Machine Learning Data Practices through a Data Curation Lens: An Evaluation Framework
2405.02703
0
0

Abstract
Studies of dataset development in machine learning call for greater attention to the data practices that make model development possible and shape its outcomes. Many argue that the adoption of theory and practices from archives and data curation fields can support greater fairness, accountability, transparency, and more ethical machine learning. In response, this paper examines data practices in machine learning dataset development through the lens of data curation. We evaluate data practices in machine learning as data curation practices. To do so, we develop a framework for evaluating machine learning datasets using data curation concepts and principles through a rubric. Through a mixed-methods analysis of evaluation results for 25 ML datasets, we study the feasibility of data curation principles to be adopted for machine learning data work in practice and explore how data curation is currently performed. We find that researchers in machine learning, which often emphasizes model development, struggle to apply standard data curation principles. Our findings illustrate difficulties at the intersection of these fields, such as evaluating dimensions that have shared terms in both fields but non-shared meanings, a high degree of interpretative flexibility in adapting concepts without prescriptive restrictions, obstacles in limiting the depth of data curation expertise needed to apply the rubric, and challenges in scoping the extent of documentation dataset creators are responsible for. We propose ways to address these challenges and develop an overall framework for evaluation that outlines how data curation concepts and methods can inform machine learning data practices.
Create account to get full access
Overview
- This paper proposes an evaluation framework for assessing machine learning data practices through the lens of data curation.
- The framework covers key aspects of dataset creation, documentation, and transparency to help improve the quality and ethical use of machine learning data.
- The authors argue that adopting data curation best practices can lead to more robust, inclusive, and trustworthy machine learning systems.
Plain English Explanation
The paper focuses on how machine learning researchers and practitioners collect, document, and share the data they use to train their models. The authors believe that the field of "data curation" - the careful management and documentation of datasets - can provide a helpful framework for evaluating these data practices.
<a href="https://aimodels.fyi/papers/arxiv/ai-competitions-benchmarks-dataset-development">Machine learning competitions</a> and benchmark datasets have driven rapid progress in AI, but have also highlighted issues around the <a href="https://aimodels.fyi/papers/arxiv/scaling-laws-data-filtering-data-curation-cannot">quality, representativeness, and ethical implications</a> of the data used. The authors argue that more transparent and rigorous data practices, inspired by data curation principles, can help address these concerns.
Their evaluation framework covers things like how the data was collected, how it was cleaned and filtered, what biases or limitations it may have, and how well it is documented for other researchers to understand and use. The goal is to encourage <a href="https://aimodels.fyi/papers/arxiv/understanding-dataset-practitioners-behind-large-language-model">more thoughtful and responsible data practices</a> by the teams building machine learning systems.
By adopting data curation best practices, the authors believe the machine learning community can work towards developing <a href="https://aimodels.fyi/papers/arxiv/lazy-data-practices-harm-fairness-research">more robust, inclusive, and trustworthy AI systems</a> that better serve the public interest. The framework they propose can help systematically evaluate datasets and surface important considerations that are often overlooked.
Technical Explanation
The core of the paper is a proposed "Data Curation Evaluation Framework" for assessing machine learning data practices. This framework covers six key areas:
- Dataset Description: Details on the dataset's purpose, content, and source.
- Data Collection: How the data was gathered, filtered, and curated.
- Data Documentation: The quality and comprehensiveness of metadata and other documentation.
- Data Diversity: The demographic, geographic, and other forms of diversity represented in the data.
- Data Quality: Measures of data integrity, consistency, and suitability for the intended use.
- Data Ethics: Consideration of potential harms, biases, and other ethical implications of the data.
For each area, the framework provides a set of questions and evaluation criteria to systematically assess the dataset. The authors argue that rigorously applying this framework can help identify shortcomings in data practices and encourage more <a href="https://aimodels.fyi/papers/arxiv/dataversifying-natural-sciences-pioneering-data-lake-architecture">responsible, transparent, and inclusive data curation</a>.
The proposed framework is applied to three real-world machine learning datasets to demonstrate its utility. The authors found that the framework was able to surface important limitations and ethical concerns that were not always evident from the standard dataset documentation.
Critical Analysis
The authors make a compelling case that data curation principles can greatly improve the quality and ethical use of machine learning data. Their framework provides a comprehensive and structured way to evaluate key aspects of dataset creation and documentation.
However, the framework does require a significant investment of time and expertise to apply thoroughly. There may be challenges in getting busy machine learning researchers and engineers to adopt such a detailed evaluation process, especially for quickly iterating on models and datasets.
Additionally, the framework focuses on individual dataset-level considerations, but does not address broader systemic issues in the machine learning ecosystem, such as the <a href="https://aimodels.fyi/papers/arxiv/lazy-data-practices-harm-fairness-research">uneven distribution of resources and power</a> that can lead to biased and exclusionary data practices. Addressing these deeper structural problems may require complementary approaches beyond just better dataset documentation.
Overall, the authors present a valuable tool that can help make machine learning data practices more rigorous, transparent, and accountable. But its widespread adoption may depend on finding ways to make the evaluation process more streamlined and integrated into standard machine learning workflows.
Conclusion
This paper argues that applying data curation principles can significantly improve the quality and ethical use of machine learning data. The authors propose a comprehensive evaluation framework covering key aspects of dataset creation, documentation, and diversity.
By systematically assessing datasets through this lens, the machine learning community can work towards developing more robust, inclusive, and trustworthy AI systems that better serve the public interest. While implementing the framework poses some practical challenges, it represents an important step towards more responsible and transparent data practices in the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Taxonomy of Challenges to Curating Fair Datasets
Dora Zhao, Morgan Klaus Scheuerman, Pooja Chitre, Jerone T. A. Andrews, Georgia Panagiotidou, Shawn Walker, Kathleen H. Pine, Alice Xiang
0
0
Despite extensive efforts to create fairer machine learning (ML) datasets, there remains a limited understanding of the practical aspects of dataset curation. Drawing from interviews with 30 ML dataset curators, we present a comprehensive taxonomy of the challenges and trade-offs encountered throughout the dataset curation lifecycle. Our findings underscore overarching issues within the broader fairness landscape that impact data curation. We conclude with recommendations aimed at fostering systemic changes to better facilitate fair dataset curation practices.
6/11/2024

AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
0
0
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
4/16/2024
Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic
Sachin Goyal, Pratyush Maini, Zachary C. Lipton, Aditi Raghunathan, J. Zico Kolter
0
0
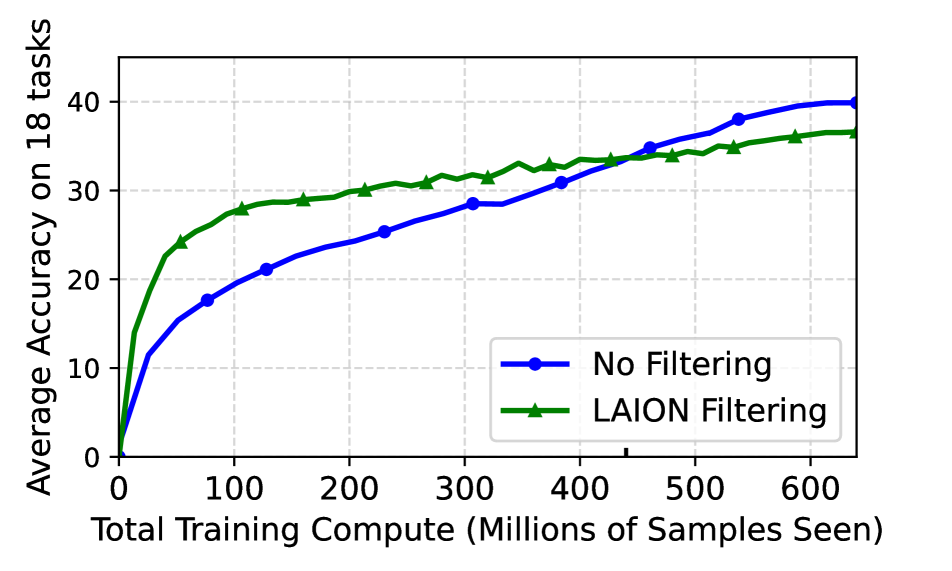
Vision-language models (VLMs) are trained for thousands of GPU hours on carefully curated web datasets. In recent times, data curation has gained prominence with several works developing strategies to retain 'high-quality' subsets of 'raw' scraped data. For instance, the LAION public dataset retained only 10% of the total crawled data. However, these strategies are typically developed agnostic of the available compute for training. In this paper, we first demonstrate that making filtering decisions independent of training compute is often suboptimal: the limited high-quality data rapidly loses its utility when repeated, eventually requiring the inclusion of 'unseen' but 'lower-quality' data. To address this quality-quantity tradeoff ($texttt{QQT}$), we introduce neural scaling laws that account for the non-homogeneous nature of web data, an angle ignored in existing literature. Our scaling laws (i) characterize the $textit{differing}$ 'utility' of various quality subsets of web data; (ii) account for how utility diminishes for a data point at its 'nth' repetition; and (iii) formulate the mutual interaction of various data pools when combined, enabling the estimation of model performance on a combination of multiple data pools without ever jointly training on them. Our key message is that data curation $textit{cannot}$ be agnostic of the total compute that a model will be trained for. Our scaling laws allow us to curate the best possible pool for achieving top performance on Datacomp at various compute budgets, carving out a pareto-frontier for data curation. Code is available at https://github.com/locuslab/scaling_laws_data_filtering.
4/11/2024
Understanding the Dataset Practitioners Behind Large Language Model Development
Crystal Qian, Emily Reif, Minsuk Kahng
0
0
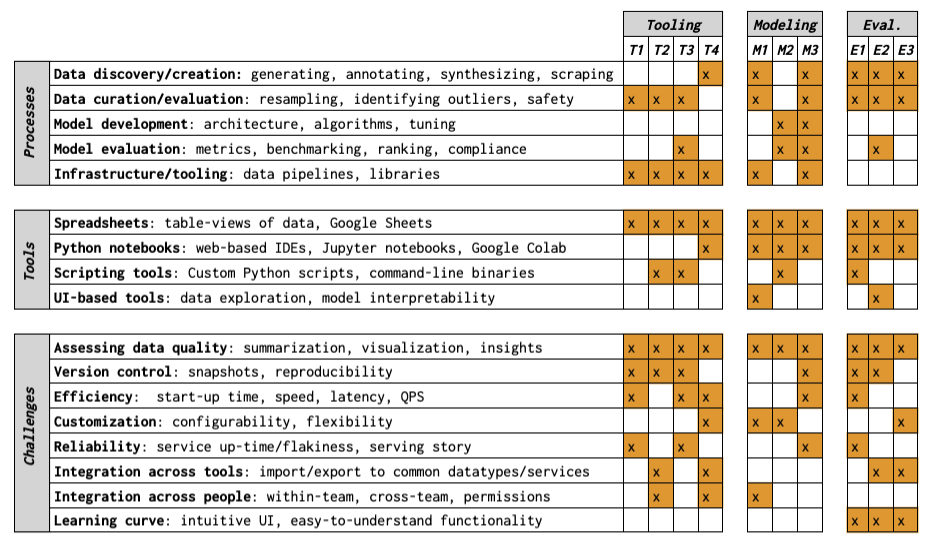
As large language models (LLMs) become more advanced and impactful, it is increasingly important to scrutinize the data that they rely upon and produce. What is it to be a dataset practitioner doing this work? We approach this in two parts: first, we define the role of dataset practitioners by performing a retrospective analysis on the responsibilities of teams contributing to LLM development at a technology company, Google. Then, we conduct semi-structured interviews with a cross-section of these practitioners (N=10). We find that although data quality is a top priority, there is little consensus around what data quality is and how to evaluate it. Consequently, practitioners either rely on their own intuition or write custom code to evaluate their data. We discuss potential reasons for this phenomenon and opportunities for alignment.
4/3/2024