MAC: A Meta-Learning Approach for Feature Learning and Recombination
2209.09613
0
0
✨
Abstract
Optimization-based meta-learning aims to learn an initialization so that a new unseen task can be learned within a few gradient updates. Model Agnostic Meta-Learning (MAML) is a benchmark algorithm comprising two optimization loops. The inner loop is dedicated to learning a new task and the outer loop leads to meta-initialization. However, ANIL (almost no inner loop) algorithm shows that feature reuse is an alternative to rapid learning in MAML. Thus, the meta-initialization phase makes MAML primed for feature reuse and obviates the need for rapid learning. Contrary to ANIL, we hypothesize that there may be a need to learn new features during meta-testing. A new unseen task from non-similar distribution would necessitate rapid learning in addition reuse and recombination of existing features. In this paper, we invoke the width-depth duality of neural networks, wherein, we increase the width of the network by adding extra computational units (ACU). The ACUs enable the learning of new atomic features in the meta-testing task, and the associated increased width facilitates information propagation in the forwarding pass. The newly learnt features combine with existing features in the last layer for meta-learning. Experimental results show that our proposed MAC method outperformed existing ANIL algorithm for non-similar task distribution by approximately 13% (5-shot task setting)
Create account to get full access
Overview
- This paper introduces a new meta-learning algorithm called MAC (Meta Adaptive Computation) that aims to address the limitations of existing approaches.
- The key idea is to add extra computational units (ACUs) to the neural network, which enable the learning of new features during meta-testing on non-similar tasks.
- This is in contrast to the ANIL algorithm, which focuses on feature reuse and obviates the need for rapid learning.
- The authors hypothesize that for non-similar task distributions, there may be a need to learn new features in addition to reusing and recombining existing ones.
Plain English Explanation
The paper explores a technique called meta-learning, which aims to train a model in a way that it can quickly learn new tasks with just a few updates. One popular meta-learning algorithm is MAML, which has two optimization loops: an inner loop that learns a new task, and an outer loop that updates the initial model parameters.
However, a different algorithm called ANIL showed that simply reusing features can be an effective alternative to rapid learning in MAML. This suggests that the meta-initialization phase in MAML is more about feature reuse than rapid learning.
The authors hypothesize that for tasks that are very different from the ones the model was trained on, there may be a need to learn new features, in addition to reusing and combining existing ones. To enable this, they propose adding extra computational units (ACUs) to the neural network. These ACUs allow the model to learn new atomic features during the meta-testing phase, which can then be combined with the existing features in the final layer for the new task.
The experimental results show that this MAC method outperforms the ANIL algorithm, particularly when dealing with non-similar task distributions, by around 13% in a 5-shot learning setting.
Technical Explanation
The paper introduces the MAC (Meta Adaptive Computation) algorithm, which builds on the insights from the ANIL algorithm. While ANIL showed that feature reuse is an alternative to rapid learning in MAML, the authors hypothesize that for non-similar task distributions, there may be a need to learn new features in addition to reusing and recombining existing ones.
To enable this, the MAC algorithm increases the width of the neural network by adding extra computational units (ACUs). These ACUs allow the model to learn new atomic features during the meta-testing phase, which can then be combined with the existing features in the final layer for the new task.
The authors argue that this approach leverages the width-depth duality of neural networks, where increased width facilitates information propagation in the forward pass and enables the learning of new features.
The experimental results show that the MAC method outperforms the ANIL algorithm by approximately 13% in a 5-shot learning setting when dealing with non-similar task distributions. This suggests that the ability to learn new features, in addition to reusing and recombining existing ones, can be beneficial for meta-learning in certain scenarios.
Critical Analysis
The paper presents a novel approach to meta-learning that aims to address the limitations of existing algorithms like ANIL. The key idea of adding extra computational units (ACUs) to enable the learning of new features during meta-testing is an interesting and potentially valuable contribution.
However, the paper does not provide a deep analysis of the potential limitations or caveats of the MAC method. For example, it would be helpful to understand the computational and memory overhead associated with the increased network width, and how this might impact the practicality of the approach, especially for larger-scale applications.
Additionally, the paper could have explored the trade-offs between feature reuse and rapid learning in more depth, and the scenarios where one approach might be more appropriate than the other.
It would also be valuable to see the MAC method tested on a wider range of non-similar task distributions, to better understand its generalization capabilities and limitations.
Overall, the MAC algorithm presents an interesting and potentially useful approach to meta-learning, but further research and analysis would be needed to fully evaluate its strengths, weaknesses, and practical implications.
Conclusion
This paper introduces the MAC (Meta Adaptive Computation) algorithm, which aims to address the limitations of existing meta-learning approaches like ANIL. The key idea is to add extra computational units (ACUs) to the neural network, enabling the learning of new features during meta-testing on non-similar tasks.
The experimental results show that the MAC method outperforms ANIL by a significant margin when dealing with non-similar task distributions, suggesting that the ability to learn new features can be valuable in certain meta-learning scenarios.
While the MAC algorithm presents an interesting and potentially useful contribution to the field of meta-learning, further research is needed to fully understand its strengths, weaknesses, and practical implications. Exploring the trade-offs between feature reuse and rapid learning, as well as testing the method on a wider range of non-similar task distributions, could provide valuable insights and help refine the approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
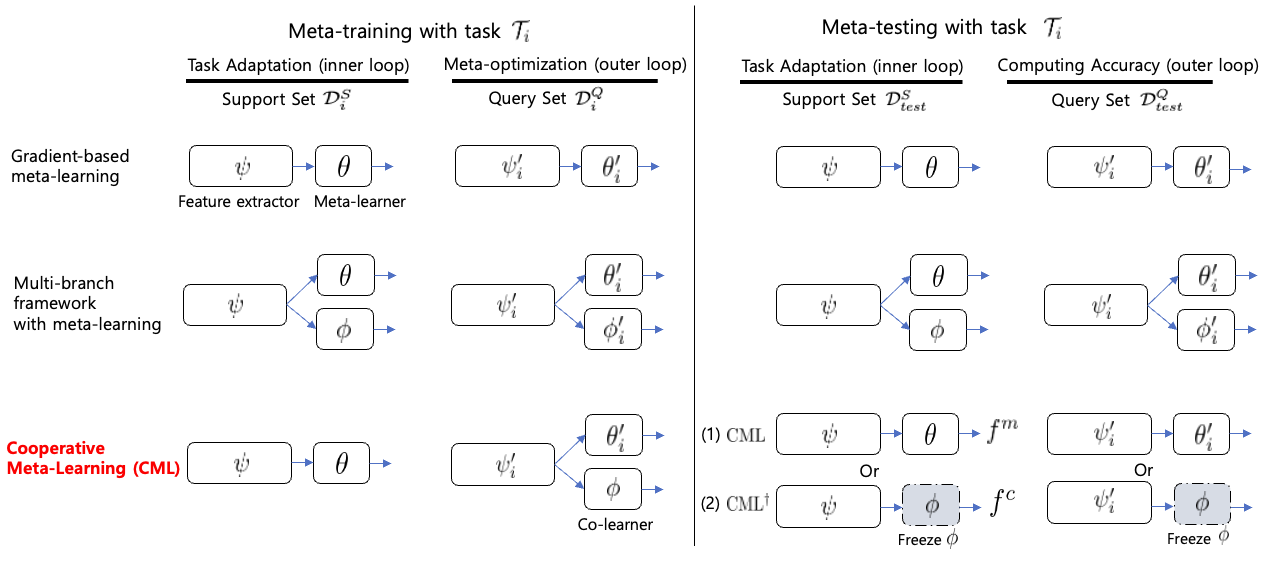
Cooperative Meta-Learning with Gradient Augmentation
Jongyun Shin, Seunjin Han, Jangho Kim
0
0
Model agnostic meta-learning (MAML) is one of the most widely used gradient-based meta-learning, consisting of two optimization loops: an inner loop and outer loop. MAML learns the new task from meta-initialization parameters with an inner update and finds the meta-initialization parameters in the outer loop. In general, the injection of noise into the gradient of the model for augmenting the gradient is one of the widely used regularization methods. In this work, we propose a novel cooperative meta-learning framework dubbed CML which leverages gradient-level regularization with gradient augmentation. We inject learnable noise into the gradient of the model for the model generalization. The key idea of CML is introducing the co-learner which has no inner update but the outer loop update to augment gradients for finding better meta-initialization parameters. Since the co-learner does not update in the inner loop, it can be easily deleted after meta-training. Therefore, CML infers with only meta-learner without additional cost and performance degradation. We demonstrate that CML is easily applicable to gradient-based meta-learning methods and CML leads to increased performance in few-shot regression, few-shot image classification and few-shot node classification tasks. Our codes are at https://github.com/JJongyn/CML.
6/10/2024

MAML-en-LLM: Model Agnostic Meta-Training of LLMs for Improved In-Context Learning
Sanchit Sinha, Yuguang Yue, Victor Soto, Mayank Kulkarni, Jianhua Lu, Aidong Zhang
0
0
Adapting large language models (LLMs) to unseen tasks with in-context training samples without fine-tuning remains an important research problem. To learn a robust LLM that adapts well to unseen tasks, multiple meta-training approaches have been proposed such as MetaICL and MetaICT, which involve meta-training pre-trained LLMs on a wide variety of diverse tasks. These meta-training approaches essentially perform in-context multi-task fine-tuning and evaluate on a disjointed test set of tasks. Even though they achieve impressive performance, their goal is never to compute a truly general set of parameters. In this paper, we propose MAML-en-LLM, a novel method for meta-training LLMs, which can learn truly generalizable parameters that not only perform well on disjointed tasks but also adapts to unseen tasks. We see an average increase of 2% on unseen domains in the performance while a massive 4% improvement on adaptation performance. Furthermore, we demonstrate that MAML-en-LLM outperforms baselines in settings with limited amount of training data on both seen and unseen domains by an average of 2%. Finally, we discuss the effects of type of tasks, optimizers and task complexity, an avenue barely explored in meta-training literature. Exhaustive experiments across 7 task settings along with two data settings demonstrate that models trained with MAML-en-LLM outperform SOTA meta-training approaches.
5/21/2024

Constrained Meta Agnostic Reinforcement Learning
Karam Daaboul, Florian Kuhm, Tim Joseph, J. Marius Zoellner
0
0
Meta-Reinforcement Learning (Meta-RL) aims to acquire meta-knowledge for quick adaptation to diverse tasks. However, applying these policies in real-world environments presents a significant challenge in balancing rapid adaptability with adherence to environmental constraints. Our novel approach, Constraint Model Agnostic Meta Learning (C-MAML), merges meta learning with constrained optimization to address this challenge. C-MAML enables rapid and efficient task adaptation by incorporating task-specific constraints directly into its meta-algorithm framework during the training phase. This fusion results in safer initial parameters for learning new tasks. We demonstrate the effectiveness of C-MAML in simulated locomotion with wheeled robot tasks of varying complexity, highlighting its practicality and robustness in dynamic environments.
6/21/2024
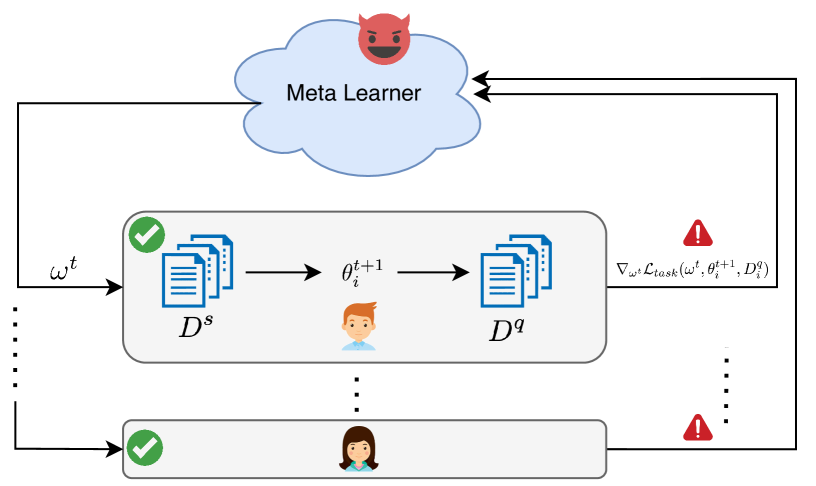
Privacy Challenges in Meta-Learning: An Investigation on Model-Agnostic Meta-Learning
Mina Rafiei, Mohammadmahdi Maheri, Hamid R. Rabiee
0
0
Meta-learning involves multiple learners, each dedicated to specific tasks, collaborating in a data-constrained setting. In current meta-learning methods, task learners locally learn models from sensitive data, termed support sets. These task learners subsequently share model-related information, such as gradients or loss values, which is computed using another part of the data termed query set, with a meta-learner. The meta-learner employs this information to update its meta-knowledge. Despite the absence of explicit data sharing, privacy concerns persist. This paper examines potential data leakage in a prominent metalearning algorithm, specifically Model-Agnostic Meta-Learning (MAML). In MAML, gradients are shared between the metalearner and task-learners. The primary objective is to scrutinize the gradient and the information it encompasses about the task dataset. Subsequently, we endeavor to propose membership inference attacks targeting the task dataset containing support and query sets. Finally, we explore various noise injection methods designed to safeguard the privacy of task data and thwart potential attacks. Experimental results demonstrate the effectiveness of these attacks on MAML and the efficacy of proper noise injection methods in countering them.
6/4/2024