M3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation

0

Sign in to get full access
Overview
- This paper introduces a new benchmark dataset called M3T (Multimodal Multi-Modal Machine Translation) for evaluating machine translation systems that can utilize both text and images.
- The dataset consists of over 200,000 document-level image-text pairs in 8 language pairs, making it the largest multimodal machine translation dataset to date.
- The goal is to spur research in multimodal machine translation, which aims to improve translation quality by leveraging both textual and visual information.
Plain English Explanation
The paper presents a new dataset called M3T that can be used to train and evaluate machine translation systems that can utilize both text and images. Machine translation is the process of automatically translating text from one language to another. Traditionally, machine translation systems have only used the text itself to perform the translation.
However, the authors of this paper argue that incorporating visual information, such as images that accompany the text, can improve the quality of the translation. This is known as multimodal machine translation. The M3T dataset provides over 200,000 examples of document-level image-text pairs across 8 different language pairs, making it the largest dataset of its kind.
By creating this comprehensive dataset, the researchers hope to spur more research and development in the emerging field of multimodal machine translation. The ability to leverage both textual and visual information could lead to significant improvements in translation accuracy and fluency, with applications in areas like international business, education, and cultural exchange.
Technical Explanation
The M3T dataset consists of over 200,000 document-level image-text pairs in 8 language pairs: English-German, English-Spanish, English-French, English-Italian, English-Chinese, English-Japanese, English-Korean, and English-Russian. This makes it the largest multimodal machine translation dataset to date, surpassing previous benchmarks like link to M$DOLLAR3$DOLLARCoT dataset and link to survey paper on multimodal MT.
The image-text pairs were sourced from a variety of online sources, including news articles, blog posts, and educational materials. The texts were professionally translated, and the dataset includes both sentence-level and document-level alignments between the source and target languages.
The authors evaluate several existing multimodal machine translation models on the M3T dataset, including link to 3AM paper and link to paper on escaping sentence-level paradigm. They find that the models struggle to effectively utilize the visual information, particularly at the document level, suggesting that the M3T dataset can serve as a challenging benchmark to spur further advancements in the field.
Critical Analysis
The M3T dataset represents a significant contribution to the field of multimodal machine translation. By providing a large-scale, high-quality dataset with document-level alignments, the authors have addressed a key limitation of previous benchmarks, which have tended to focus on sentence-level translation.
However, the dataset is not without its limitations. The authors acknowledge that the image-text pairs may not always be closely related, and the dataset does not include any information about the context or provenance of the documents. Additionally, the dataset is limited to 8 language pairs, which may not be representative of the full diversity of the world's languages.
Furthermore, the authors' evaluation of existing multimodal machine translation models on the M3T dataset suggests that there is still significant room for improvement in this area. The models struggled to effectively utilize the visual information, particularly at the document level, highlighting the need for more advanced techniques and architectures to address the challenges of multimodal machine translation.
Conclusion
The M3T dataset represents a significant step forward in the field of multimodal machine translation. By providing a large-scale, high-quality dataset with document-level alignments, the authors have created a valuable resource for researchers and developers working in this area. The dataset's size and diversity offer the potential to spur further advancements in the field, leading to improvements in translation quality and fluency that could have far-reaching impacts in areas like international business, education, and cultural exchange.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
M3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Benjamin Hsu, Xiaoyu Liu, Huayang Li, Yoshinari Fujinuma, Maria Nadejde, Xing Niu, Yair Kittenplon, Ron Litman, Raghavendra Pappagari
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.
Read more6/13/2024
0
3AM: An Ambiguity-Aware Multi-Modal Machine Translation Dataset
Xinyu Ma, Xuebo Liu, Derek F. Wong, Jun Rao, Bei Li, Liang Ding, Lidia S. Chao, Dacheng Tao, Min Zhang
Multimodal machine translation (MMT) is a challenging task that seeks to improve translation quality by incorporating visual information. However, recent studies have indicated that the visual information provided by existing MMT datasets is insufficient, causing models to disregard it and overestimate their capabilities. This issue presents a significant obstacle to the development of MMT research. This paper presents a novel solution to this issue by introducing 3AM, an ambiguity-aware MMT dataset comprising 26,000 parallel sentence pairs in English and Chinese, each with corresponding images. Our dataset is specifically designed to include more ambiguity and a greater variety of both captions and images than other MMT datasets. We utilize a word sense disambiguation model to select ambiguous data from vision-and-language datasets, resulting in a more challenging dataset. We further benchmark several state-of-the-art MMT models on our proposed dataset. Experimental results show that MMT models trained on our dataset exhibit a greater ability to exploit visual information than those trained on other MMT datasets. Our work provides a valuable resource for researchers in the field of multimodal learning and encourages further exploration in this area. The data, code and scripts are freely available at https://github.com/MaxyLee/3AM.
Read more4/30/2024
0
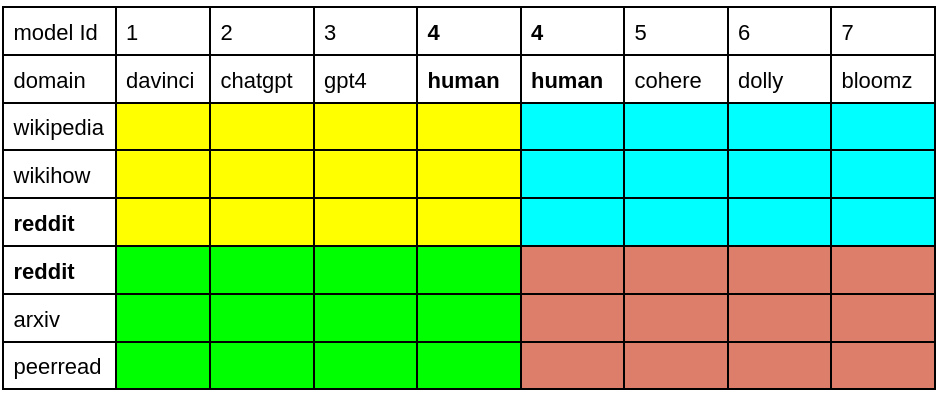
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Osama Mohanned Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, Alham Fikri Aji, Nizar Habash, Iryna Gurevych, Preslav Nakov
The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark based on a multilingual, multi-domain, and multi-generator corpus of MGTs -- M4GT-Bench. The benchmark is compiled of three tasks: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection where one need to identify, which particular model generated the text; and (3) mixed human-machine text detection, where a word boundary delimiting MGT from human-written content should be determined. On the developed benchmark, we have tested several MGT detection baselines and also conducted an evaluation of human performance. We see that obtaining good performance in MGT detection usually requires an access to the training data from the same domain and generators. The benchmark is available at https://github.com/mbzuai-nlp/M4GT-Bench.
Read more6/28/2024

0
M3T: Multi-Modal Medical Transformer to bridge Clinical Context with Visual Insights for Retinal Image Medical Description Generation
Nagur Shareef Shaik, Teja Krishna Cherukuri, Dong Hye Ye
Automated retinal image medical description generation is crucial for streamlining medical diagnosis and treatment planning. Existing challenges include the reliance on learned retinal image representations, difficulties in handling multiple imaging modalities, and the lack of clinical context in visual representations. Addressing these issues, we propose the Multi-Modal Medical Transformer (M3T), a novel deep learning architecture that integrates visual representations with diagnostic keywords. Unlike previous studies focusing on specific aspects, our approach efficiently learns contextual information and semantics from both modalities, enabling the generation of precise and coherent medical descriptions for retinal images. Experimental studies on the DeepEyeNet dataset validate the success of M3T in meeting ophthalmologists' standards, demonstrating a substantial 13.5% improvement in BLEU@4 over the best-performing baseline model.
Read more6/21/2024