M$^3$CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought
2405.16473
0
0

Abstract
Multi-modal Chain-of-Thought (MCoT) requires models to leverage knowledge from both textual and visual modalities for step-by-step reasoning, which gains increasing attention. Nevertheless, the current MCoT benchmark still faces some challenges: (1) absence of visual modal reasoning, (2) single-step visual modal reasoning, and (3) Domain missing, thereby hindering the development of MCoT. Motivated by this, we introduce a novel benchmark (M$^3$CoT) to address the above challenges, advancing the multi-domain, multi-step, and multi-modal CoT. Additionally, we conduct a thorough evaluation involving abundant MCoT approaches on Vision Large Language Models (VLLMs). In addition, we highlight that the current VLLMs still struggle to correctly reason in M$^3$CoT and there remains a large gap between existing VLLMs and human performance in M$^3$CoT, despite their superior results on previous MCoT benchmarks. To our knowledge, we take the first meaningful step toward the multi-domain, multi-step, and multi-modal scenario in MCoT. We hope that M$^3$CoT can serve as a valuable resource, providing a pioneering foundation in multi-domain, multi-step, multi-modal chain-of-thought research.
Create account to get full access
Overview
- Introduces a novel benchmark called M3CoT (Multi-Domain Multi-step Multi-modal Chain-of-Thought) for evaluating the ability of language models to engage in multi-step, multi-modal reasoning.
- Highlights the importance of developing AI systems that can tackle complex, real-world problems that require chaining together multiple steps of reasoning across different modalities (e.g., text, images, etc.).
- Discusses related work in areas like VoCOT, TextCoT, and MM-PhyQA.
Plain English Explanation
The paper introduces a new benchmark called M3CoT that is designed to test the ability of AI language models to engage in complex, multi-step reasoning across different types of information, such as text and images. The idea is that in the real world, many problems require chaining together multiple steps of logic and using information from various sources to arrive at a solution.
For example, imagine you are trying to figure out how to fix a leaky faucet. You might need to first identify the specific problem by examining the faucet, then look up instructions on how to replace the washer, and finally actually carry out the repair. This type of stepwise, multi-modal reasoning is challenging for current AI systems, but is crucial for building AI that can truly assist humans with complex, real-world tasks.
The M3CoT benchmark aims to provide a standardized way to evaluate how well language models can perform this type of multi-step, multi-modal reasoning. The researchers draw inspiration from related work like VoCOT, which focuses on visually-grounded reasoning, and TextCoT, which looks at reasoning over text-rich images. By developing benchmarks like M3CoT, the goal is to push the boundaries of what AI systems can do and bring us closer to building AI assistants that can truly understand and tackle complex problems.
Technical Explanation
The paper formalizes the Multi-Domain Multi-step Multi-modal Chain-of-Thought (M3CoT) problem, which involves solving a sequence of sub-tasks that require reasoning across different modalities (e.g., text, images) and domains (e.g., science, math, commonsense).
The authors propose a novel benchmark dataset for M3CoT, which consists of multi-step reasoning problems spanning various real-world domains. Each problem in the dataset includes a sequence of sub-tasks, where each sub-task may involve text, images, or a combination of both. The goal is for language models to demonstrate their ability to break down complex problems, leverage information from multiple modalities, and chain together coherent reasoning steps to arrive at the final solution.
To establish a strong baseline, the authors evaluate several large language models, including GPT-3, on the M3CoT benchmark. They find that while these models can handle individual sub-tasks, they struggle to maintain coherent, multi-step reasoning across the entire problem. This highlights the need for further advancements in areas like multi-modal understanding, reasoning, and task planning to tackle the challenges posed by the M3CoT benchmark.
Critical Analysis
The M3CoT benchmark represents an important step forward in evaluating the capabilities of language models to engage in complex, real-world reasoning. By focusing on multi-step, multi-modal problems, the authors are pushing the boundaries of what current AI systems can do and identifying key areas for improvement.
One potential limitation of the M3CoT benchmark is the scope and diversity of the problems it covers. While the authors attempt to span a range of real-world domains, there may be certain types of problems or reasoning patterns that are not well-represented in the dataset. Additionally, the benchmark may not capture the full complexity of real-world problem-solving, which often involves dealing with ambiguity, uncertainty, and the need to adapt to changing circumstances.
Another area for further exploration is the role of external knowledge and commonsense reasoning in tackling M3CoT problems. The current evaluation focuses on the language models' ability to chain together reasoning steps, but it may be valuable to also consider how these models can leverage and integrate external information to inform their decision-making.
Overall, the M3CoT benchmark represents an important contribution to the field of AI research, and the insights gained from evaluating language models on this task can inform the development of more capable and versatile AI systems that can truly assist humans in complex, real-world problem-solving.
Conclusion
The M3CoT benchmark introduced in this paper is a significant advancement in the field of AI, as it highlights the need for language models to go beyond simple text understanding and engage in complex, multi-step, multi-modal reasoning. By challenging these models to tackle problems that require chaining together information from different sources and domains, the M3CoT benchmark pushes the boundaries of what current AI systems can do and points the way towards building more capable and versatile AI assistants.
The insights gained from evaluating language models on the M3CoT benchmark can inform the development of new techniques and architectures for multi-modal understanding, reasoning, and task planning. As the field of AI continues to evolve, benchmarks like M3CoT will play a crucial role in driving progress and ensuring that the capabilities of AI systems keep pace with the demands of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024
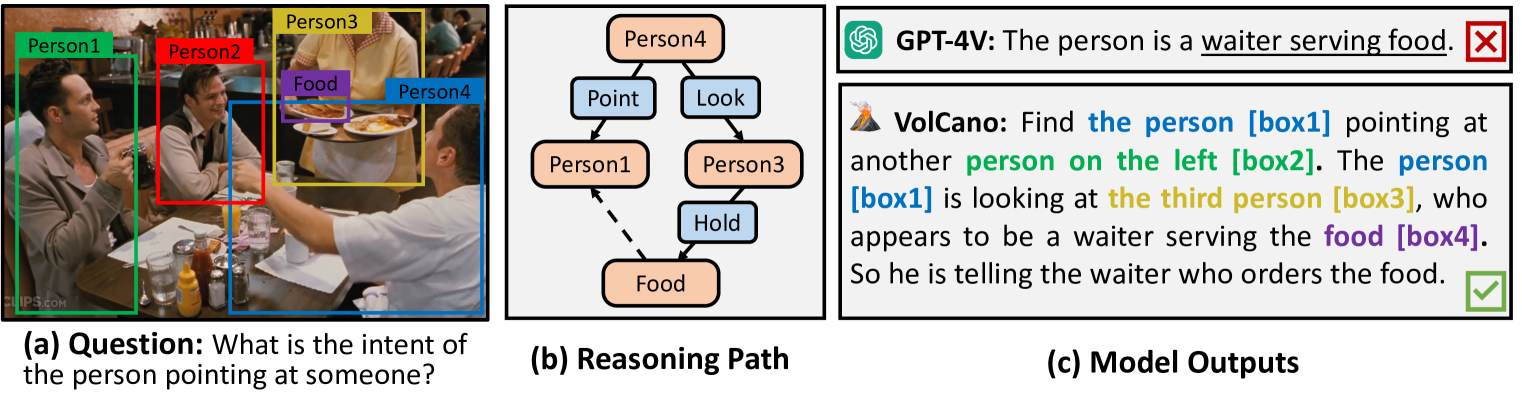
VoCoT: Unleashing Visually Grounded Multi-Step Reasoning in Large Multi-Modal Models
Zejun Li, Ruipu Luo, Jiwen Zhang, Minghui Qiu, Zhongyu Wei
0
0
While large multi-modal models (LMMs) have exhibited impressive capabilities across diverse tasks, their effectiveness in handling complex tasks has been limited by the prevailing single-step reasoning paradigm. To this end, this paper proposes VoCoT, a multi-step Visually grounded object-centric Chain-of-Thought reasoning framework tailored for inference with LMMs. VoCoT is characterized by two key features: (1) object-centric reasoning paths that revolve around cross-modal shared object-level information, and (2) visually grounded representation of object concepts in a multi-modal interleaved and aligned manner, which effectively bridges the modality gap within LMMs during long-term generation. Additionally, we construct an instruction dataset to facilitate LMMs in adapting to reasoning with VoCoT. By introducing VoCoT into the prevalent open-source LMM architecture, we introduce VolCano. With only 7B parameters and limited input resolution, VolCano demonstrates excellent performance across various scenarios, surpassing SOTA models, including GPT-4V, in tasks requiring complex reasoning. Our code, data and model will be available at https://github.com/RupertLuo/VoCoT.
5/29/2024

TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
Bozhi Luan, Hao Feng, Hong Chen, Yonghui Wang, Wengang Zhou, Houqiang Li
0
0
The advent of Large Multimodal Models (LMMs) has sparked a surge in research aimed at harnessing their remarkable reasoning abilities. However, for understanding text-rich images, challenges persist in fully leveraging the potential of LMMs, and existing methods struggle with effectively processing high-resolution images. In this work, we propose TextCoT, a novel Chain-of-Thought framework for text-rich image understanding. TextCoT utilizes the captioning ability of LMMs to grasp the global context of the image and the grounding capability to examine local textual regions. This allows for the extraction of both global and local visual information, facilitating more accurate question-answering. Technically, TextCoT consists of three stages, including image overview, coarse localization, and fine-grained observation. The image overview stage provides a comprehensive understanding of the global scene information, and the coarse localization stage approximates the image area containing the answer based on the question asked. Then, integrating the obtained global image descriptions, the final stage further examines specific regions to provide accurate answers. Our method is free of extra training, offering immediate plug-and-play functionality. Extensive experiments are conducted on a series of text-rich image question-answering benchmark datasets based on several advanced LMMs, and the results demonstrate the effectiveness and strong generalization ability of our method. Code is available at https://github.com/bzluan/TextCoT.
4/16/2024

mCoT: Multilingual Instruction Tuning for Reasoning Consistency in Language Models
Huiyuan Lai, Malvina Nissim
0
0
Large language models (LLMs) with Chain-of-thought (CoT) have recently emerged as a powerful technique for eliciting reasoning to improve various downstream tasks. As most research mainly focuses on English, with few explorations in a multilingual context, the question of how reliable this reasoning capability is in different languages is still open. To address it directly, we study multilingual reasoning consistency across multiple languages, using popular open-source LLMs. First, we compile the first large-scale multilingual math reasoning dataset, mCoT-MATH, covering eleven diverse languages. Then, we introduce multilingual CoT instruction tuning to boost reasoning capability across languages, thereby improving model consistency. While existing LLMs show substantial variation across the languages we consider, and especially low performance for lesser resourced languages, our 7B parameter model mCoT achieves impressive consistency across languages, and superior or comparable performance to close- and open-source models even of much larger sizes.
6/5/2024