrained ViT and long-tailed prompts to formulate a single model method. LPT can clearly illustrate how long-tailed prompts works meanwhile achieving comparable performance without VL pretrained models. Experiments show that, with only ~1% extra trainable parameters, LPT++ achieves comparable accuracy against all the counterparts.
Read more9/18/2024

0
Three Heads Are Better Than One: Complementary Experts for Long-Tailed Semi-supervised Learning
Chengcheng Ma, Ismail Elezi, Jiankang Deng, Weiming Dong, Changsheng Xu
We address the challenging problem of Long-Tailed Semi-Supervised Learning (LTSSL) where labeled data exhibit imbalanced class distribution and unlabeled data follow an unknown distribution. Unlike in balanced SSL, the generated pseudo-labels are skewed towards head classes, intensifying the training bias. Such a phenomenon is even amplified as more unlabeled data will be mislabeled as head classes when the class distribution of labeled and unlabeled datasets are mismatched. To solve this problem, we propose a novel method named ComPlementary Experts (CPE). Specifically, we train multiple experts to model various class distributions, each of them yielding high-quality pseudo-labels within one form of class distribution. Besides, we introduce Classwise Batch Normalization for CPE to avoid performance degradation caused by feature distribution mismatch between head and non-head classes. CPE achieves state-of-the-art performances on CIFAR-10-LT, CIFAR-100-LT, and STL-10-LT dataset benchmarks. For instance, on CIFAR-10-LT, CPE improves test accuracy by over 2.22% compared to baselines. Code is available at https://github.com/machengcheng2016/CPE-LTSSL.
Read more4/4/2024
👁️
0
LMPT: Prompt Tuning with Class-Specific Embedding Loss for Long-tailed Multi-Label Visual Recognition
Peng Xia, Di Xu, Ming Hu, Lie Ju, Zongyuan Ge
Long-tailed multi-label visual recognition (LTML) task is a highly challenging task due to the label co-occurrence and imbalanced data distribution. In this work, we propose a unified framework for LTML, namely prompt tuning with class-specific embedding loss (LMPT), capturing the semantic feature interactions between categories by combining text and image modality data and improving the performance synchronously on both head and tail classes. Specifically, LMPT introduces the embedding loss function with class-aware soft margin and re-weighting to learn class-specific contexts with the benefit of textual descriptions (captions), which could help establish semantic relationships between classes, especially between the head and tail classes. Furthermore, taking into account the class imbalance, the distribution-balanced loss is adopted as the classification loss function to further improve the performance on the tail classes without compromising head classes. Extensive experiments are conducted on VOC-LT and COCO-LT datasets, which demonstrates that our method significantly surpasses the previous state-of-the-art methods and zero-shot CLIP in LTML. Our codes are fully public at https://github.com/richard-peng-xia/LMPT.
Read more6/19/2024
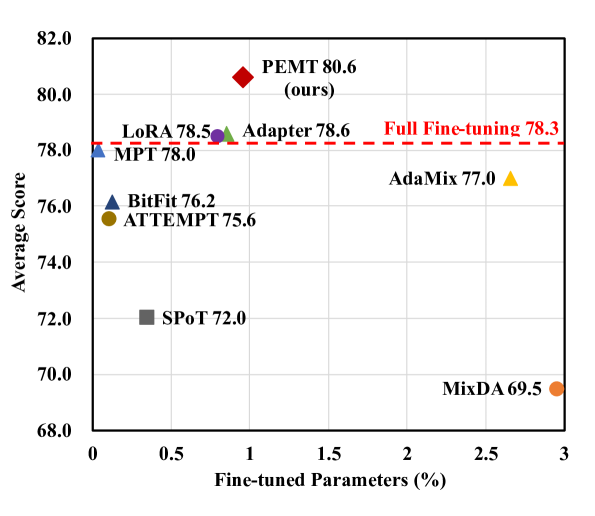
0
PEMT: Multi-Task Correlation Guided Mixture-of-Experts Enables Parameter-Efficient Transfer Learning
Zhisheng Lin, Han Fu, Chenghao Liu, Zhuo Li, Jianling Sun
Parameter-efficient fine-tuning (PEFT) has emerged as an effective method for adapting pre-trained language models to various tasks efficiently. Recently, there has been a growing interest in transferring knowledge from one or multiple tasks to the downstream target task to achieve performance improvements. However, current approaches typically either train adapters on individual tasks or distill shared knowledge from source tasks, failing to fully exploit task-specific knowledge and the correlation between source and target tasks. To overcome these limitations, we propose PEMT, a novel parameter-efficient fine-tuning framework based on multi-task transfer learning. PEMT extends the mixture-of-experts (MoE) framework to capture the transferable knowledge as a weighted combination of adapters trained on source tasks. These weights are determined by a gated unit, measuring the correlation between the target and each source task using task description prompt vectors. To fully exploit the task-specific knowledge, we also propose the Task Sparsity Loss to improve the sparsity of the gated unit. We conduct experiments on a broad range of tasks over 17 datasets. The experimental results demonstrate our PEMT yields stable improvements over full fine-tuning, and state-of-the-art PEFT and knowledge transferring methods on various tasks. The results highlight the effectiveness of our method which is capable of sufficiently exploiting the knowledge and correlation features across multiple tasks.
Read more6/7/2024