PEMT: Multi-Task Correlation Guided Mixture-of-Experts Enables Parameter-Efficient Transfer Learning
2402.15082
0
0
Abstract
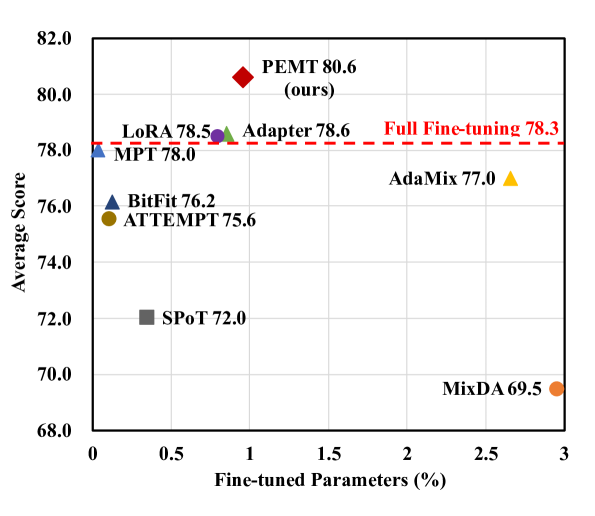
Parameter-efficient fine-tuning (PEFT) has emerged as an effective method for adapting pre-trained language models to various tasks efficiently. Recently, there has been a growing interest in transferring knowledge from one or multiple tasks to the downstream target task to achieve performance improvements. However, current approaches typically either train adapters on individual tasks or distill shared knowledge from source tasks, failing to fully exploit task-specific knowledge and the correlation between source and target tasks. To overcome these limitations, we propose PEMT, a novel parameter-efficient fine-tuning framework based on multi-task transfer learning. PEMT extends the mixture-of-experts (MoE) framework to capture the transferable knowledge as a weighted combination of adapters trained on source tasks. These weights are determined by a gated unit, measuring the correlation between the target and each source task using task description prompt vectors. To fully exploit the task-specific knowledge, we also propose the Task Sparsity Loss to improve the sparsity of the gated unit. We conduct experiments on a broad range of tasks over 17 datasets. The experimental results demonstrate our PEMT yields stable improvements over full fine-tuning, and state-of-the-art PEFT and knowledge transferring methods on various tasks. The results highlight the effectiveness of our method which is capable of sufficiently exploiting the knowledge and correlation features across multiple tasks.
Create account to get full access
Overview
- The paper presents a novel Parameter-Efficient Mixture-of-Experts Transfer Learning (PEMT) method for fine-tuning large pre-trained language models on downstream tasks.
- PEMT leverages a mixture-of-experts architecture and multi-task correlation guidance to enable efficient transfer learning with a small number of trainable parameters.
- The approach outperforms standard fine-tuning and other parameter-efficient techniques on a variety of benchmark tasks, demonstrating its effectiveness.
Plain English Explanation
PEMT: Multi-Task Correlation Guided Mixture-of-Experts Enables Parameter-Efficient Transfer Learning is a new technique for fine-tuning large pre-trained language models, like BERT or GPT, to perform well on specific tasks.
The key idea is to use a "mixture-of-experts" architecture, where the model has multiple specialized sub-networks, or "experts," that each focus on different aspects of the task. These experts work together to produce the final output. The experts are guided by analyzing the correlations between the different tasks the model is being trained on, helping the experts specialize in the most relevant areas.
This allows the model to be fine-tuned with far fewer trainable parameters than standard fine-tuning approaches. Having fewer parameters makes the model more efficient and faster to train, which is important when working with large language models. The paper shows this technique outperforms other parameter-efficient fine-tuning methods on a range of benchmarks.
In essence, PEMT is a smart way to fine-tune large language models that requires less computational power and data, making it more practical for real-world applications with limited resources.
Technical Explanation
PEMT: Multi-Task Correlation Guided Mixture-of-Experts Enables Parameter-Efficient Transfer Learning introduces a novel Parameter-Efficient Mixture-of-Experts Transfer Learning (PEMT) approach for fine-tuning large pre-trained language models.
The key components of PEMT are:
-
Mixture-of-Experts Architecture: The model consists of a shared backbone network and multiple task-specific "expert" sub-networks. Each expert focuses on different aspects of the task, and their outputs are combined to produce the final prediction.
-
Multi-Task Correlation Guidance: The training process is guided by analyzing the correlations between the different tasks the model is trained on. This helps the experts specialize in the most relevant areas for the target task.
-
Parameter-Efficient Fine-Tuning: By using a mixture-of-experts design with parameter sharing, PEMT requires far fewer trainable parameters than standard fine-tuning approaches. This makes the model more efficient to train and deploy.
The authors evaluate PEMT on a range of benchmarks, including natural language understanding, text generation, and multi-task learning tasks. They show that PEMT outperforms standard fine-tuning as well as other parameter-efficient techniques, such as Parameter-Efficient Fine-Tuning (PEFT) and MoPEFT, in terms of performance and parameter efficiency.
Critical Analysis
The paper presents a compelling approach to parameter-efficient fine-tuning of large language models. The use of a mixture-of-experts architecture with multi-task correlation guidance is a novel and promising direction. However, there are a few potential limitations and areas for further research:
-
Task Generalization: The paper focuses on evaluating PEMT on a limited set of benchmarks. It would be important to assess the model's performance and transfer capabilities on a more diverse range of tasks, including real-world applications, to fully understand its generalization abilities.
-
Interpretability and Explainability: The mixture-of-experts design could potentially offer insights into the different components of the task, but the paper does not delve into the interpretability or explainability of the model. Semantic-Are Beacons explores related ideas in this direction.
-
Scalability and Memory Efficiency: While PEMT is more parameter-efficient than standard fine-tuning, the mixture-of-experts architecture may still pose challenges in terms of memory and computational requirements, especially for very large language models. Further research into Q-PEFT techniques could help address these scalability concerns.
Overall, the PEMT approach represents an exciting step forward in parameter-efficient transfer learning for large language models. However, continued research is needed to address the potential limitations and further expand the capabilities of this promising technique.
Conclusion
PEMT: Multi-Task Correlation Guided Mixture-of-Experts Enables Parameter-Efficient Transfer Learning presents a novel Parameter-Efficient Mixture-of-Experts Transfer Learning (PEMT) method that leverages a mixture-of-experts architecture and multi-task correlation guidance to enable efficient fine-tuning of large pre-trained language models.
By requiring fewer trainable parameters than standard fine-tuning, PEMT offers a more practical and resource-efficient approach to adapting large language models to specific tasks. The technique's strong performance on benchmark evaluations suggests it could have significant real-world impact, particularly in scenarios with limited data or computational resources.
While further research is needed to explore the generalization, interpretability, and scalability of PEMT, this work represents an important step forward in the field of parameter-efficient transfer learning. Continued advancements in this area have the potential to unlock the full potential of large language models and make them more accessible and applicable across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
0
0
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
6/10/2024

Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Tong Su, Xin Peng, Sarubi Thillainathan, David Guzm'an, Surangika Ranathunga, En-Shiun Annie Lee
0
0
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
4/8/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024
📈
MoPEFT: A Mixture-of-PEFTs for the Segment Anything Model
Rajat Sahay, Andreas Savakis
0
0
The emergence of foundation models, such as the Segment Anything Model (SAM), has sparked interest in Parameter-Efficient Fine-Tuning (PEFT) methods that tailor these large models to application domains outside their training data. However, different PEFT techniques modify the representation of a model differently, making it a non-trivial task to select the most appropriate method for the domain of interest. We propose a new framework, Mixture-of-PEFTs methods (MoPEFT), that is inspired by traditional Mixture-of-Experts (MoE) methodologies and is utilized for fine-tuning SAM. Our MoPEFT framework incorporates three different PEFT techniques as submodules and dynamically learns to activate the ones that are best suited for a given data-task setup. We test our method on the Segment Anything Model and show that MoPEFT consistently outperforms other fine-tuning methods on the MESS benchmark.
5/2/2024