Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic
2404.07177
1
0
Abstract
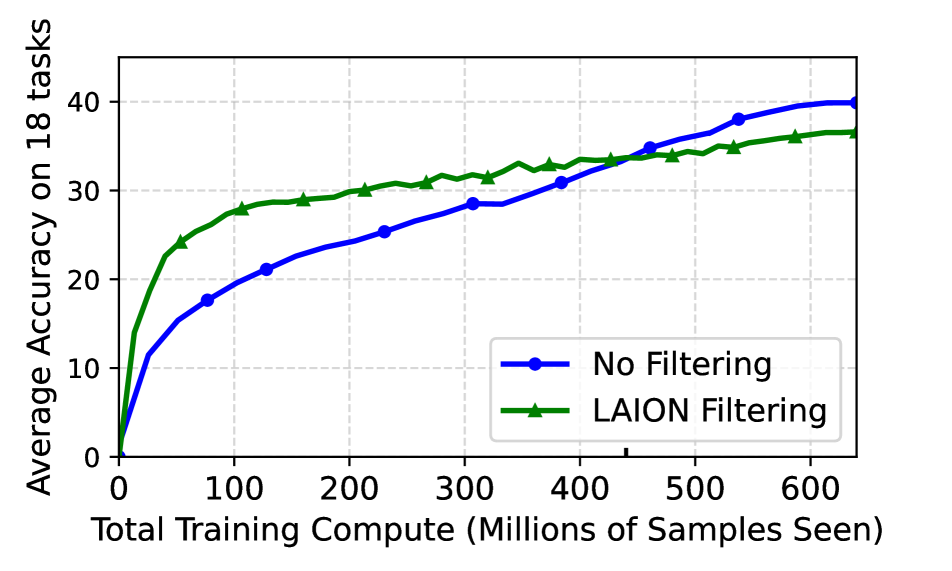
Vision-language models (VLMs) are trained for thousands of GPU hours on carefully curated web datasets. In recent times, data curation has gained prominence with several works developing strategies to retain 'high-quality' subsets of 'raw' scraped data. For instance, the LAION public dataset retained only 10% of the total crawled data. However, these strategies are typically developed agnostic of the available compute for training. In this paper, we first demonstrate that making filtering decisions independent of training compute is often suboptimal: the limited high-quality data rapidly loses its utility when repeated, eventually requiring the inclusion of 'unseen' but 'lower-quality' data. To address this quality-quantity tradeoff ($texttt{QQT}$), we introduce neural scaling laws that account for the non-homogeneous nature of web data, an angle ignored in existing literature. Our scaling laws (i) characterize the $textit{differing}$ 'utility' of various quality subsets of web data; (ii) account for how utility diminishes for a data point at its 'nth' repetition; and (iii) formulate the mutual interaction of various data pools when combined, enabling the estimation of model performance on a combination of multiple data pools without ever jointly training on them. Our key message is that data curation $textit{cannot}$ be agnostic of the total compute that a model will be trained for. Our scaling laws allow us to curate the best possible pool for achieving top performance on Datacomp at various compute budgets, carving out a pareto-frontier for data curation. Code is available at https://github.com/locuslab/scaling_laws_data_filtering.
Create account to get full access
Overview
- This paper explores how the computational resources required for data filtering tasks scale with the size and complexity of the data.
- The key finding is that data curation cannot be "compute agnostic" - the optimal approaches for filtering data depend on the available computational power.
- The authors propose a framework for analyzing the scaling behavior of data filtering algorithms and validate it through experiments on real-world datasets.
Plain English Explanation
When working with large, complex datasets, the process of "filtering" the data - removing irrelevant or low-quality information - is a crucial step. However, the authors of this paper argue that the best way to filter data depends on the computational resources available.
Unraveling the Mystery of Scaling Laws: Part I and Scaling Laws for Galaxy Images have previously explored scaling laws in machine learning, but this paper focuses specifically on the scaling of data filtering algorithms.
The key insight is that data curation, the process of preparing and cleaning data, cannot be done in a "compute agnostic" way. The optimal approach to filtering data will depend on factors like the size of the dataset, the complexity of the data, and the amount of computational power available.
The authors propose a framework for analyzing how the computational cost of data filtering scales with these factors. They validate this framework through experiments on real-world datasets, showing how the most effective data filtering strategy can change depending on the available computing resources.
Technical Explanation
The paper presents a framework for analyzing the scaling behavior of data filtering algorithms. The authors consider two main factors that impact the computational cost of data filtering:
-
Dataset Size: As the amount of data increases, the computational cost of filtering the data also grows. The authors analyze how this scaling behavior varies for different filtering algorithms.
-
Data Complexity: More complex data, such as high-dimensional or structured data, requires more computational effort to filter effectively. The authors explore how the scaling of filtering cost is affected by the complexity of the input data.
Through theoretical analysis and empirical validation on real-world datasets, the paper demonstrates that the optimal data filtering strategy depends on the available computational resources. Algorithms that are effective for small-scale data may become prohibitively expensive as the dataset size or complexity increases.
Scalability of Diffusion-based Text-to-Image Generation and Quantifying and Mitigating Unimodal Biases in Multimodal Large Language Models have discussed the importance of understanding scaling behavior in machine learning systems. This paper extends this line of research to the specific domain of data filtering, showing that data curation cannot be done in a "compute agnostic" way.
Critical Analysis
The paper provides a well-designed framework for analyzing the scaling behavior of data filtering algorithms and validates it through extensive experiments. However, some potential limitations and areas for further research are worth noting:
-
Generalization to Other Data Domains: The experiments in the paper focused on specific types of data, such as images and text. It would be valuable to explore how the proposed framework applies to other data domains, such as video, audio, or structured tabular data.
-
Practical Implications: While the theoretical framework is sound, the paper does not provide concrete guidance on how practitioners should choose the most appropriate data filtering algorithm for their specific computational constraints and dataset characteristics. Further research could explore decision-making tools or heuristics to help practitioners navigate this trade-off.
-
Interaction with Other Machine Learning Components: Data filtering is often just one step in a larger machine learning pipeline. Scaling Up Video Summarization with Pretraining on Large Language Models has discussed the importance of considering the entire system. Future research could investigate how the scaling behavior of data filtering interacts with other components, such as model training or inference.
Overall, this paper makes an important contribution by highlighting the need to consider computational constraints when designing data filtering strategies, rather than treating data curation as a "one-size-fits-all" problem. The insights provided can help guide the development of more efficient and effective machine learning systems.
Conclusion
This paper presents a framework for analyzing the scaling behavior of data filtering algorithms, demonstrating that the optimal approaches for data curation depend on the available computational resources. The key finding is that data filtering cannot be done in a "compute agnostic" way - the best strategy for filtering data will vary based on factors like dataset size and data complexity.
The proposed framework and experimental validation provide valuable insights for the design of machine learning systems, particularly as datasets continue to grow in size and complexity. By understanding the scaling behavior of data filtering algorithms, researchers and practitioners can make more informed choices about how to prepare and curate data for their specific computational constraints and application needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Dark Side of Dataset Scaling: Evaluating Racial Classification in Multimodal Models
Abeba Birhane, Sepehr Dehdashtian, Vinay Uday Prabhu, Vishnu Boddeti
0
0
Scale the model, scale the data, scale the GPU farms is the reigning sentiment in the world of generative AI today. While model scaling has been extensively studied, data scaling and its downstream impacts on model performance remain under-explored. This is particularly important in the context of multimodal datasets whose main source is the World Wide Web, condensed and packaged as the Common Crawl dump, which is known to exhibit numerous drawbacks. In this paper, we evaluate the downstream impact of dataset scaling on 14 visio-linguistic models (VLMs) trained on the LAION400-M and LAION-2B datasets by measuring racial and gender bias using the Chicago Face Dataset (CFD) as the probe. Our results show that as the training data increased, the probability of a pre-trained CLIP model misclassifying human images as offensive non-human classes such as chimpanzee, gorilla, and orangutan decreased, but misclassifying the same images as human offensive classes such as criminal increased. Furthermore, of the 14 Vision Transformer-based VLMs we evaluated, the probability of predicting an image of a Black man and a Latino man as criminal increases by 65% and 69%, respectively, when the dataset is scaled from 400M to 2B samples for the larger ViT-L models. Conversely, for the smaller base ViT-B models, the probability of predicting an image of a Black man and a Latino man as criminal decreases by 20% and 47%, respectively, when the dataset is scaled from 400M to 2B samples. We ground the model audit results in a qualitative and historical analysis, reflect on our findings and their implications for dataset curation practice, and close with a summary of mitigation mechanisms and ways forward. Content warning: This article contains racially dehumanising and offensive descriptions.
5/9/2024
📈
Navigating Scaling Laws: Compute Optimality in Adaptive Model Training
Sotiris Anagnostidis, Gregor Bachmann, Imanol Schlag, Thomas Hofmann
0
0
In recent years, the state-of-the-art in deep learning has been dominated by very large models that have been pre-trained on vast amounts of data. The paradigm is very simple: investing more computational resources (optimally) leads to better performance, and even predictably so; neural scaling laws have been derived that accurately forecast the performance of a network for a desired level of compute. This leads to the notion of a `compute-optimal' model, i.e. a model that allocates a given level of compute during training optimally to maximize performance. In this work, we extend the concept of optimality by allowing for an `adaptive' model, i.e. a model that can change its shape during training. By doing so, we can design adaptive models that optimally traverse between the underlying scaling laws and outpace their `static' counterparts, leading to a significant reduction in the required compute to reach a given target performance. We show that our approach generalizes across modalities and different shape parameters.
5/24/2024
💬
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, Yitao Liang
0
0
The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with Scaling Law. Unlike pre-training, we find that the fine-tuning scaling curve includes not just the well-known power phase but also the previously unobserved pre-power phase. We also explain why existing Scaling Law fails to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of pre-learned data size into our Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection. The project page is available at rectified-scaling-law.github.io.
5/29/2024
✅
More Compute Is What You Need
Zhen Guo
0
0
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
5/3/2024