AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection

0
Sign in to get full access
Overview
- This paper proposes a novel audio-visual feature fusion (AVFF) method for video deepfake detection.
- The approach combines visual and audio features to improve the accuracy of deepfake detection compared to using either modality alone.
- The authors evaluate their method on several benchmark datasets and show it outperforms existing state-of-the-art techniques.
Plain English Explanation
The paper introduces a new way to detect deepfake videos, which are videos that have been manipulated to show someone saying or doing something they didn't actually do. The key idea is to combine information from both the video (the visual aspects) and the audio (the sounds) to get a more accurate detection.
Typically, deepfake detection methods have focused on just the video or just the audio. But the authors argue that by using both the visual and audio cues, you can get better results. Their "audio-visual feature fusion" (AVFF) approach learns to effectively combine these different types of information to spot deepfakes more reliably.
The researchers test their AVFF method on several existing deepfake datasets and show that it outperforms other state-of-the-art techniques. This suggests that their approach of blending visual and audio features is a promising direction for improving deepfake detection capabilities.
Technical Explanation
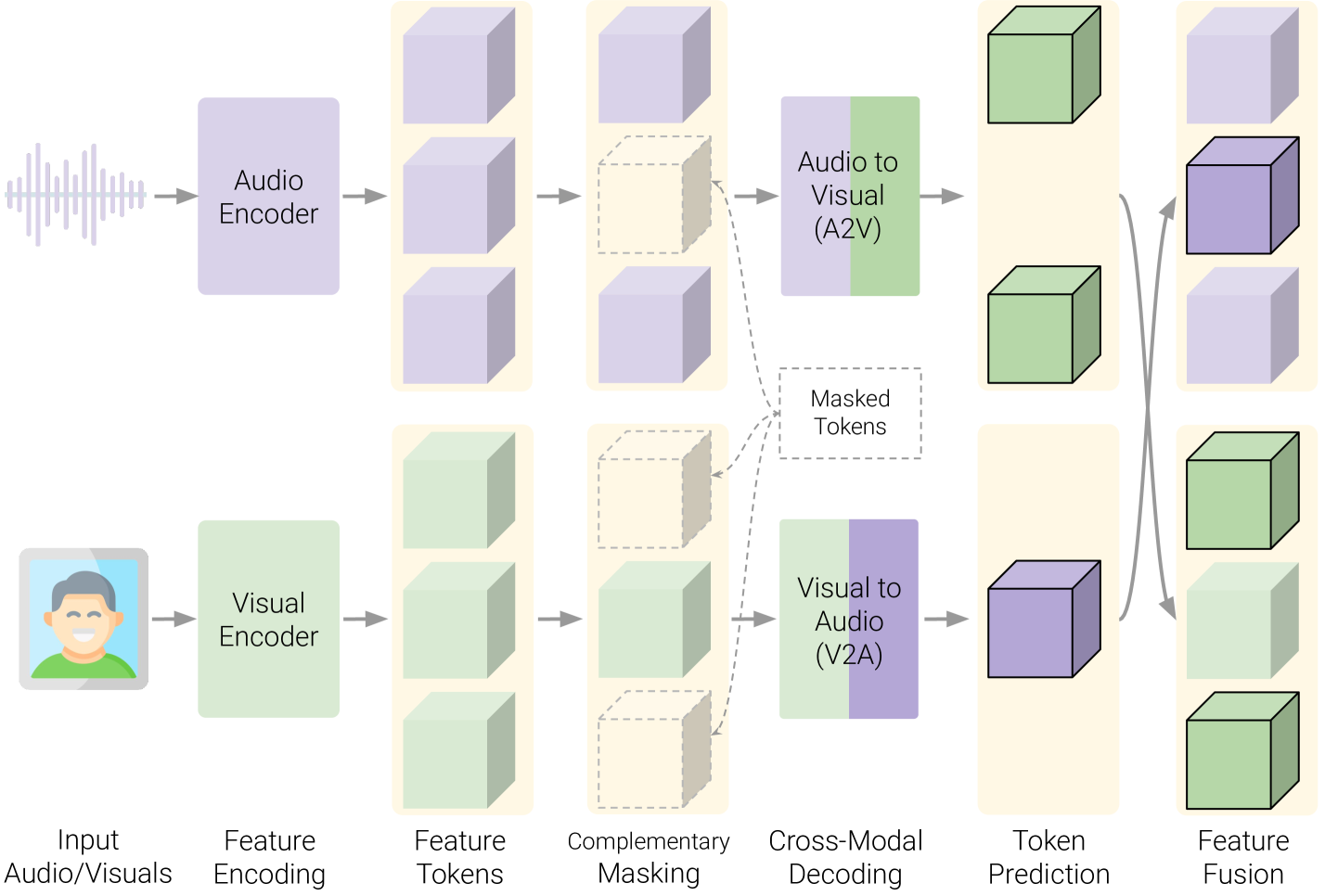
The paper presents an audio-visual feature fusion (AVFF) method for video deepfake detection. The authors argue that using both visual and audio features can boost detection accuracy compared to relying on either modality alone.
Their approach involves first extracting visual features from video frames using a convolutional neural network (CNN) and audio features from the corresponding audio clips using a transformer-based model. These features are then dynamically fused using a cross-attention mechanism that learns to weight the relative importance of the visual and audio cues.
The fused features are passed through additional CNN and transformer layers to produce a final deepfake classification. The authors benchmark their AVFF model on several popular deepfake datasets and show it outperforms prior state-of-the-art methods that use only visual or audio information.
Their multi-layer cross-attention (MLCA) fusion strategy is a key innovation, allowing the model to dynamically emphasize the most relevant features from each modality. This contrastive collaborative learning approach appears effective for deepfake detection.
Critical Analysis
The paper provides a compelling argument for the benefits of using audio-visual fusion for deepfake detection. The authors' experiments demonstrate clear performance gains over unimodal approaches, suggesting the value of their AVFF method.
However, the paper does not deeply explore the limitations or failure cases of their approach. For example, it is unclear how the model would perform on deepfakes with uncoupled audio and video, or on more advanced deepfakes that utilize sophisticated audio synthesis techniques.
Additionally, the paper does not discuss potential biases or fairness issues that could arise from the training data or model architecture. Real-world deepfake detection systems will need to be rigorously tested for these types of concerns.
Further research is also needed to understand the interpretability and explainability of the AVFF model's decisions. Knowing which specific audio and visual cues are most informative for detection could lead to important insights.
Conclusion
This paper presents a novel audio-visual feature fusion (AVFF) method that outperforms prior state-of-the-art techniques for video deepfake detection. By dynamically combining visual and audio information, the approach can more accurately identify manipulated media compared to using either modality alone.
The results suggest that audio-visual fusion is a promising direction for improving deepfake detection capabilities. As deepfake technology becomes more sophisticated, techniques like AVFF will be increasingly important for combating the spread of misinformation and maintaining trust in digital media.
However, further research is needed to fully understand the limitations and potential biases of AVFF-based systems. Ongoing work in this area will be critical for developing robust and responsible deepfake detection solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
Read more6/6/2024
0
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024

0
Statistics-aware Audio-visual Deepfake Detector
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
In this paper, we propose an enhanced audio-visual deep detection method. Recent methods in audio-visual deepfake detection mostly assess the synchronization between audio and visual features. Although they have shown promising results, they are based on the maximization/minimization of isolated feature distances without considering feature statistics. Moreover, they rely on cumbersome deep learning architectures and are heavily dependent on empirically fixed hyperparameters. Herein, to overcome these limitations, we propose: (1) a statistical feature loss to enhance the discrimination capability of the model, instead of relying solely on feature distances; (2) using the waveform for describing the audio as a replacement of frequency-based representations; (3) a post-processing normalization of the fakeness score; (4) the use of shallower network for reducing the computational complexity. Experiments on the DFDC and FakeAVCeleb datasets demonstrate the relevance of the proposed method.
Read more7/18/2024

0
Contextual Cross-Modal Attention for Audio-Visual Deepfake Detection and Localization
Vinaya Sree Katamneni, Ajita Rattani
In the digital age, the emergence of deepfakes and synthetic media presents a significant threat to societal and political integrity. Deepfakes based on multi-modal manipulation, such as audio-visual, are more realistic and pose a greater threat. Current multi-modal deepfake detectors are often based on the attention-based fusion of heterogeneous data streams from multiple modalities. However, the heterogeneous nature of the data (such as audio and visual signals) creates a distributional modality gap and poses a significant challenge in effective fusion and hence multi-modal deepfake detection. In this paper, we propose a novel multi-modal attention framework based on recurrent neural networks (RNNs) that leverages contextual information for audio-visual deepfake detection. The proposed approach applies attention to multi-modal multi-sequence representations and learns the contributing features among them for deepfake detection and localization. Thorough experimental validations on audio-visual deepfake datasets, namely FakeAVCeleb, AV-Deepfake1M, TVIL, and LAV-DF datasets, demonstrate the efficacy of our approach. Cross-comparison with the published studies demonstrates superior performance of our approach with an improved accuracy and precision by 3.47% and 2.05% in deepfake detection and localization, respectively. Thus, obtaining state-of-the-art performance. To facilitate reproducibility, the code and the datasets information is available at https://github.com/vcbsl/audiovisual-deepfake/.
Read more8/9/2024