BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
2404.02827
0
0

Abstract
This work presents BAdam, an optimization method that leverages the block coordinate descent framework with Adam as the inner solver. BAdam offers a memory efficient approach to the full parameter finetuning of large language models. We conduct theoretical convergence analysis for BAdam in the deterministic case. Experimentally, we apply BAdam to instruction-tune the Llama 2-7B and Llama 3-8B models using a single RTX3090-24GB GPU. The results confirm BAdam's efficiency in terms of memory and running time. Additionally, the convergence verification indicates that BAdam exhibits superior convergence behavior compared to LoRA. Furthermore, the downstream performance evaluation using the MT-bench shows that BAdam modestly surpasses LoRA and more substantially outperforms LOMO. Finally, we compare BAdam with Adam on a medium-sized task, i.e., finetuning RoBERTa-large on the SuperGLUE benchmark. The results demonstrate that BAdam is capable of narrowing the performance gap with Adam more effectively than LoRA. Our code is available at https://github.com/Ledzy/BAdam.
Create account to get full access
Overview
- Introduces a new memory-efficient training method called BAdam for large language models
- Aims to reduce the memory footprint during training without compromising model performance
- Leverages a Bayesian approach to adaptively update model parameters, leading to more efficient use of memory
Plain English Explanation
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models is a research paper that presents a new training method for large language models. The key idea is to develop a more memory-efficient way to train these models, which can be computationally expensive and memory-intensive.
The proposed method, called BAdam, uses a Bayesian approach to adaptively update the model parameters during training. This allows the model to use memory more efficiently, as it doesn't need to store as much information about the parameter updates. The researchers show that BAdam can achieve similar performance to traditional training methods while using significantly less memory.
This is important because large language models, which are trained on vast amounts of text data, can require a lot of computational resources and memory. By making the training process more memory-efficient, the BAdam method could help enable the development of even larger and more powerful language models, which could have a range of applications in natural language processing and generation.
Technical Explanation
The BAdam method is based on the popular Adam optimizer, a widely used algorithm for training deep learning models. However, the BAdam method introduces several key modifications to make the training process more memory-efficient.
First, instead of storing the full history of past gradients and parameter updates, BAdam only stores a single scalar value for each parameter. This scalar value is updated in a Bayesian manner, using a closed-form update rule that takes into account the current gradient and the previous scalar value.
Second, BAdam uses a separate learning rate for each parameter, which is also updated in a Bayesian way. This allows the model to adapt the learning rate for each parameter based on the observed gradients, leading to more efficient use of memory and potentially better generalization.
The researchers evaluate the BAdam method on several large language model benchmarks, including LLAVA-GeMMA, and show that it can achieve similar performance to traditional training methods while using significantly less memory. They also demonstrate that the BAdam method is applicable to a wide range of deep learning models, not just large language models.
Critical Analysis
The paper provides a thorough technical explanation of the BAdam method and its advantages, but there are a few areas that could be explored further:
-
Comparison to Other Memory-Efficient Approaches: While the paper compares BAdam to traditional training methods, it would be interesting to see how it performs relative to other memory-efficient techniques, such as gradient checkpointing or network pruning.
-
Generalization to Diverse Model Architectures: The authors demonstrate the effectiveness of BAdam on large language models, but it's unclear how well the method would generalize to other types of deep learning models with different architectural characteristics.
-
Potential Drawbacks or Limitations: The paper does not discuss any potential downsides or limitations of the BAdam method, such as possible impacts on training stability or convergence speed. A more balanced critique would help readers better understand the trade-offs involved.
Overall, the BAdam method presents an interesting and promising approach to improving the memory efficiency of large language model training. Further research and real-world applications could help validate its broader applicability and potential impact on the field of deep learning.
Conclusion
The BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models paper introduces a novel training method that aims to reduce the memory footprint of large language model training without compromising model performance. By using a Bayesian approach to adaptively update model parameters, the BAdam method can achieve similar results to traditional training techniques while using significantly less memory.
This research has the potential to enable the development of even larger and more powerful language models, which could lead to advancements in a wide range of natural language processing and generation tasks. While the paper provides a solid technical foundation, further exploration of the method's limitations and generalization to other model architectures could help solidify its impact and inform future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AdaLomo: Low-memory Optimization with Adaptive Learning Rate
Kai Lv, Hang Yan, Qipeng Guo, Haijun Lv, Xipeng Qiu
0
0
Large language models have achieved remarkable success, but their extensive parameter size necessitates substantial memory for training, thereby setting a high threshold. While the recently proposed low-memory optimization (LOMO) reduces memory footprint, its optimization technique, akin to stochastic gradient descent, is sensitive to hyper-parameters and exhibits suboptimal convergence, failing to match the performance of the prevailing optimizer for large language models, AdamW. Through empirical analysis of the Adam optimizer, we found that, compared to momentum, the adaptive learning rate is more critical for bridging the gap. Building on this insight, we introduce the low-memory optimization with adaptive learning rate (AdaLomo), which offers an adaptive learning rate for each parameter. To maintain memory efficiency, we employ non-negative matrix factorization for the second-order moment estimation in the optimizer state. Additionally, we suggest the use of a grouped update normalization to stabilize convergence. Our experiments with instruction-tuning and further pre-training demonstrate that AdaLomo achieves results on par with AdamW, while significantly reducing memory requirements, thereby lowering the hardware barrier to training large language models. The code is accessible at https://github.com/OpenLMLab/LOMO.
6/7/2024
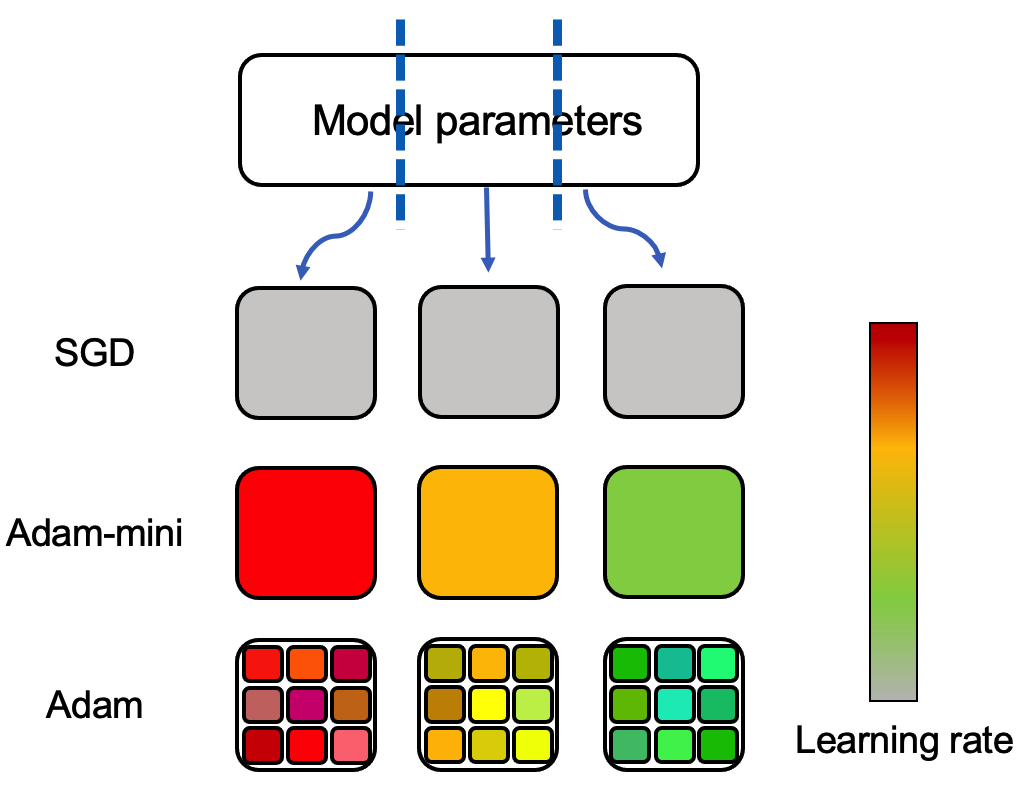
Adam-mini: Use Fewer Learning Rates To Gain More
Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Yinyu Ye, Zhi-Quan Luo, Ruoyu Sun
0
0
We propose Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in Adam (i.e., $1/sqrt{v}$). We find that $geq$ 90% of these learning rates in $v$ could be harmlessly removed if we (1) carefully partition the parameters into blocks following our proposed principle on Hessian structure; (2) assign a single but good learning rate to each parameter block. We further find that, for each of these parameter blocks, there exists a single high-quality learning rate that can outperform Adam, provided that sufficient resources are available to search it out. We then provide one cost-effective way to find good learning rates and propose Adam-mini. Empirically, we verify that Adam-mini performs on par or better than AdamW on various language models sized from 125M to 7B for pre-training, supervised fine-tuning, and RLHF. The reduced memory footprint of Adam-mini also alleviates communication overheads among GPUs and CPUs, thereby increasing throughput. For instance, Adam-mini achieves 49.6% higher throughput than AdamW when pre-training Llama2-7B on $2times$ A800-80GB GPUs, which saves 33% wall-clock time for pre-training.
6/27/2024

Full Parameter Fine-tuning for Large Language Models with Limited Resources
Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, Xipeng Qiu
0
0
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the threshold for LLMs training would encourage greater participation from researchers, benefiting both academia and society. While existing approaches have focused on parameter-efficient fine-tuning, which tunes or adds a small number of parameters, few have addressed the challenge of tuning the full parameters of LLMs with limited resources. In this work, we propose a new optimizer, LOw-Memory Optimization (LOMO), which fuses the gradient computation and the parameter update in one step to reduce memory usage. By integrating LOMO with existing memory saving techniques, we reduce memory usage to 10.8% compared to the standard approach (DeepSpeed solution). Consequently, our approach enables the full parameter fine-tuning of a 65B model on a single machine with 8 RTX 3090, each with 24GB memory.Code and data are available at https://github.com/OpenLMLab/LOMO.
6/7/2024
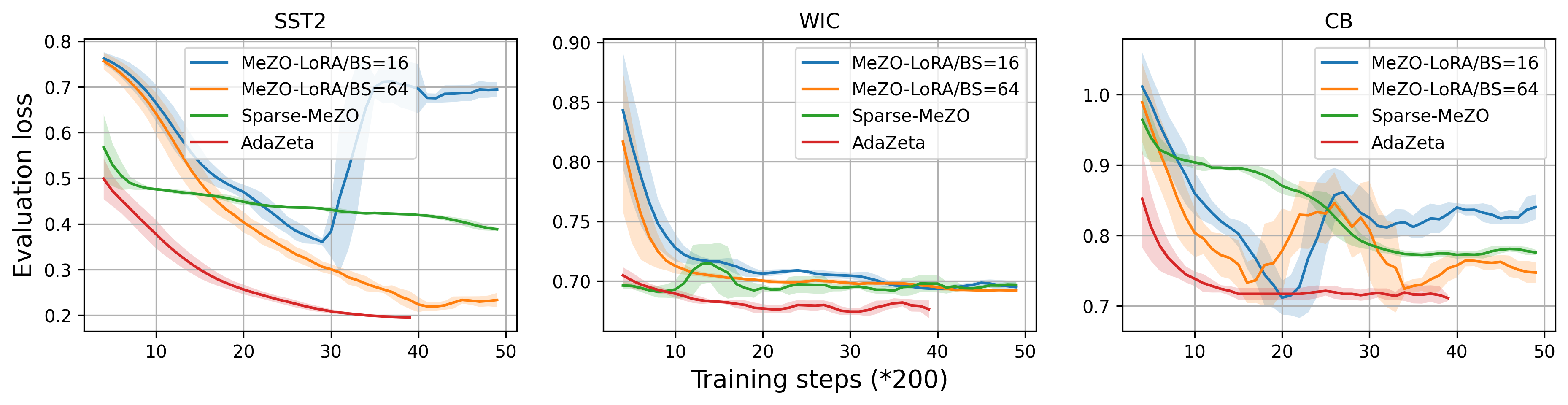
AdaZeta: Adaptive Zeroth-Order Tensor-Train Adaption for Memory-Efficient Large Language Models Fine-Tuning
Yifan Yang, Kai Zhen, Ershad Banijamal, Athanasios Mouchtaris, Zheng Zhang
0
0
Fine-tuning large language models (LLMs) has achieved remarkable performance across various natural language processing tasks, yet it demands more and more memory as model sizes keep growing. To address this issue, the recently proposed Memory-efficient Zeroth-order (MeZO) methods attempt to fine-tune LLMs using only forward passes, thereby avoiding the need for a backpropagation graph. However, significant performance drops and a high risk of divergence have limited their widespread adoption. In this paper, we propose the Adaptive Zeroth-order Tensor-Train Adaption (AdaZeta) framework, specifically designed to improve the performance and convergence of the ZO methods. To enhance dimension-dependent ZO estimation accuracy, we introduce a fast-forward, low-parameter tensorized adapter. To tackle the frequently observed divergence issue in large-scale ZO fine-tuning tasks, we propose an adaptive query number schedule that guarantees convergence. Detailed theoretical analysis and extensive experimental results on Roberta-Large and Llama-2-7B models substantiate the efficacy of our AdaZeta framework in terms of accuracy, memory efficiency, and convergence speed.
6/27/2024