Directed Exploration in Reinforcement Learning from Linear Temporal Logic

0
Sign in to get full access
Overview
- Reinforcement learning agents often struggle to efficiently explore their environment and discover all the relevant states and behaviors needed to complete complex tasks.
- This paper proposes a new approach called "Directed Exploration in Reinforcement Learning from Linear Temporal Logic" that guides exploration based on Linear Temporal Logic (LTL) specifications.
- The key idea is to use LTL to formally specify desired agent behaviors, and then use this information to direct the agent's exploration towards states and actions that satisfy the LTL specifications.
Plain English Explanation
In reinforcement learning, an agent learns by interacting with its environment and receiving rewards or penalties for its actions. However, it can be challenging for the agent to efficiently explore all the relevant parts of the environment, especially for complex tasks. This paper introduces a new method that aims to guide the agent's exploration using formal specifications written in a language called Linear Temporal Logic (LTL).
LTL allows the researcher to precisely define the behaviors they want the agent to learn, such as "visit location A, then location B, while avoiding obstacles." The key insight of this paper is to use this LTL specification to direct the agent's exploration towards states and actions that satisfy the desired behaviors.
For example, if the LTL specification says the agent should visit location A and then location B, the exploration strategy will focus on finding paths that lead the agent to those locations in the right order, rather than randomly wandering. This "directed exploration" allows the agent to more efficiently discover the relevant parts of the environment needed to complete the task.
The paper demonstrates that this LTL-guided exploration approach can outperform standard exploration methods, especially for complex tasks with rich specification requirements. By incorporating high-level behavioral guidance, the agent is able to explore more strategically and learn the desired behaviors more quickly.
Technical Explanation
The paper introduces a reinforcement learning framework that uses Linear Temporal Logic (LTL) to guide the agent's exploration of the environment. LTL is a formal language that can precisely specify complex temporal properties, such as sequences of actions, visited states, and safety constraints.
The key idea is to define an LTL formula that encodes the desired agent behaviors, and then use this formula to shape the agent's exploration. Specifically, the authors propose a exploration bonus that rewards the agent for visiting states that are deemed "promising" according to the LTL specification.
The exploration bonus is computed using a technique called automata-based reward shaping, which involves constructing a deterministic finite automaton (DFA) from the LTL formula. The DFA tracks the agent's progress towards satisfying the LTL specification, and the exploration bonus is proportional to the agent's proximity to satisfying the specification.
The authors evaluate their approach, called LTL-Guided Exploration (LTL-GE), on a variety of benchmark reinforcement learning environments. The results demonstrate that LTL-GE can significantly outperform standard exploration methods, especially on tasks with complex LTL specifications that require long-term planning and goal-directed behavior.
Critical Analysis
The key strength of this approach is its ability to leverage high-level task specifications to guide exploration in a principled way. By incorporating the LTL formula, the agent can focus its exploration on the most relevant parts of the environment, rather than blindly wandering. This is particularly helpful for complex tasks where naive exploration strategies may struggle to discover all the necessary behaviors.
That said, the paper does not address some potential limitations of the approach. For example, the construction of the DFA from the LTL formula can be computationally expensive, especially for complex specifications. This could limit the scalability of the method to very large state spaces or long-horizon tasks.
Additionally, the paper does not discuss how the LTL specification itself is obtained. In many real-world scenarios, defining the appropriate LTL formula may require significant domain expertise and careful consideration of the task requirements. Automating or simplifying this process could further improve the practical applicability of the approach.
Overall, the LTL-GE method represents an interesting and promising direction for improving exploration in reinforcement learning. By incorporating high-level task guidance, the agent can learn more efficiently and discover behaviors that better align with the desired objectives. Future work could explore ways to address the computational challenges and make the specification process more accessible to non-experts.
Conclusion
This paper presents a novel approach called "Directed Exploration in Reinforcement Learning from Linear Temporal Logic" that uses formal specifications written in Linear Temporal Logic (LTL) to guide an agent's exploration of its environment. The key insight is to leverage the LTL formula to direct the agent's exploration towards states and actions that satisfy the desired behaviors, rather than relying on more naive exploration strategies.
The results demonstrate that this LTL-guided exploration can significantly outperform standard methods, particularly for complex tasks with rich specification requirements. By incorporating high-level behavioral guidance, the agent is able to explore more strategically and learn the desired behaviors more quickly.
While the approach shows promise, it also has some potential limitations, such as the computational complexity of constructing the DFA from the LTL formula. Addressing these challenges and further improving the accessibility of the LTL specification process could help make this technique more practical for a wider range of reinforcement learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
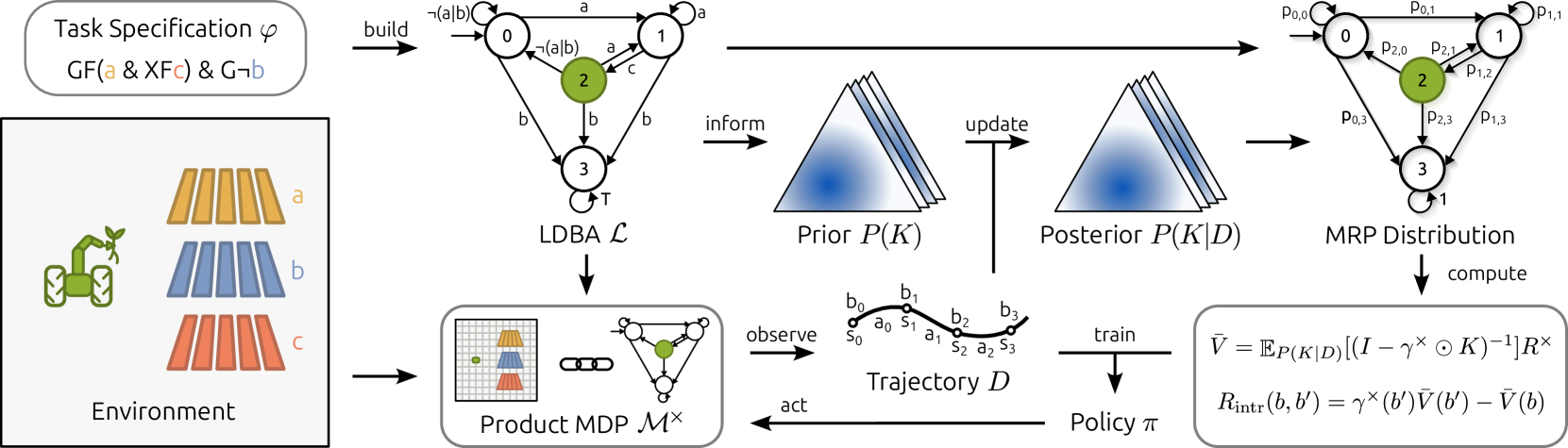
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024
🔄
0
LTL-Transfer: Skill Transfer for Temporal Task Specification
Jason Xinyu Liu, Ankit Shah, Eric Rosen, Mingxi Jia, George Konidaris, Stefanie Tellex
Deploying robots in real-world environments, such as households and manufacturing lines, requires generalization across novel task specifications without violating safety constraints. Linear temporal logic (LTL) is a widely used task specification language with a compositional grammar that naturally induces commonalities among tasks while preserving safety guarantees. However, most prior work on reinforcement learning with LTL specifications treats every new task independently, thus requiring large amounts of training data to generalize. We propose LTL-Transfer, a zero-shot transfer algorithm that composes task-agnostic skills learned during training to safely satisfy a wide variety of novel LTL task specifications. Experiments in Minecraft-inspired domains show that after training on only 50 tasks, LTL-Transfer can solve over 90% of 100 challenging unseen tasks and 100% of 300 commonly used novel tasks without violating any safety constraints. We deployed LTL-Transfer at the task-planning level of a quadruped mobile manipulator to demonstrate its zero-shot transfer ability for fetch-and-deliver and navigation tasks.
Read more8/29/2024
🏅
0
Logical Specifications-guided Dynamic Task Sampling for Reinforcement Learning Agents
Yash Shukla, Tanushree Burman, Abhishek Kulkarni, Robert Wright, Alvaro Velasquez, Jivko Sinapov
Reinforcement Learning (RL) has made significant strides in enabling artificial agents to learn diverse behaviors. However, learning an effective policy often requires a large number of environment interactions. To mitigate sample complexity issues, recent approaches have used high-level task specifications, such as Linear Temporal Logic (LTL$_f$) formulas or Reward Machines (RM), to guide the learning progress of the agent. In this work, we propose a novel approach, called Logical Specifications-guided Dynamic Task Sampling (LSTS), that learns a set of RL policies to guide an agent from an initial state to a goal state based on a high-level task specification, while minimizing the number of environmental interactions. Unlike previous work, LSTS does not assume information about the environment dynamics or the Reward Machine, and dynamically samples promising tasks that lead to successful goal policies. We evaluate LSTS on a gridworld and show that it achieves improved time-to-threshold performance on complex sequential decision-making problems compared to state-of-the-art RM and Automaton-guided RL baselines, such as Q-Learning for Reward Machines and Compositional RL from logical Specifications (DIRL). Moreover, we demonstrate that our method outperforms RM and Automaton-guided RL baselines in terms of sample-efficiency, both in a partially observable robotic task and in a continuous control robotic manipulation task.
Read more4/4/2024

0
Integrating Explanations in Learning LTL Specifications from Demonstrations
Ashutosh Gupta, John Komp, Abhay Singh Rajput, Krishna Shankaranarayanan, Ashutosh Trivedi, Namrita Varshney
This paper investigates whether recent advances in Large Language Models (LLMs) can assist in translating human explanations into a format that can robustly support learning Linear Temporal Logic (LTL) from demonstrations. Both LLMs and optimization-based methods can extract LTL specifications from demonstrations; however, they have distinct limitations. LLMs can quickly generate solutions and incorporate human explanations, but their lack of consistency and reliability hampers their applicability in safety-critical domains. On the other hand, optimization-based methods do provide formal guarantees but cannot process natural language explanations and face scalability challenges. We present a principled approach to combining LLMs and optimization-based methods to faithfully translate human explanations and demonstrations into LTL specifications. We have implemented a tool called Janaka based on our approach. Our experiments demonstrate the effectiveness of combining explanations with demonstrations in learning LTL specifications through several case studies.
Read more4/4/2024