Make-it-Real: Unleashing Large Multimodal Model's Ability for Painting 3D Objects with Realistic Materials

0
🏷️
Sign in to get full access
Overview
- Physically realistic materials are crucial for enhancing the realism of 3D assets across various applications and lighting conditions.
- Existing 3D assets and generative models often lack authentic material properties.
- Manual assignment of materials using graphic software is a tedious and time-consuming task.
- The paper presents a novel approach, "Make-it-Real," that exploits advancements in Multimodal Large Language Models (MLLMs), particularly GPT-4V, to streamline the material assignment process.
Plain English Explanation
The paper focuses on a problem that is crucial for creating realistic 3D graphics: accurately representing the materials and textures of objects. Many existing 3D assets and models, such as those used in video games or movies, don't accurately capture the true properties of materials like wood, metal, or fabric. Manually assigning materials using graphic design software is a time-consuming and tedious task.
The researchers have developed a new approach called "Make-it-Real" that uses advanced language models to help automate this process. These language models, particularly one called GPT-4V, are trained to recognize and describe different materials in detail. The researchers show that by combining visual information about 3D objects with hierarchical text prompts, GPT-4V can accurately identify and align the appropriate materials with the corresponding parts of the 3D model.
Once the materials are correctly matched, the system can then generate new, high-quality material textures that closely match the original 3D asset. This helps make the 3D models look much more realistic and authentic.
The researchers argue that this "Make-it-Real" approach can be seamlessly integrated into the 3D content creation workflow, making it a valuable tool for developers who need to create realistic 3D assets.
Technical Explanation
The paper presents a novel approach, "Make-it-Real," that leverages Multimodal Large Language Models (MLLMs), particularly GPT-4V, to address the challenge of assigning physically realistic materials to 3D assets.
The researchers first demonstrate that GPT-4V can effectively recognize and describe materials, allowing them to construct a detailed material library. They then utilize a combination of visual cues and hierarchical text prompts to enable GPT-4V to precisely identify and align the appropriate materials with the corresponding components of 3D objects.
Once the correct material-to-object alignments are established, the system meticulously applies the matched materials as a reference for generating new SVBRDF (Spatially Varying Bidirectional Reflectance Distribution Function) material properties, significantly enhancing the visual authenticity of the 3D assets.
The researchers showcase the seamless integration of their "Make-it-Real" approach into the 3D content creation workflow, highlighting its utility as an essential tool for developers of 3D assets.
Critical Analysis
The paper presents a promising approach to automating the assignment of realistic materials to 3D assets, which is a crucial task in the creation of visually compelling 3D graphics. The researchers' use of advanced Multimodal Large Language Models (MLLMs) like GPT-4V to recognize and describe materials is a novel and innovative solution.
However, the paper does not provide a detailed evaluation of the accuracy and reliability of the material identification and alignment process. It would be helpful to see quantitative metrics or user studies that assess the quality and realism of the generated materials compared to ground truth or manually created ones.
Additionally, the paper does not address potential limitations or edge cases, such as how the system might handle complex material interactions, weathering, or material variations within a single object. Exploring these aspects could help identify areas for further research and improvement.
It would also be valuable to understand the computational cost and training requirements of the "Make-it-Real" approach, as this could impact its practical adoption in real-world 3D content creation workflows.
Overall, the paper presents a promising direction for automating the material assignment process, but further research and evaluation are needed to fully assess the capabilities and limitations of the proposed approach.
Conclusion
The paper introduces a novel approach, "Make-it-Real," that leverages Multimodal Large Language Models (MLLMs), particularly GPT-4V, to streamline the process of assigning physically realistic materials to 3D assets.
By demonstrating the ability of GPT-4V to recognize and describe materials in detail, the researchers have developed a system that can effectively identify and align the appropriate materials with the corresponding components of 3D objects. This, in turn, allows for the generation of high-quality SVBRDF material properties that significantly enhance the visual authenticity of the 3D assets.
The seamless integration of the "Make-it-Real" approach into the 3D content creation workflow makes it a valuable tool for developers who need to create realistic 3D assets for various applications, such as video games, movies, and architectural visualizations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Make-it-Real: Unleashing Large Multimodal Model's Ability for Painting 3D Objects with Realistic Materials
Ye Fang, Zeyi Sun, Tong Wu, Jiaqi Wang, Ziwei Liu, Gordon Wetzstein, Dahua Lin
Physically realistic materials are pivotal in augmenting the realism of 3D assets across various applications and lighting conditions. However, existing 3D assets and generative models often lack authentic material properties. Manual assignment of materials using graphic software is a tedious and time-consuming task. In this paper, we exploit advancements in Multimodal Large Language Models (MLLMs), particularly GPT-4V, to present a novel approach, Make-it-Real: 1) We demonstrate that GPT-4V can effectively recognize and describe materials, allowing the construction of a detailed material library. 2) Utilizing a combination of visual cues and hierarchical text prompts, GPT-4V precisely identifies and aligns materials with the corresponding components of 3D objects. 3) The correctly matched materials are then meticulously applied as reference for the new SVBRDF material generation according to the original albedo map, significantly enhancing their visual authenticity. Make-it-Real offers a streamlined integration into the 3D content creation workflow, showcasing its utility as an essential tool for developers of 3D assets.
Read more5/27/2024
📈
0
MaPa: Text-driven Photorealistic Material Painting for 3D Shapes
Shangzhan Zhang, Sida Peng, Tao Xu, Yuanbo Yang, Tianrun Chen, Nan Xue, Yujun Shen, Hujun Bao, Ruizhen Hu, Xiaowei Zhou
This paper aims to generate materials for 3D meshes from text descriptions. Unlike existing methods that synthesize texture maps, we propose to generate segment-wise procedural material graphs as the appearance representation, which supports high-quality rendering and provides substantial flexibility in editing. Instead of relying on extensive paired data, i.e., 3D meshes with material graphs and corresponding text descriptions, to train a material graph generative model, we propose to leverage the pre-trained 2D diffusion model as a bridge to connect the text and material graphs. Specifically, our approach decomposes a shape into a set of segments and designs a segment-controlled diffusion model to synthesize 2D images that are aligned with mesh parts. Based on generated images, we initialize parameters of material graphs and fine-tune them through the differentiable rendering module to produce materials in accordance with the textual description. Extensive experiments demonstrate the superior performance of our framework in photorealism, resolution, and editability over existing methods. Project page: https://zhanghe3z.github.io/MaPa/
Read more4/29/2024
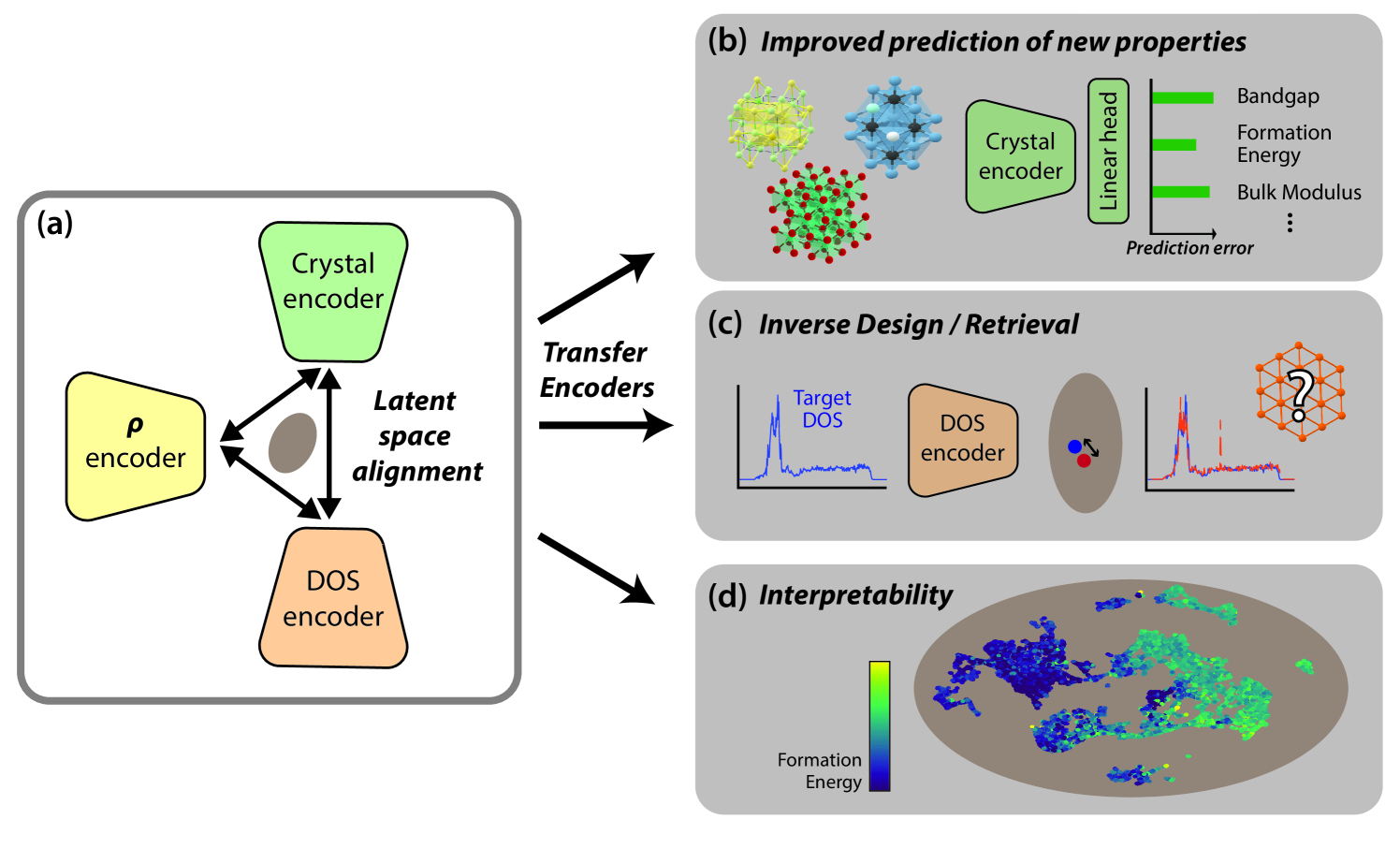
0
Multimodal Learning for Materials
Viggo Moro, Charlotte Loh, Rumen Dangovski, Ali Ghorashi, Andrew Ma, Zhuo Chen, Samuel Kim, Peter Y. Lu, Thomas Christensen, Marin Soljav{c}i'c
Artificial intelligence is transforming computational materials science, improving the prediction of material properties, and accelerating the discovery of novel materials. Recently, publicly available material data repositories have grown rapidly. This growth encompasses not only more materials, but also a greater variety and quantity of their associated properties. Existing machine learning efforts in materials science focus primarily on single-modality tasks, i.e., relationships between materials and a single physical property, thus not taking advantage of the rich and multimodal set of material properties. Here, we introduce Multimodal Learning for Materials (MultiMat), which enables self-supervised multi-modality training of foundation models for materials. We demonstrate our framework's potential using data from the Materials Project database on multiple axes: (i) MultiMat achieves state-of-the-art performance for challenging material property prediction tasks; (ii) MultiMat enables novel and accurate material discovery via latent space similarity, enabling screening for stable materials with desired properties; and (iii) MultiMat encodes interpretable emergent features that may provide novel scientific insights.
Read more4/15/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024