Multimodal Learning for Materials
2312.00111
0
0
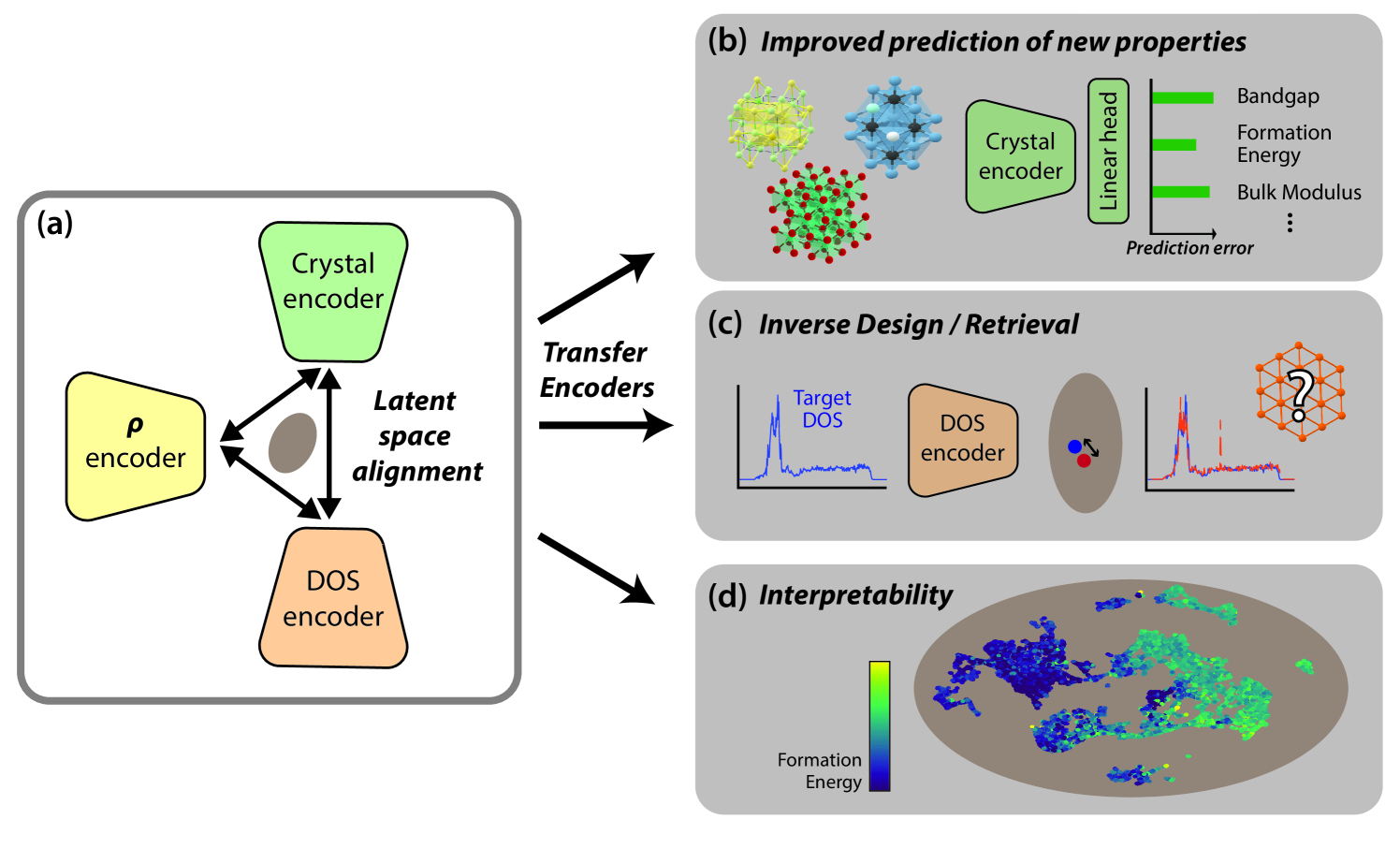
Abstract
Artificial intelligence is transforming computational materials science, improving the prediction of material properties, and accelerating the discovery of novel materials. Recently, publicly available material data repositories have grown rapidly. This growth encompasses not only more materials, but also a greater variety and quantity of their associated properties. Existing machine learning efforts in materials science focus primarily on single-modality tasks, i.e., relationships between materials and a single physical property, thus not taking advantage of the rich and multimodal set of material properties. Here, we introduce Multimodal Learning for Materials (MultiMat), which enables self-supervised multi-modality training of foundation models for materials. We demonstrate our framework's potential using data from the Materials Project database on multiple axes: (i) MultiMat achieves state-of-the-art performance for challenging material property prediction tasks; (ii) MultiMat enables novel and accurate material discovery via latent space similarity, enabling screening for stable materials with desired properties; and (iii) MultiMat encodes interpretable emergent features that may provide novel scientific insights.
Create account to get full access
Overview
- This paper presents a multimodal learning approach for predicting properties of crystalline materials.
- The researchers develop methods to pre-train models on a combination of textual, visual, and structural data related to materials science.
- These pre-trained models are then fine-tuned to perform specific tasks like predicting crystal properties.
- The results demonstrate that multimodal learning can outperform unimodal approaches and lead to more accurate predictions.
Plain English Explanation
Crystalline materials, like those found in computer chips or solar panels, have important properties that scientists need to understand and predict. This paper explores a new way to learn about these materials by combining different types of data.
Typically, researchers might only use one type of data, like text descriptions or images, to try to predict a material's properties. But the authors of this paper hypothesized that using multiple types of data, or "multimodal" learning, could lead to better predictions.
So they developed methods to pre-train machine learning models on a combination of textual information, visual data (like microscope images), and structural data about the atomic arrangement of the materials. Then they fine-tuned these pre-trained models to specific tasks, like predicting a material's energy or stability.
The results showed that the multimodal models outperformed models trained on just one type of data. This suggests that by combining different sources of information, the models were able to learn more comprehensive representations of the materials and make more accurate predictions.
Technical Explanation
The authors introduced a multimodal pre-training approach to learn representations of crystalline materials from a combination of textual, visual, and structural data. They first collected a large dataset containing scientific papers, microscope images, and atomic structure information for a variety of materials.
They then developed three pre-training methods to learn multimodal representations from this data:
-
Multimodal Contrastive Learning: Models were trained to predict whether pairs of text, images, and structures belonged to the same material or not.
-
Multimodal Masked Modeling: Models were trained to predict missing parts of the input data (e.g. a masked word in the text, a missing section of an image, or the atomic coordinates of a structure).
-
Multimodal Regression: Models were trained to directly predict material properties like energy or stability from the combined multimodal inputs.
These pre-trained multimodal models were then fine-tuned on specific crystal property prediction tasks. The results showed that the multimodal models consistently outperformed unimodal models that only used a single data modality. This indicates the multimodal representations captured richer and more generalizable information about the materials.
Critical Analysis
The paper provides a compelling demonstration of the benefits of multimodal learning for materials science applications. By jointly modeling textual, visual, and structural data, the models were able to learn more holistic representations of the crystalline materials.
However, the authors acknowledge that their dataset and tasks were relatively narrow in scope. Extending this approach to a wider range of materials and properties would be an important next step to further validate the generalizability of their findings.
Additionally, the authors did not provide much insight into the specific types of representations or features that the multimodal models were able to learn. A deeper analysis of the model internals could shed light on the mechanisms underlying the performance improvements.
Overall, this work highlights the potential for multimodal machine learning techniques to advance materials discovery and design. With further research and refinement, these methods could become a valuable tool in the materials science toolbox.
Conclusion
This paper demonstrates that a multimodal learning approach, which combines textual, visual, and structural data, can outperform traditional unimodal methods for predicting the properties of crystalline materials. By pre-training models on diverse data sources and fine-tuning them for specific tasks, the researchers were able to develop more accurate and generalizable representations of the materials.
These findings suggest that embracing the multidisciplinary nature of materials science through multimodal machine learning techniques could lead to significant advancements in our understanding and design of functional materials. As the field continues to evolve, integrating diverse data sources and modeling approaches will likely be crucial for accelerating materials discovery and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMatDesign: Autonomous Materials Discovery with Large Language Models
Shuyi Jia, Chao Zhang, Victor Fung
0
0
Discovering new materials can have significant scientific and technological implications but remains a challenging problem today due to the enormity of the chemical space. Recent advances in machine learning have enabled data-driven methods to rapidly screen or generate promising materials, but these methods still depend heavily on very large quantities of training data and often lack the flexibility and chemical understanding often desired in materials discovery. We introduce LLMatDesign, a novel language-based framework for interpretable materials design powered by large language models (LLMs). LLMatDesign utilizes LLM agents to translate human instructions, apply modifications to materials, and evaluate outcomes using provided tools. By incorporating self-reflection on its previous decisions, LLMatDesign adapts rapidly to new tasks and conditions in a zero-shot manner. A systematic evaluation of LLMatDesign on several materials design tasks, in silico, validates LLMatDesign's effectiveness in developing new materials with user-defined target properties in the small data regime. Our framework demonstrates the remarkable potential of autonomous LLM-guided materials discovery in the computational setting and towards self-driving laboratories in the future.
6/21/2024
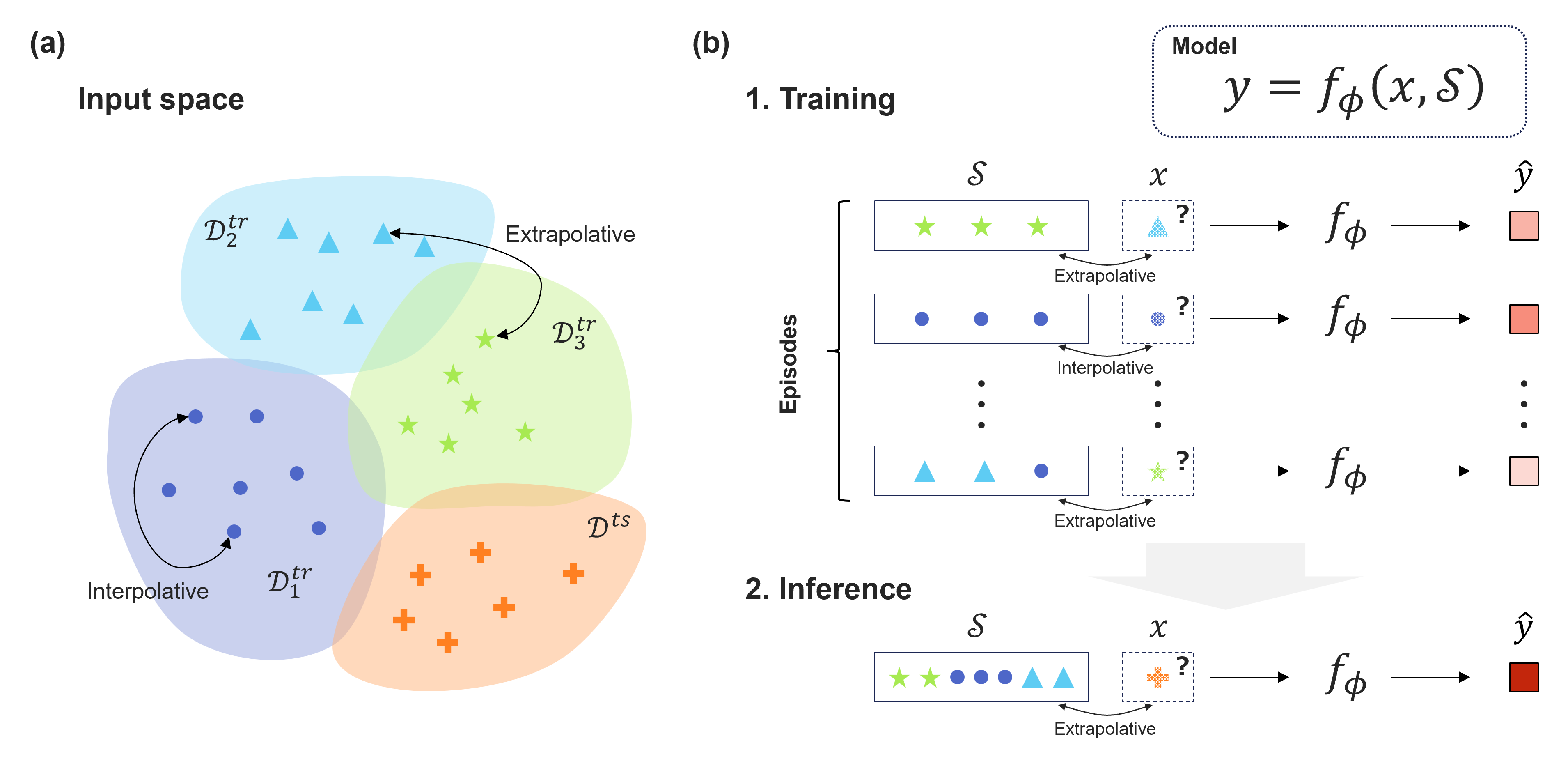
Advancing Extrapolative Predictions of Material Properties through Learning to Learn
Kohei Noda, Araki Wakiuchi, Yoshihiro Hayashi, Ryo Yoshida
0
0
Recent advancements in machine learning have showcased its potential to significantly accelerate the discovery of new materials. Central to this progress is the development of rapidly computable property predictors, enabling the identification of novel materials with desired properties from vast material spaces. However, the limited availability of data resources poses a significant challenge in data-driven materials research, particularly hindering the exploration of innovative materials beyond the boundaries of existing data. While machine learning predictors are inherently interpolative, establishing a general methodology to create an extrapolative predictor remains a fundamental challenge, limiting the search for innovative materials beyond existing data boundaries. In this study, we leverage an attention-based architecture of neural networks and meta-learning algorithms to acquire extrapolative generalization capability. The meta-learners, experienced repeatedly with arbitrarily generated extrapolative tasks, can acquire outstanding generalization capability in unexplored material spaces. Through the tasks of predicting the physical properties of polymeric materials and hybrid organic--inorganic perovskites, we highlight the potential of such extrapolatively trained models, particularly with their ability to rapidly adapt to unseen material domains in transfer learning scenarios.
4/16/2024
🏷️
Make-it-Real: Unleashing Large Multimodal Model's Ability for Painting 3D Objects with Realistic Materials
Ye Fang, Zeyi Sun, Tong Wu, Jiaqi Wang, Ziwei Liu, Gordon Wetzstein, Dahua Lin
0
0
Physically realistic materials are pivotal in augmenting the realism of 3D assets across various applications and lighting conditions. However, existing 3D assets and generative models often lack authentic material properties. Manual assignment of materials using graphic software is a tedious and time-consuming task. In this paper, we exploit advancements in Multimodal Large Language Models (MLLMs), particularly GPT-4V, to present a novel approach, Make-it-Real: 1) We demonstrate that GPT-4V can effectively recognize and describe materials, allowing the construction of a detailed material library. 2) Utilizing a combination of visual cues and hierarchical text prompts, GPT-4V precisely identifies and aligns materials with the corresponding components of 3D objects. 3) The correctly matched materials are then meticulously applied as reference for the new SVBRDF material generation according to the original albedo map, significantly enhancing their visual authenticity. Make-it-Real offers a streamlined integration into the 3D content creation workflow, showcasing its utility as an essential tool for developers of 3D assets.
5/27/2024
🧪
Foundations of Multisensory Artificial Intelligence
Paul Pu Liang
0
0
Building multisensory AI systems that learn from multiple sensory inputs such as text, speech, video, real-world sensors, wearable devices, and medical data holds great promise for impact in many scientific areas with practical benefits, such as in supporting human health and well-being, enabling multimedia content processing, and enhancing real-world autonomous agents. By synthesizing a range of theoretical frameworks and application domains, this thesis aims to advance the machine learning foundations of multisensory AI. In the first part, we present a theoretical framework formalizing how modalities interact with each other to give rise to new information for a task. These interactions are the basic building blocks in all multimodal problems, and their quantification enables users to understand their multimodal datasets, design principled approaches to learn these interactions, and analyze whether their model has succeeded in learning. In the second part, we study the design of practical multimodal foundation models that generalize over many modalities and tasks, which presents a step toward grounding large language models to real-world sensory modalities. We introduce MultiBench, a unified large-scale benchmark across a wide range of modalities, tasks, and research areas, followed by the cross-modal attention and multimodal transformer architectures that now underpin many of today's multimodal foundation models. Scaling these architectures on MultiBench enables the creation of general-purpose multisensory AI systems, and we discuss our collaborative efforts in applying these models for real-world impact in affective computing, mental health, cancer prognosis, and robotics. Finally, we conclude this thesis by discussing how future work can leverage these ideas toward more general, interactive, and safe multisensory AI.
5/1/2024