LPViT: Low-Power Semi-structured Pruning for Vision Transformers

0

Sign in to get full access
Overview
- This paper introduces LPViT, a technique for low-power semi-structured pruning of vision transformers (ViTs).
- LPViT aims to reduce the computational cost and memory footprint of ViTs without significantly degrading their accuracy.
- The authors propose a novel semi-structured pruning method that selectively prunes the attention and feed-forward layers in ViTs.
Plain English Explanation
The paper discusses a new way to make vision transformers (ViTs) more efficient and less power-hungry. ViTs are a type of deep learning model that has shown promising results in computer vision tasks, but they can be computationally expensive and consume a lot of power.
The researchers developed a technique called LPViT that selectively removes parts of the ViT model without significantly reducing its performance. This "pruning" process helps to reduce the model's size and computational requirements, making it more suitable for deployment on low-power devices like smartphones or embedded systems.
The key innovation in LPViT is that it prunes the model in a semi-structured way, targeting specific components like the attention and feed-forward layers. This allows for more targeted optimizations compared to unstructured pruning, which can be less effective.
By making ViTs more efficient, the researchers hope to enable their wider adoption in real-world applications where low power consumption and fast inference are important, such as in autonomous vehicles or on-device machine learning.
Technical Explanation
The authors propose a novel semi-structured pruning method for vision transformers (ViTs) called LPViT. Unlike unstructured pruning, which removes individual weight elements, LPViT selectively prunes entire attention and feed-forward layers in the ViT model.
This selective pruning approach is guided by an importance score that the authors develop, which measures the contribution of each layer to the overall model performance. Layers with lower importance scores are then pruned, reducing the computational cost and memory footprint of the ViT without significantly degrading its accuracy.
The authors evaluate LPViT on several ViT-based models and image classification benchmarks, including ViT, DeiT, and PiT. They show that LPViT can achieve up to 3.1x reduction in FLOPs and 2.5x reduction in model size with minimal accuracy loss compared to the original ViT models.
Critical Analysis
The authors provide a thorough evaluation of LPViT and demonstrate its effectiveness in reducing the computational cost and memory footprint of ViTs without significant accuracy degradation. However, the paper does not address some potential limitations and areas for further research:
- The pruning strategy in LPViT is based on a layer-wise importance score, which may not capture more complex, structured dependencies within the ViT model. More sophisticated pruning methods could potentially lead to further efficiency gains.
- The authors only evaluate LPViT on image classification tasks, but ViTs have also shown promise in other domains like object detection and segmentation. It would be interesting to see how LPViT performs on a wider range of computer vision tasks.
- The paper does not provide any insights into the computational or energy efficiency of the pruned ViT models in real-world deployment scenarios. Evaluating the actual runtime performance and power consumption of LPViT-optimized ViTs would be a valuable addition.
Overall, the LPViT technique presented in this paper is a promising step towards making ViTs more practical for deployment on resource-constrained devices. Further research and experimentation could help address the potential limitations and broaden the applicability of this approach.
Conclusion
This paper introduces LPViT, a novel semi-structured pruning method for improving the efficiency of vision transformers (ViTs). By selectively pruning attention and feed-forward layers based on their importance, LPViT can significantly reduce the computational cost and memory footprint of ViT models with minimal accuracy degradation.
The authors demonstrate the effectiveness of LPViT on several ViT-based architectures and image classification benchmarks, achieving up to 3.1x reduction in FLOPs and 2.5x reduction in model size. This work represents an important step towards enabling the wider deployment of ViTs, especially in low-power applications like embedded systems and on-device machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LPViT: Low-Power Semi-structured Pruning for Vision Transformers
Kaixin Xu, Zhe Wang, Chunyun Chen, Xue Geng, Jie Lin, Xulei Yang, Min Wu, Xiaoli Li, Weisi Lin
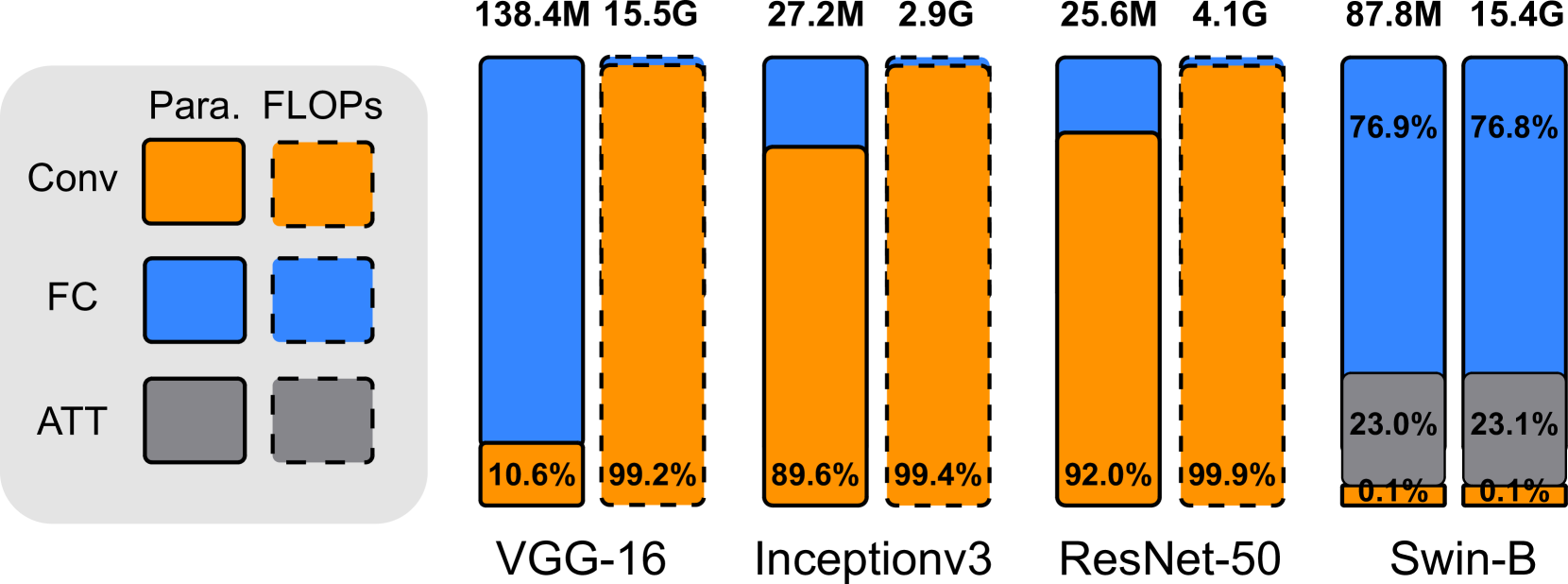
Vision transformers have emerged as a promising alternative to convolutional neural networks for various image analysis tasks, offering comparable or superior performance. However, one significant drawback of ViTs is their resource-intensive nature, leading to increased memory footprint, computation complexity, and power consumption. To democratize this high-performance technology and make it more environmentally friendly, it is essential to compress ViT models, reducing their resource requirements while maintaining high performance. In this paper, we introduce a new block-structured pruning to address the resource-intensive issue for ViTs, offering a balanced trade-off between accuracy and hardware acceleration. Unlike unstructured pruning or channel-wise structured pruning, block pruning leverages the block-wise structure of linear layers, resulting in more efficient matrix multiplications. To optimize this pruning scheme, our paper proposes a novel hardware-aware learning objective that simultaneously maximizes speedup and minimizes power consumption during inference, tailored to the block sparsity structure. This objective eliminates the need for empirical look-up tables and focuses solely on reducing parametrized layer connections. Moreover, our paper provides a lightweight algorithm to achieve post-training pruning for ViTs, utilizing second-order Taylor approximation and empirical optimization to solve the proposed hardware-aware objective. Extensive experiments on ImageNet are conducted across various ViT architectures, including DeiT-B and DeiT-S, demonstrating competitive performance with other pruning methods and achieving a remarkable balance between accuracy preservation and power savings. Especially, we achieve up to 3.93x and 1.79x speedups on dedicated hardware and GPUs respectively for DeiT-B, and also observe an inference power reduction by 1.4x on real-world GPUs.
Read more7/15/2024
0
Data-independent Module-aware Pruning for Hierarchical Vision Transformers
Yang He, Joey Tianyi Zhou
Hierarchical vision transformers (ViTs) have two advantages over conventional ViTs. First, hierarchical ViTs achieve linear computational complexity with respect to image size by local self-attention. Second, hierarchical ViTs create hierarchical feature maps by merging image patches in deeper layers for dense prediction. However, existing pruning methods ignore the unique properties of hierarchical ViTs and use the magnitude value as the weight importance. This approach leads to two main drawbacks. First, the local attention weights are compared at a global level, which may cause some locally important weights to be pruned due to their relatively small magnitude globally. The second issue with magnitude pruning is that it fails to consider the distinct weight distributions of the network, which are essential for extracting coarse to fine-grained features at various hierarchical levels. To solve the aforementioned issues, we have developed a Data-independent Module-Aware Pruning method (DIMAP) to compress hierarchical ViTs. To ensure that local attention weights at different hierarchical levels are compared fairly in terms of their contribution, we treat them as a module and examine their contribution by analyzing their information distortion. Furthermore, we introduce a novel weight metric that is solely based on weights and does not require input images, thereby eliminating the dependence on the patch merging process. Our method validates its usefulness and strengths on Swin Transformers of different sizes on ImageNet-1k classification. Notably, the top-5 accuracy drop is only 0.07% when we remove 52.5% FLOPs and 52.7% parameters of Swin-B. When we reduce 33.2% FLOPs and 33.2% parameters of Swin-S, we can even achieve a 0.8% higher relative top-5 accuracy than the original model. Code is available at: https://github.com/he-y/Data-independent-Module-Aware-Pruning
Read more4/23/2024
📈
0
Comprehensive Survey of Model Compression and Speed up for Vision Transformers
Feiyang Chen, Ziqian Luo, Lisang Zhou, Xueting Pan, Ying Jiang
Vision Transformers (ViT) have marked a paradigm shift in computer vision, outperforming state-of-the-art models across diverse tasks. However, their practical deployment is hampered by high computational and memory demands. This study addresses the challenge by evaluating four primary model compression techniques: quantization, low-rank approximation, knowledge distillation, and pruning. We methodically analyze and compare the efficacy of these techniques and their combinations in optimizing ViTs for resource-constrained environments. Our comprehensive experimental evaluation demonstrates that these methods facilitate a balanced compromise between model accuracy and computational efficiency, paving the way for wider application in edge computing devices.
Read more4/17/2024

0
Accelerating ViT Inference on FPGA through Static and Dynamic Pruning
Dhruv Parikh, Shouyi Li, Bingyi Zhang, Rajgopal Kannan, Carl Busart, Viktor Prasanna
Vision Transformers (ViTs) have achieved state-of-the-art accuracy on various computer vision tasks. However, their high computational complexity prevents them from being applied to many real-world applications. Weight and token pruning are two well-known methods for reducing complexity: weight pruning reduces the model size and associated computational demands, while token pruning further dynamically reduces the computation based on the input. Combining these two techniques should significantly reduce computation complexity and model size; however, naively integrating them results in irregular computation patterns, leading to significant accuracy drops and difficulties in hardware acceleration. Addressing the above challenges, we propose a comprehensive algorithm-hardware codesign for accelerating ViT on FPGA through simultaneous pruning -combining static weight pruning and dynamic token pruning. For algorithm design, we systematically combine a hardware-aware structured block-pruning method for pruning model parameters and a dynamic token pruning method for removing unimportant token vectors. Moreover, we design a novel training algorithm to recover the model's accuracy. For hardware design, we develop a novel hardware accelerator for executing the pruned model. The proposed hardware design employs multi-level parallelism with load balancing strategy to efficiently deal with the irregular computation pattern led by the two pruning approaches. Moreover, we develop an efficient hardware mechanism for efficiently executing the on-the-fly token pruning.
Read more4/15/2024