Mamba meets crack segmentation

0
🔮
Sign in to get full access
Overview
- Cracks pose safety risks to infrastructure and cannot be overlooked.
- Existing crack segmentation networks use convolutional neural networks (CNNs) or transformers.
- CNNs lack global modeling capability, hindering representation of entire crack features.
- Transformers can capture long-range dependencies but suffer from high computational complexity.
- Mamba, a recent architecture, has gained attention for its linear complexity and powerful global perception.
Plain English Explanation
Cracks in infrastructure like roads and buildings can be dangerous if left unaddressed. Current AI models used to detect these cracks typically rely on convolutional neural networks (CNNs) or transformers.
CNNs have trouble capturing the full shape and extent of cracks, while transformers can model long-range connections but are computationally expensive. A newer architecture called Mamba aims to address these limitations with its linear complexity and powerful global perception.
This study explores using Mamba to improve crack detection and segmentation. The researchers propose a novel "CrackMamba" module that integrates Mamba with attention mechanisms, allowing the model to better understand the complete crack structure. They compare CrackMamba to other Mamba-based models on datasets of pavement and steel cracks.
Technical Explanation
The paper investigates using the Mamba architecture to enhance crack segmentation capabilities. Mamba has garnered attention for its linear computational complexity and strong global perception, in contrast to the limitations of CNNs and transformers.
The key contribution is the introduction of CrackMamba, a novel Mamba-based module that integrates attention mechanisms. The researchers uncover the connection between Mamba and attention, using this insight to devise CrackMamba following the principles of attention blocks.
Experiments compare CrackMamba to other prominent Mamba modules (Vim and Vmamba) on two crack segmentation datasets - one for asphalt/concrete pavement cracks, and one for steel cracks. The results show that CrackMamba consistently outperforms the baseline models across evaluation metrics, while also reducing the number of model parameters and computational cost.
The paper also provides theoretical analysis and visual interpretability to demonstrate that Mamba can achieve global receptive fields, addressing a key limitation of CNNs.
Critical Analysis
The paper makes a compelling case for the use of Mamba-based architectures to improve crack segmentation. The proposed CrackMamba module appears to be a promising and effective solution, outperforming other Mamba variants on the evaluated datasets.
However, the paper does not discuss the potential limitations or challenges of applying Mamba to real-world crack detection scenarios. For example, the performance of CrackMamba on more diverse or noisy crack datasets is not explored. Additionally, the paper could have provided more details on the computational efficiency of CrackMamba compared to other state-of-the-art crack segmentation models beyond just the Mamba variants.
Further research could investigate the robustness and generalizability of CrackMamba, as well as explore ways to integrate it with other crack detection techniques or deploy it in practical infrastructure monitoring applications.
Conclusion
This study demonstrates the potential of the Mamba architecture to enhance crack segmentation models. The proposed CrackMamba module, which integrates Mamba with attention mechanisms, consistently outperforms other Mamba-based models on crack detection tasks while also reducing computational complexity.
The findings offer a promising "plug-and-play" solution for incorporating CrackMamba into various crack segmentation systems. Additionally, the insights on the relationship between Mamba and attention provide a valuable conceptual framework for designing other Mamba-based computer vision models beyond just crack detection.
Overall, this research highlights the advantages of the Mamba architecture and introduces a novel technique, CrackMamba, that could have significant implications for improving the safety and maintenance of critical infrastructure.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Mamba meets crack segmentation
Zhili He, Yu-Hsing Wang
Cracks pose safety risks to infrastructure and cannot be overlooked. The prevailing structures in existing crack segmentation networks predominantly consist of CNNs or Transformers. However, CNNs exhibit a deficiency in global modeling capability, hindering the representation to entire crack features. Transformers can capture long-range dependencies but suffer from high and quadratic complexity. Recently, Mamba has garnered extensive attention due to its linear spatial and computational complexity and its powerful global perception. This study explores the representation capabilities of Mamba to crack features. Specifically, this paper uncovers the connection between Mamba and the attention mechanism, providing a profound insight, an attention perspective, into interpreting Mamba and devising a novel Mamba module following the principles of attention blocks, namely CrackMamba. We compare CrackMamba with the most prominent visual Mamba modules, Vim and Vmamba, on two datasets comprising asphalt pavement and concrete pavement cracks, and steel cracks, respectively. The quantitative results show that CrackMamba stands out as the sole Mamba block consistently enhancing the baseline model's performance across all evaluation measures, while reducing its parameters and computational costs. Moreover, this paper substantiates that Mamba can achieve global receptive fields through both theoretical analysis and visual interpretability. The discoveries of this study offer a dual contribution. First, as a plug-and-play and simple yet effective Mamba module, CrackMamba exhibits immense potential for integration into various crack segmentation models. Second, the proposed innovative Mamba design concept, integrating Mamba with the attention mechanism, holds significant reference value for all Mamba-based computer vision models, not limited to crack segmentation networks, as investigated in this study.
Read more7/23/2024
👀
0
Vision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces
Zhaohui Chen, Elyas Asadi Shamsabadi, Sheng Jiang, Luming Shen, Daniel Dias-da-Costa
Convolutional neural networks (CNNs) and Transformers have shown advanced accuracy in crack detection under certain conditions. Yet, the fixed local attention can compromise the generalisation of CNNs, and the quadratic complexity of the global self-attention restricts the practical deployment of Transformers. Given the emergence of the new-generation architecture of Mamba, this paper proposes a Vision Mamba (VMamba)-based framework for crack segmentation on concrete, asphalt, and masonry surfaces, with high accuracy, generalisation, and less computational complexity. Having 15.6% - 74.5% fewer parameters, the encoder-decoder network integrated with VMamba could obtain up to 2.8% higher mDS than representative CNN-based models while showing about the same performance as Transformer-based models. Moreover, the VMamba-based encoder-decoder network could process high-resolution image input with up to 90.6% lower floating-point operations.
Read more6/26/2024
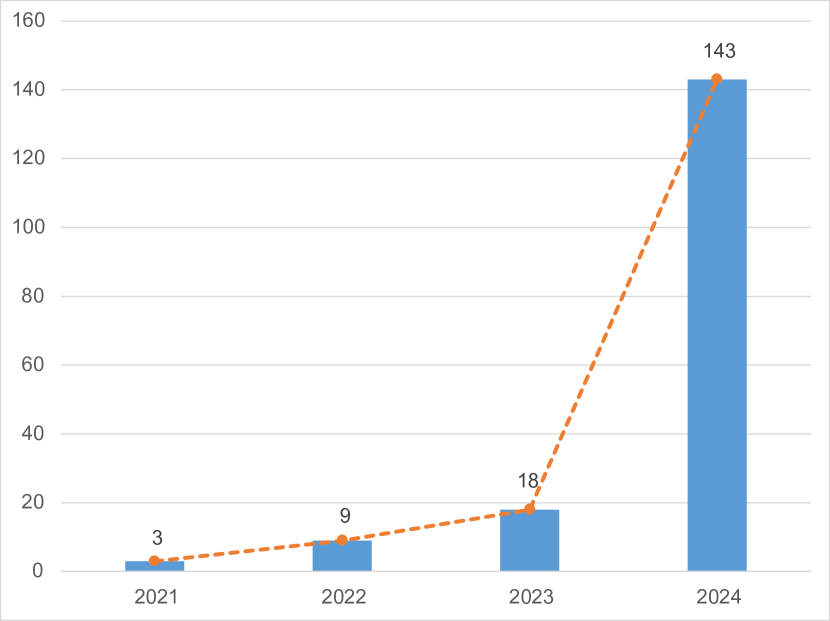
0
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
Read more4/29/2024
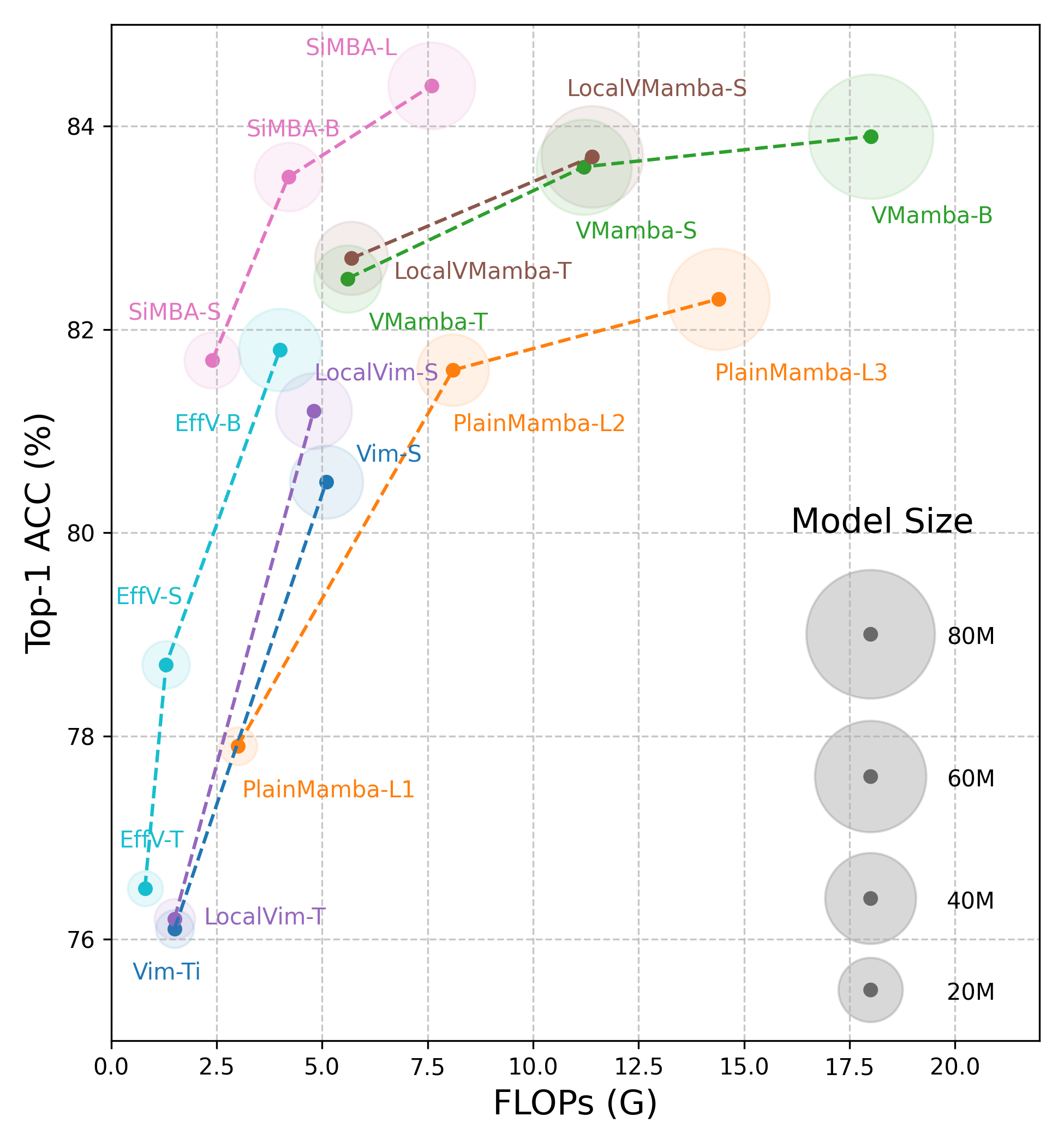
0
A Survey on Vision Mamba: Models, Applications and Challenges
Rui Xu, Shu Yang, Yihui Wang, Yu Cai, Bo Du, Hao Chen
Mamba, a recent selective structured state space model, excels in long sequence modeling, which is vital in the large model era. Long sequence modeling poses significant challenges, including capturing long-range dependencies within the data and handling the computational demands caused by their extensive length. Mamba addresses these challenges by overcoming the local perception limitations of convolutional neural networks and the quadratic computational complexity of Transformers. Given its advantages over these mainstream foundation architectures, Mamba exhibits great potential to be a visual foundation architecture. Since January 2024, Mamba has been actively applied to diverse computer vision tasks, yielding numerous contributions. To help keep pace with the rapid advancements, this paper reviews visual Mamba approaches, analyzing over 200 papers. This paper begins by delineating the formulation of the original Mamba model. Subsequently, it delves into representative backbone networks, and applications categorized using different modalities, including image, video, point cloud, and multi-modal. Particularly, we identify scanning techniques as critical for adapting Mamba to vision tasks, and decouple these scanning techniques to clarify their functionality and enhance their flexibility across various applications. Finally, we discuss the challenges and future directions, providing insights into new outlooks in this fast evolving area. A comprehensive list of visual Mamba models reviewed in this work is available at https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models.
Read more7/9/2024