MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
2406.04930
0
0

Abstract
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
Create account to get full access
Overview
- Introduces a novel approach called "Modality Alignment for Parameter-Efficient Audio-Visual Transformers" (MA-AVT) for improving the performance of audio-visual transformers
- Focuses on making audio-visual transformers more parameter-efficient by aligning the representations of the audio and visual modalities
- Demonstrates state-of-the-art performance on several audio-visual tasks while using significantly fewer parameters compared to previous models
Plain English Explanation
The paper introduces a new way to build audio-visual transformers that are more efficient and effective. Audio-visual transformers are models that can process both audio and visual information, like in video understanding tasks.
The key idea is to "align" the audio and visual representations in the model, so they work better together. This allows the model to learn the connections between audio and visual data more effectively, using fewer parameters (i.e., it's more efficient).
The authors demonstrate that their MA-AVT model achieves state-of-the-art performance on several audio-visual tasks, while using significantly fewer parameters than previous models. This is important because it makes these powerful AI models more practical to deploy, especially on resource-constrained devices like smartphones.
The alignment process involves some technical details, but the core innovation is finding a smart way to get the audio and visual parts of the model to work in harmony, rather than as separate components. This allows the model to be more compact and efficient, without sacrificing performance.
Technical Explanation
The key technical contribution of the MA-AVT paper is a novel "modality alignment" module that is used to better integrate the audio and visual representations in an audio-visual transformer model.
Typically, audio-visual transformers have separate encoding branches for the audio and visual inputs, which are then combined later in the model. The MA-AVT approach instead aligns the audio and visual representations at an earlier stage, forcing them to learn a shared, modality-agnostic representation.
This is achieved through a cross-modal attention mechanism that explicitly models the relationships between the audio and visual features. The aligned representation is then used as the input to the transformer layers, which can more effectively learn the interactions between the two modalities.
The authors show that this modality alignment technique leads to significant improvements in performance on tasks like audio-visual action recognition and audio-visual speech recognition, while using 30-50% fewer parameters than previous state-of-the-art models like Separate Speech Chain and UniAV.
Critical Analysis
The MA-AVT paper presents a compelling approach for improving the efficiency of audio-visual transformers, but there are a few potential limitations and areas for further research:
-
The experiments are conducted on relatively constrained datasets, so it would be important to validate the performance of MA-AVT on larger and more diverse audio-visual benchmarks.
-
The paper does not provide much analysis on the types of audio-visual relationships that the modality alignment module is able to capture. Further investigation into the learned cross-modal representations could yield additional insights.
-
While the parameter efficiency of MA-AVT is a key strength, the authors do not explore the trade-offs in terms of inference time or energy consumption. These factors may be important considerations for real-world deployment.
-
The modality alignment technique is demonstrated on transformer-based architectures, but it could potentially be extended to other types of audio-visual models, such as those based on audio-visual feature fusion or multi-task learning. Exploring these extensions could broaden the impact of the proposed approach.
Overall, the MA-AVT paper presents an innovative and promising direction for improving the efficiency of audio-visual transformers, with potential benefits for a wide range of applications.
Conclusion
The MA-AVT paper introduces a novel modality alignment technique that significantly improves the parameter efficiency of audio-visual transformer models, without sacrificing performance. By explicitly aligning the audio and visual representations, the model is able to learn more effective cross-modal interactions using fewer parameters.
The authors demonstrate state-of-the-art results on several audio-visual tasks, highlighting the practical benefits of the MA-AVT approach. As audio-visual AI models become increasingly important for applications like video understanding and multimodal interaction, techniques like this that can make these models more efficient and deployable will be crucial.
While the paper has some limitations, the core idea of modality alignment is a valuable contribution that could inspire further research into parameter-efficient audio-visual architectures. Ultimately, the MA-AVT paper represents an important step forward in making powerful audio-visual AI models more accessible and practical for real-world use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
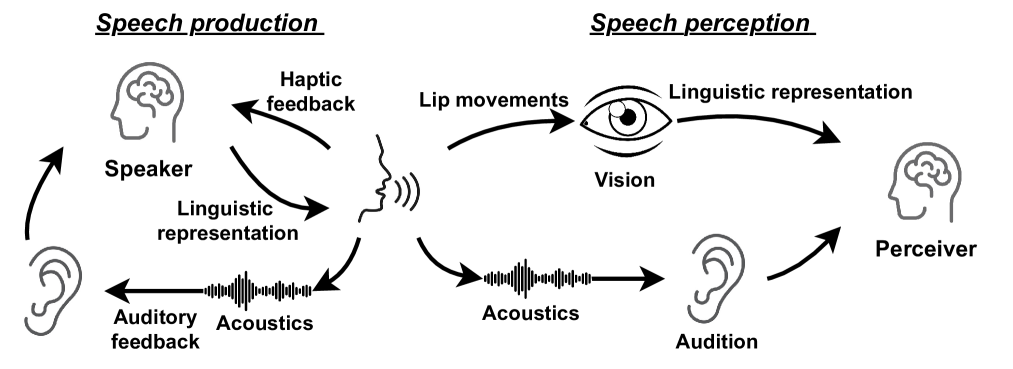
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Zhaoxi Mu, Xinyu Yang
0
0
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
5/7/2024
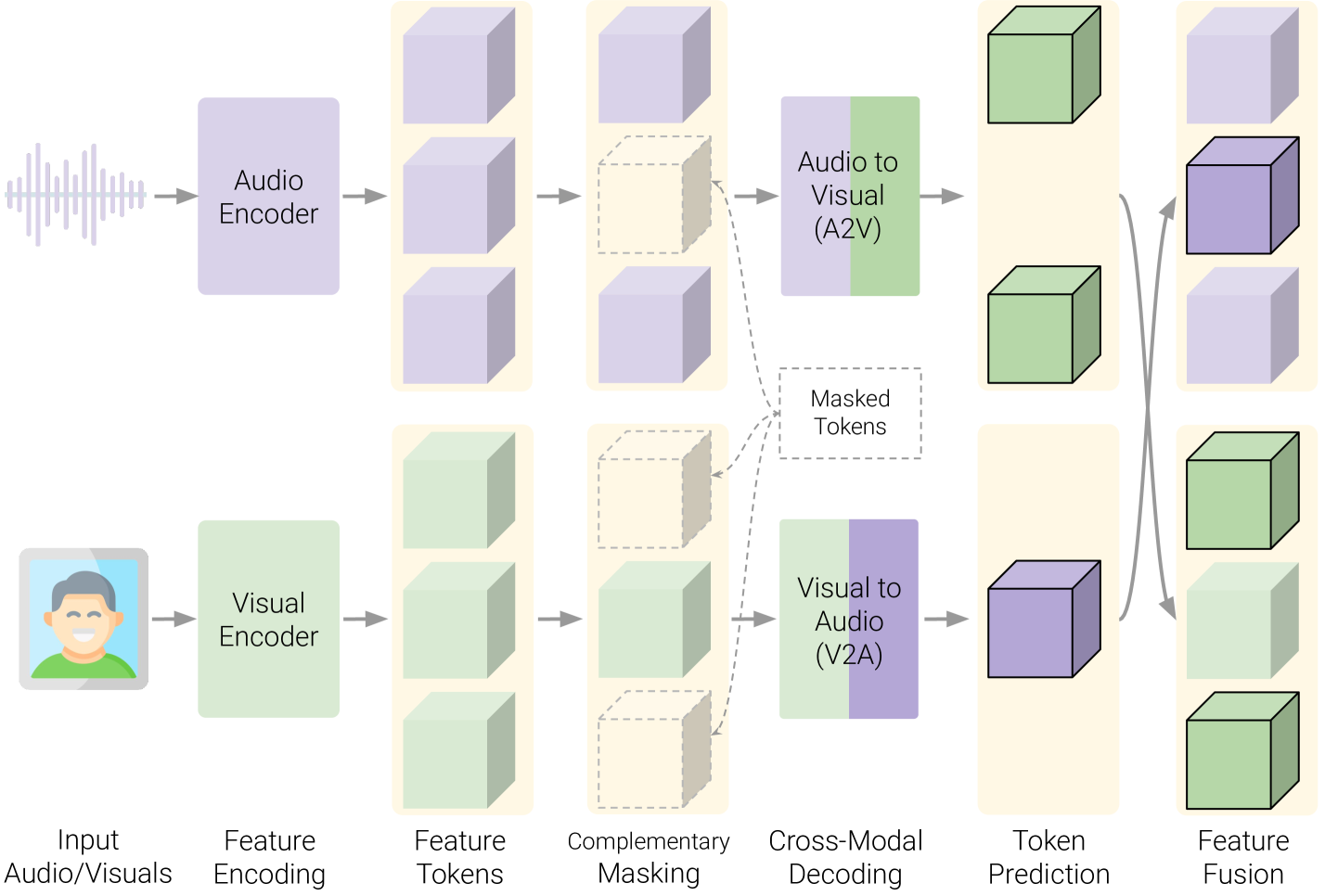
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024
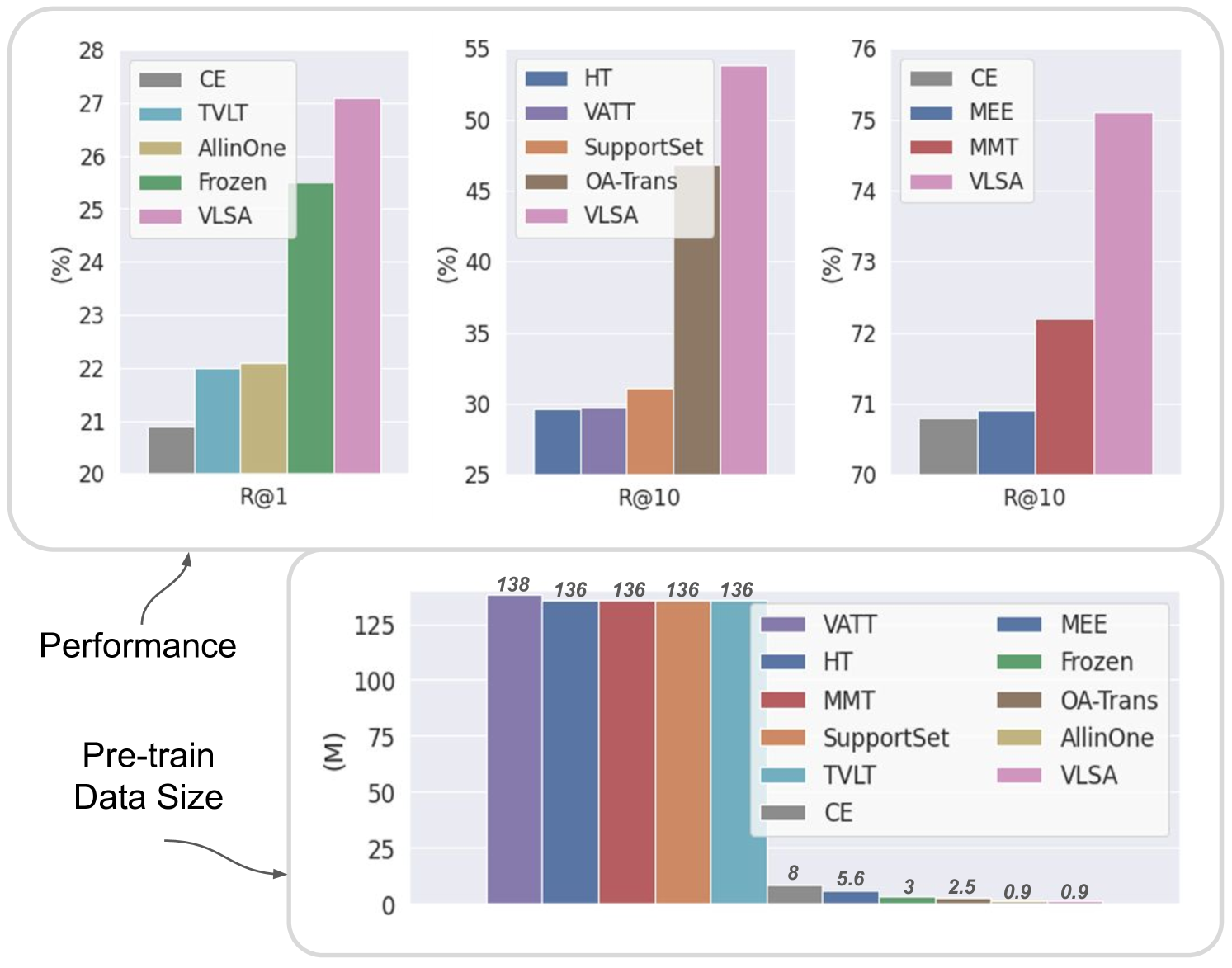
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024

UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Tiantian Geng, Teng Wang, Yanfu Zhang, Jinming Duan, Weili Guan, Feng Zheng
0
0
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
4/5/2024