Maintaining Adversarial Robustness in Continuous Learning

0

Sign in to get full access
Overview
- This paper presents a method for maintaining adversarial robustness in continuous learning scenarios.
- Continuous learning refers to the ability of machine learning models to learn and adapt over time as new data becomes available.
- The key challenge is ensuring the model remains robust to adversarial attacks as it continues to learn.
Plain English Explanation
The paper tackles the problem of maintaining adversarial robustness in continuous learning systems. Continuous learning allows AI models to keep updating and improving themselves over time as new data becomes available, rather than being locked into a fixed set of knowledge.
However, this ongoing learning process also makes the model more vulnerable to adversarial attacks - deliberate attempts to trick the model into making mistakes. The researchers present a method to help the model stay robust and resistant to these attacks even as it continues learning.
The key idea is to apply a sample gradient regularization technique. This encourages the model to learn in a way that maintains its sensitivity to small changes in the input data, making it harder for attackers to find vulnerabilities. The researchers show this approach can effectively preserve the model's adversarial robustness over time.
Technical Explanation
The paper introduces a method called Sample Gradient Regularization (SGR) to address the challenge of maintaining adversarial robustness in continuous learning scenarios. The core idea is to add a regularization term to the model's loss function that encourages the gradients of the model's outputs with respect to the inputs to remain small.
Specifically, the SGR term penalizes large gradients of the model's logits (the raw, pre-softmax outputs) with respect to the input samples. This encourages the model to learn a Lipschitz continuous function, where small changes in the input result in correspondingly small changes in the output.
This property helps preserve the model's adversarial robustness as it continues to learn, making it more resistant to adversarial attacks that rely on finding subtle perturbations of the input that dramatically change the model's predictions.
The researchers evaluate their approach on several benchmark continuous learning datasets and show that SGR can effectively maintain the model's adversarial robustness over time, outperforming previous methods.
Critical Analysis
The paper presents a compelling approach to a important challenge in continuous learning systems. By encouraging the model to learn a Lipschitz continuous function, the SGR method helps preserve the model's sensitivity to small input changes, a key property for adversarial robustness.
That said, the paper does not explore some potential limitations or extensions of the work. For example, it would be interesting to see how the SGR method performs on more complex, high-dimensional datasets or in the presence of more sophisticated adversarial attacks. Additionally, the paper does not discuss the computational overhead or training time implications of the SGR regularization term.
Further research could also explore ways to dynamically adjust the SGR regularization strength over the course of training, or to combine it with other techniques for maintaining model robustness in continuous learning settings.
Conclusion
This paper presents a novel method called Sample Gradient Regularization (SGR) to help maintain adversarial robustness in continuous learning systems. By encouraging the model to learn a Lipschitz continuous function, SGR can effectively preserve the model's sensitivity to small input changes, making it more resistant to adversarial attacks as it continues to learn.
The empirical results demonstrate the effectiveness of this approach, which could have important implications for deploying robust and adaptable AI systems in real-world applications. Further research is needed to explore the limitations and potential extensions of this work, but the core ideas represent an important step forward in the field of continuous learning and adversarial robustness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Maintaining Adversarial Robustness in Continuous Learning
Xiaolei Ru, Xiaowei Cao, Zijia Liu, Jack Murdoch Moore, Xin-Ya Zhang, Xia Zhu, Wenjia Wei, Gang Yan
Adversarial robustness is essential for security and reliability of machine learning systems. However, adversarial robustness enhanced by defense algorithms is easily erased as the neural network's weights update to learn new tasks. To address this vulnerability, it is essential to improve the capability of neural networks in terms of robust continual learning. Specially, we propose a novel gradient projection technique that effectively stabilizes sample gradients from previous data by orthogonally projecting back-propagation gradients onto a crucial subspace before using them for weight updates. This technique can maintaining robustness by collaborating with a class of defense algorithms through sample gradient smoothing. The experimental results on four benchmarks including Split-CIFAR100 and Split-miniImageNet, demonstrate that the superiority of the proposed approach in mitigating rapidly degradation of robustness during continual learning even when facing strong adversarial attacks.
Read more8/14/2024
0
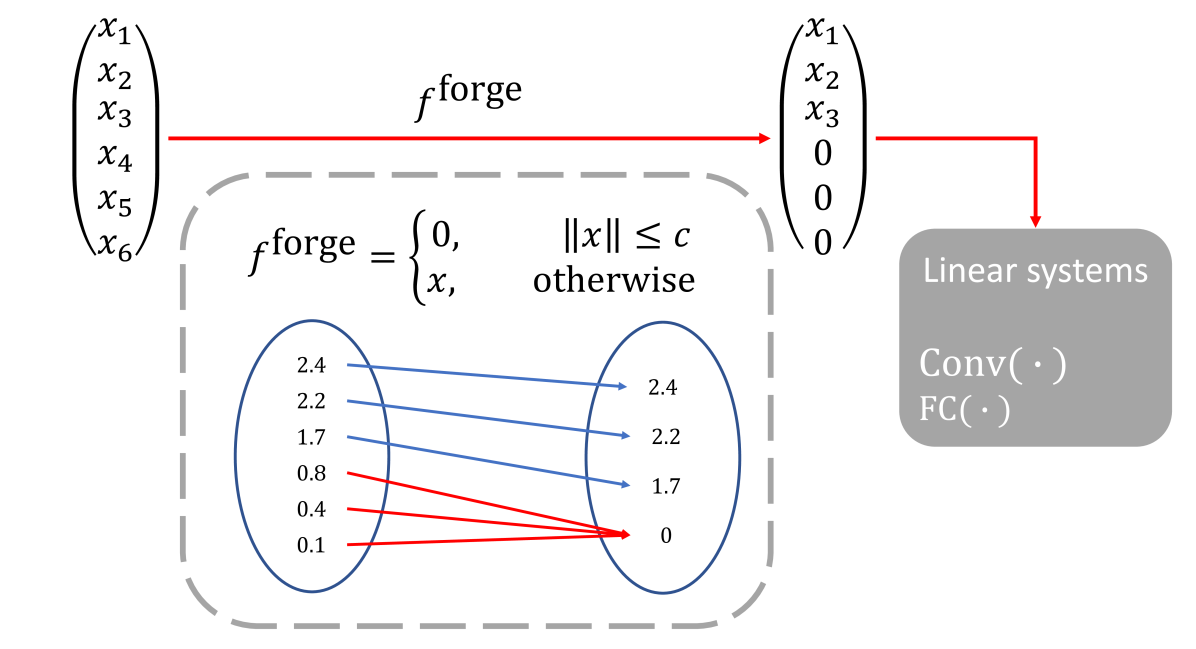
Data-Driven Lipschitz Continuity: A Cost-Effective Approach to Improve Adversarial Robustness
Erh-Chung Chen, Pin-Yu Chen, I-Hsin Chung, Che-Rung Lee
The security and robustness of deep neural networks (DNNs) have become increasingly concerning. This paper aims to provide both a theoretical foundation and a practical solution to ensure the reliability of DNNs. We explore the concept of Lipschitz continuity to certify the robustness of DNNs against adversarial attacks, which aim to mislead the network with adding imperceptible perturbations into inputs. We propose a novel algorithm that remaps the input domain into a constrained range, reducing the Lipschitz constant and potentially enhancing robustness. Unlike existing adversarially trained models, where robustness is enhanced by introducing additional examples from other datasets or generative models, our method is almost cost-free as it can be integrated with existing models without requiring re-training. Experimental results demonstrate the generalizability of our method, as it can be combined with various models and achieve enhancements in robustness. Furthermore, our method achieves the best robust accuracy for CIFAR10, CIFAR100, and ImageNet datasets on the RobustBench leaderboard.
Read more7/1/2024
0
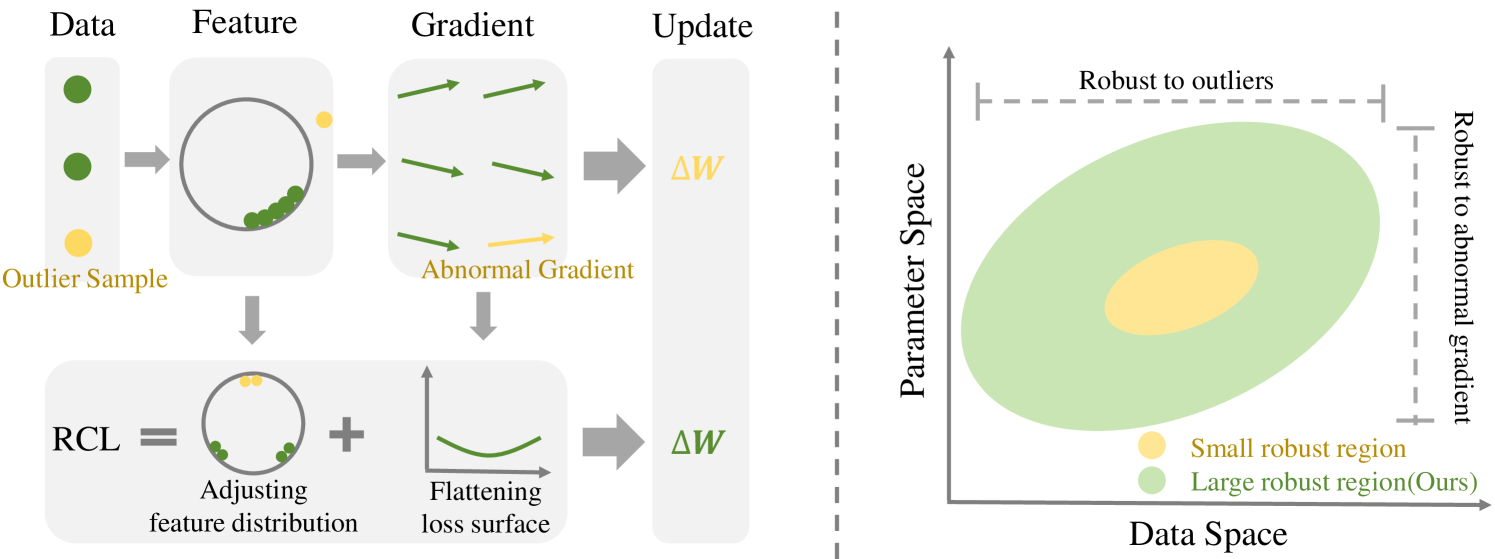
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
Read more5/28/2024

0
Efficient Adversarial Training in LLMs with Continuous Attacks
Sophie Xhonneux, Alessandro Sordoni, Stephan Gunnemann, Gauthier Gidel, Leo Schwinn
Large language models (LLMs) are vulnerable to adversarial attacks that can bypass their safety guardrails. In many domains, adversarial training has proven to be one of the most promising methods to reliably improve robustness against such attacks. Yet, in the context of LLMs, current methods for adversarial training are hindered by the high computational costs required to perform discrete adversarial attacks at each training iteration. We address this problem by instead calculating adversarial attacks in the continuous embedding space of the LLM, which is orders of magnitudes more efficient. We propose a fast adversarial training algorithm (C-AdvUL) composed of two losses: the first makes the model robust on continuous embedding attacks computed on an adversarial behaviour dataset; the second ensures the usefulness of the final model by fine-tuning on utility data. Moreover, we introduce C-AdvIPO, an adversarial variant of IPO that does not require utility data for adversarially robust alignment. Our empirical evaluation on four models from different families (Gemma, Phi3, Mistral, Zephyr) and at different scales (2B, 3.8B, 7B) shows that both algorithms substantially enhance LLM robustness against discrete attacks (GCG, AutoDAN, PAIR), while maintaining utility. Our results demonstrate that robustness to continuous perturbations can extrapolate to discrete threat models. Thereby, we present a path toward scalable adversarial training algorithms for robustly aligning LLMs.
Read more6/26/2024