LQER: Low-Rank Quantization Error Reconstruction for LLMs

0

Sign in to get full access
Overview
• This paper introduces a novel technique called LQER (Low-Rank Quantization Error Reconstruction) for efficiently compressing large language models (LLMs) through low-bit quantization.
• The key idea is to leverage the inherent low-rank structure of the quantization error in LLMs to reconstruct the original weights, enabling accurate and efficient quantization.
Plain English Explanation
• Large language models like GPT-3 are very powerful but also very large, making them difficult to deploy on resource-constrained devices.
• LQER is a new technique that can significantly reduce the size of these models by converting their weights to a lower number of bits (e.g., 4 bits instead of 32 bits).
• The core insight is that the "errors" introduced by this quantization process have a special low-rank structure that can be exploited to reconstruct the original weights with high accuracy.
• This allows LQER to achieve much higher compression rates than previous quantization methods, while still maintaining the performance of the original model.
• By making LLMs smaller and more efficient, LQER could enable their deployment on a wider range of devices, from smartphones to edge devices, unlocking new applications.
Technical Explanation
• The authors observe that the quantization error in LLMs has a low-rank structure, meaning it can be well-approximated by a small number of basis vectors.
• They exploit this by decomposing the quantization error into a low-rank component and a sparse component, and then using a novel optimization procedure to reconstruct the original weights from the quantized values.
• Experiments on a range of LLMs, including BERT and GPT-2, show that LQER can achieve up to 8x compression with negligible accuracy loss, outperforming previous state-of-the-art quantization methods like AWQ and L4Q.
Critical Analysis
• While LQER demonstrates impressive compression results, the authors do not provide a thorough analysis of its computational and memory overhead, which could be a limiting factor in real-world deployment.
• Additionally, the paper does not explore the robustness of LQER to different types of model architectures or training regimes, and it would be valuable to see its performance on a wider range of LLMs.
• Finally, the authors could have delved deeper into the underlying reasons for the low-rank structure of the quantization error, which could lead to further insights and improvements in the field of model compression.
Conclusion
• The LQER technique presented in this paper represents a significant advancement in the field of efficient compression for large language models.
• By leveraging the low-rank structure of quantization errors, LQER can achieve high compression rates while preserving model performance, paving the way for the deployment of powerful LLMs on a wide range of resource-constrained devices.
• This work has the potential to unlock new applications and opportunities in areas such as edge computing, mobile AI, and efficient cloud-based inference, ultimately making LLMs more accessible and impactful.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LQER: Low-Rank Quantization Error Reconstruction for LLMs
Cheng Zhang, Jianyi Cheng, George A. Constantinides, Yiren Zhao
Post-training quantization of Large Language Models (LLMs) is challenging. In this work, we introduce Low-rank Quantization Error Reduction (LQER), which combines quantization and low-rank approximation to recover the model capability. LQER leverages an activation-induced scale matrix to drive the singular value distribution of quantization error towards a desirable distribution, which enables nearly-lossless W4A8 quantization on various LLMs and downstream tasks without the need for knowledge distillation, grid search, or gradient-base iterative optimization. Unlike existing methods, the computation pattern of LQER eliminates the need for specialized Scatter and Gather processes to collect high-precision weights from irregular memory locations. Our W4A8 LLMs achieve near-lossless performance on six popular downstream tasks, while using 1.36$times$ fewer hardware resources than the leading state-of-the-art method. We open-source our framework at https://github.com/ChengZhang-98/lqer
Read more5/31/2024

0
Low-Rank Quantization-Aware Training for LLMs
Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel
Large language models (LLMs) are omnipresent, however their practical deployment is challenging due to their ever increasing computational and memory demands. Quantization is one of the most effective ways to make them more compute and memory efficient. Quantization-aware training (QAT) methods, generally produce the best quantized performance, however it comes at the cost of potentially long training time and excessive memory usage, making it impractical when applying for LLMs. Inspired by parameter-efficient fine-tuning (PEFT) and low-rank adaptation (LoRA) literature, we propose LR-QAT -- a lightweight and memory-efficient QAT algorithm for LLMs. LR-QAT employs several components to save memory without sacrificing predictive performance: (a) low-rank auxiliary weights that are aware of the quantization grid; (b) a downcasting operator using fixed-point or double-packed integers and (c) checkpointing. Unlike most related work, our method (i) is inference-efficient, leading to no additional overhead compared to traditional PTQ; (ii) can be seen as a general extended pretraining framework, meaning that the resulting model can still be utilized for any downstream task afterwards; (iii) can be applied across a wide range of quantization settings, such as different choices quantization granularity, activation quantization, and seamlessly combined with many PTQ techniques. We apply LR-QAT to LLaMA-1/2/3 and Mistral model families and validate its effectiveness on several downstream tasks. Our method outperforms common post-training quantization (PTQ) approaches and reaches the same model performance as full-model QAT at the fraction of its memory usage. Specifically, we can train a 7B LLM on a single consumer grade GPU with 24GB of memory. Our source code is available at https://github.com/qualcomm-ai-research/LR-QAT
Read more9/4/2024

0
LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices
Jung Hyun Lee, Jeonghoon Kim, June Yong Yang, Se Jung Kwon, Eunho Yang, Kang Min Yoo, Dongsoo Lee
With the commercialization of large language models (LLMs), weight-activation quantization has emerged to compress and accelerate LLMs, achieving high throughput while reducing inference costs. However, existing post-training quantization (PTQ) techniques for quantizing weights and activations of LLMs still suffer from non-negligible accuracy drops, especially on massive multitask language understanding. To address this issue, we propose Low-Rank Quantization (LRQ) $-$ a simple yet effective post-training weight quantization method for LLMs that reconstructs the outputs of an intermediate Transformer block by leveraging low-rank weight-scaling matrices, replacing the conventional full weight-scaling matrices that entail as many learnable scales as their associated weights. Thanks to parameter sharing via low-rank structure, LRQ only needs to learn significantly fewer parameters while enabling the individual scaling of weights, thus boosting the generalization capability of quantized LLMs. We show the superiority of LRQ over prior LLM PTQ works under (i) $8$-bit weight and per-tensor activation quantization, (ii) $4$-bit weight and $8$-bit per-token activation quantization, and (iii) low-bit weight-only quantization schemes. Our code is available at url{https://github.com/onliwad101/FlexRound_LRQ} to inspire LLM researchers and engineers.
Read more7/17/2024
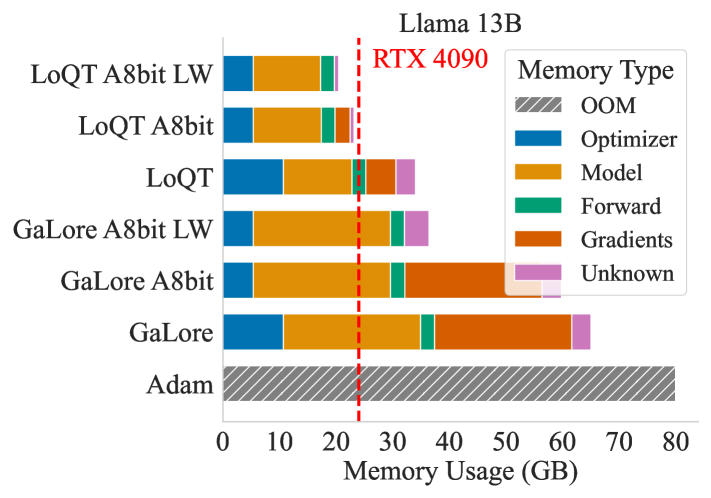
0
LoQT: Low Rank Adapters for Quantized Training
Sebastian Loeschcke, Mads Toftrup, Michael J. Kastoryano, Serge Belongie, V'esteinn Sn{ae}bjarnarson
Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
Read more9/10/2024