LTL-Transfer: Skill Transfer for Temporal Task Specification

0
🔄
Sign in to get full access
Overview
- Deploying robots in real-world environments, such as households and manufacturing lines, requires the ability to generalize across novel task specifications without violating safety constraints.
- Linear Temporal Logic (LTL) is a widely used task specification language that has a compositional grammar, allowing for commonalities among tasks while preserving safety guarantees.
- Prior work on reinforcement learning with LTL specifications treats each new task independently, requiring large amounts of training data to generalize.
- The proposed approach, LTL-Transfer, is a zero-shot transfer algorithm that composes task-agnostic skills learned during training to safely satisfy a wide variety of novel LTL task specifications.
Plain English Explanation
LTL-Transfer: Zero-Shot Transfer of Temporal Logic Specifications for Reinforcement Learning presents a novel approach to enable robots to handle a wide range of tasks in real-world environments, such as homes and factories, without violating important safety constraints.
The key idea is to use a task specification language called Linear Temporal Logic (LTL) that allows for compositional task descriptions. This means that there are common elements across different tasks, which can be learned and reused, rather than having to learn each task from scratch.
The researchers developed a zero-shot transfer algorithm called LTL-Transfer that can take the skills learned from a relatively small number of training tasks (e.g., 50) and apply them to solve a much larger set of novel, unseen tasks (e.g., over 90% of 100 challenging tasks and 100% of 300 common tasks) without violating any safety constraints.
This is a significant advance over previous approaches, which treated each new task independently and required large amounts of training data to generalize. By leveraging the compositional structure of LTL, LTL-Transfer can efficiently transfer knowledge to handle a wide variety of tasks, making it a promising approach for deploying robots in real-world environments.
Technical Explanation
LTL-Transfer is a zero-shot transfer algorithm that composes task-agnostic skills learned during training to safely satisfy a wide variety of novel Linear Temporal Logic (LTL) task specifications.
The key technical insights are:
- Leveraging the Compositional Structure of LTL: LTL has a structured grammar that naturally induces commonalities among tasks, allowing for the learning of transferable skills.
- Task-Agnostic Skill Learning: During the training phase, the algorithm learns a set of task-agnostic skills that can be composed to satisfy a variety of novel LTL specifications.
- Zero-Shot Transfer: At deployment, LTL-Transfer can rapidly compose the learned skills to solve new tasks without any additional training, enabling zero-shot transfer.
The researchers evaluated LTL-Transfer in Minecraft-inspired domains and on a quadruped mobile manipulator robot. The experiments showed that after training on only 50 tasks, LTL-Transfer can solve over 90% of 100 challenging unseen tasks and 100% of 300 commonly used novel tasks without violating any safety constraints.
This zero-shot transfer capability is a significant advancement over prior approaches, which treated each new task independently and required large amounts of training data to generalize.
Critical Analysis
The paper presents a promising approach for enabling robots to handle a wide range of tasks in real-world environments while preserving important safety constraints. The key strengths of LTL-Transfer are its ability to leverage the compositional structure of LTL and learn transferable skills that can be rapidly composed to solve novel tasks.
However, the paper does not address several potential limitations and areas for further research:
- Scalability to more complex environments and tasks: While the experiments demonstrate impressive results in Minecraft-inspired domains and on a quadruped mobile manipulator, it's unclear how well LTL-Transfer would scale to more complex real-world environments and tasks.
- Robustness to noisy or uncertain observations: The paper does not discuss how LTL-Transfer would handle noisy or incomplete sensor data, which is a common challenge in real-world deployments.
- Interaction with human operators: The paper does not explore how LTL-Transfer could be integrated with human-in-the-loop decision-making processes, which are often necessary for safety-critical applications.
Further research could investigate these areas to better understand the practical limitations and potential of LTL-Transfer for real-world robot deployment.
Conclusion
LTL-Transfer is a promising approach for enabling robots to handle a wide range of tasks in real-world environments while preserving important safety constraints. By leveraging the compositional structure of Linear Temporal Logic (LTL) and learning transferable skills, the algorithm can rapidly solve novel tasks without any additional training, a significant advancement over prior work.
While the paper demonstrates impressive results in simulated environments and on a quadruped mobile manipulator, further research is needed to address potential limitations, such as scalability to more complex real-world scenarios and robustness to noisy or uncertain observations. Integrating LTL-Transfer with human-in-the-loop decision-making processes could also be an important area for future exploration, particularly for safety-critical applications.
Overall, the LTL-Transfer approach represents an important step forward in enabling robots to safely and flexibly operate in a wide range of real-world environments, with the potential to have significant implications for a variety of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
LTL-Transfer: Skill Transfer for Temporal Task Specification
Jason Xinyu Liu, Ankit Shah, Eric Rosen, Mingxi Jia, George Konidaris, Stefanie Tellex
Deploying robots in real-world environments, such as households and manufacturing lines, requires generalization across novel task specifications without violating safety constraints. Linear temporal logic (LTL) is a widely used task specification language with a compositional grammar that naturally induces commonalities among tasks while preserving safety guarantees. However, most prior work on reinforcement learning with LTL specifications treats every new task independently, thus requiring large amounts of training data to generalize. We propose LTL-Transfer, a zero-shot transfer algorithm that composes task-agnostic skills learned during training to safely satisfy a wide variety of novel LTL task specifications. Experiments in Minecraft-inspired domains show that after training on only 50 tasks, LTL-Transfer can solve over 90% of 100 challenging unseen tasks and 100% of 300 commonly used novel tasks without violating any safety constraints. We deployed LTL-Transfer at the task-planning level of a quadruped mobile manipulator to demonstrate its zero-shot transfer ability for fetch-and-deliver and navigation tasks.
Read more8/29/2024
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
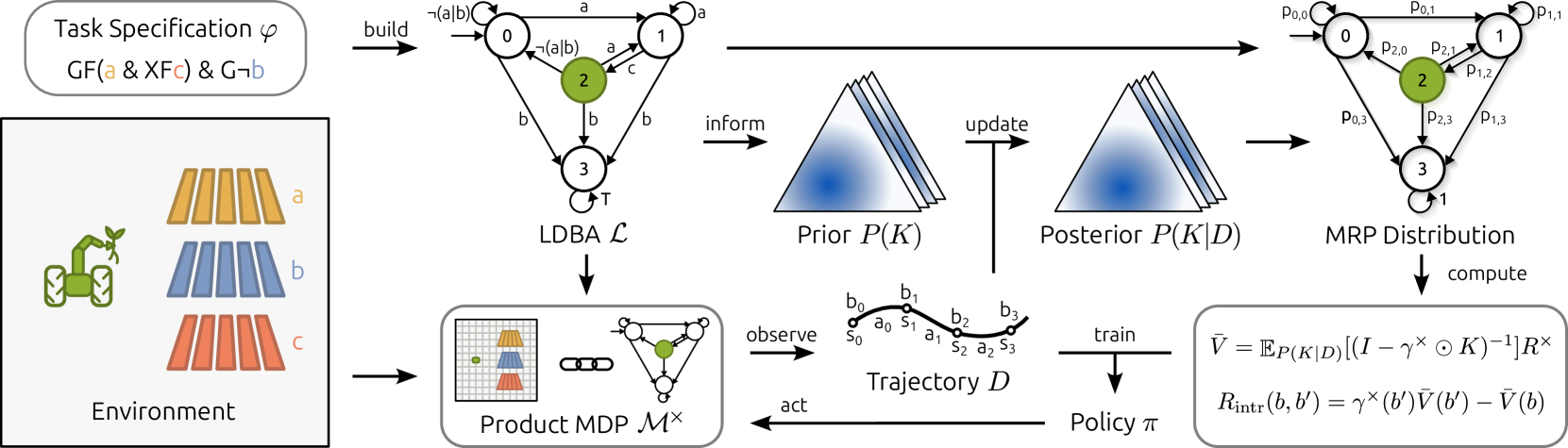
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024
🏅
0
Logical Specifications-guided Dynamic Task Sampling for Reinforcement Learning Agents
Yash Shukla, Tanushree Burman, Abhishek Kulkarni, Robert Wright, Alvaro Velasquez, Jivko Sinapov
Reinforcement Learning (RL) has made significant strides in enabling artificial agents to learn diverse behaviors. However, learning an effective policy often requires a large number of environment interactions. To mitigate sample complexity issues, recent approaches have used high-level task specifications, such as Linear Temporal Logic (LTL$_f$) formulas or Reward Machines (RM), to guide the learning progress of the agent. In this work, we propose a novel approach, called Logical Specifications-guided Dynamic Task Sampling (LSTS), that learns a set of RL policies to guide an agent from an initial state to a goal state based on a high-level task specification, while minimizing the number of environmental interactions. Unlike previous work, LSTS does not assume information about the environment dynamics or the Reward Machine, and dynamically samples promising tasks that lead to successful goal policies. We evaluate LSTS on a gridworld and show that it achieves improved time-to-threshold performance on complex sequential decision-making problems compared to state-of-the-art RM and Automaton-guided RL baselines, such as Q-Learning for Reward Machines and Compositional RL from logical Specifications (DIRL). Moreover, we demonstrate that our method outperforms RM and Automaton-guided RL baselines in terms of sample-efficiency, both in a partially observable robotic task and in a continuous control robotic manipulation task.
Read more4/4/2024
🛸
0
Simultaneous Task Allocation and Planning for Multi-Robots under Hierarchical Temporal Logic Specifications
Xusheng Luo, Changliu Liu
Research in robotic planning with temporal logic specifications, such as syntactically co-safe Linear Temporal Logic (sc-LTL), has relied on single formulas. However, as task complexity increases, sc-LTL formulas become lengthy, making them difficult to interpret and generate, and straining the computational capacities of planners. To address this, we introduce a hierarchical structure to sc-LTL specifications with both syntax and semantics, proving it to be more expressive than flat counterparts. We conducted a user study that compared the flat sc-LTL with our hierarchical version and found that users could more easily comprehend complex tasks using the hierarchical structure. We develop a search-based approach to synthesize plans for multi-robot systems, achieving simultaneous task allocation and planning. This method approximates the search space by loosely interconnected sub-spaces, each corresponding to an sc-LTL specification. The search primarily focuses on a single sub-space, transitioning to another under conditions determined by the decomposition of automatons. We develop multiple heuristics to significantly expedite the search. Our theoretical analysis, conducted under mild assumptions, addresses completeness and optimality. Compared to existing methods used in various simulators for service tasks, our approach improves planning times while maintaining comparable solution quality.
Read more8/16/2024