Vision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces

0
👀
Sign in to get full access
Overview
- Convolutional neural networks (CNNs) and Transformers have shown advanced accuracy in crack detection, but they have limitations.
- CNNs' fixed local attention can compromise generalization, and Transformers' quadratic complexity restricts practical deployment.
- This paper proposes a Vision Mamba (VMamba)-based framework for crack segmentation on concrete, asphalt, and masonry surfaces, aiming for high accuracy, generalization, and less computational complexity.
Plain English Explanation
The paper introduces a new approach called Vision Mamba (VMamba) to tackle the limitations of existing crack detection methods. Convolutional neural networks (CNNs) and Transformers have shown promising results, but they have some drawbacks. CNNs' fixed local attention can make them struggle to generalize well, while Transformers' global self-attention mechanism is computationally expensive, making it challenging to deploy in practical applications.
The researchers propose using the VMamba architecture, which is a new type of neural network that can capture both local and global information more efficiently. This VMamba-based framework is designed for crack segmentation on different types of surfaces, such as concrete, asphalt, and masonry. The goal is to achieve high accuracy, good generalization (the ability to work well on new, unseen data), and lower computational complexity compared to existing methods.
Technical Explanation
The paper presents a VMamba-based encoder-decoder network for crack segmentation. The encoder-decoder architecture is a common approach in computer vision, where the encoder extracts features from the input image, and the decoder generates the final segmentation map.
The key innovation in this work is the use of the VMamba module in the encoder-decoder network. The VMamba module is a new type of neural network layer that can efficiently capture both local and global information, addressing the limitations of CNNs and Transformers.
Compared to representative CNN-based models, the proposed VMamba-based encoder-decoder network has 15.6% to 74.5% fewer parameters but can achieve up to 2.8% higher mean Dice Similarity (mDS) score, which is a common metric for segmentation performance. Additionally, the VMamba-based network can process high-resolution images with up to 90.6% lower floating-point operations, indicating its computational efficiency.
Critical Analysis
The paper presents a promising approach to crack segmentation, leveraging the advantages of the VMamba architecture to address the limitations of CNNs and Transformers. The experimental results demonstrate the effectiveness of the proposed method in terms of accuracy, generalization, and computational efficiency.
However, the paper does not provide a comprehensive comparison to other state-of-the-art methods beyond the selected CNN and Transformer-based models. It would be valuable to see how the VMamba-based approach performs against a wider range of crack detection techniques, including more recent developments in the field.
Additionally, the paper could benefit from a more detailed discussion of the limitations and potential drawbacks of the VMamba-based framework. For example, it would be interesting to understand the trade-offs between the computational benefits and any potential constraints on the model's capacity or expressiveness.
Conclusion
This paper introduces a VMamba-based encoder-decoder network for accurate and efficient crack segmentation on various surfaces. By leveraging the advantages of the VMamba architecture, the proposed method can achieve high segmentation performance with lower computational complexity compared to representative CNN and Transformer-based models.
The results suggest that the VMamba-based approach holds promise for practical deployment in applications where crack detection is crucial, such as infrastructure monitoring and maintenance. Further research and benchmarking against a wider range of methods could help solidify the advantages and identify any limitations of this innovative approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Vision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces
Zhaohui Chen, Elyas Asadi Shamsabadi, Sheng Jiang, Luming Shen, Daniel Dias-da-Costa
Convolutional neural networks (CNNs) and Transformers have shown advanced accuracy in crack detection under certain conditions. Yet, the fixed local attention can compromise the generalisation of CNNs, and the quadratic complexity of the global self-attention restricts the practical deployment of Transformers. Given the emergence of the new-generation architecture of Mamba, this paper proposes a Vision Mamba (VMamba)-based framework for crack segmentation on concrete, asphalt, and masonry surfaces, with high accuracy, generalisation, and less computational complexity. Having 15.6% - 74.5% fewer parameters, the encoder-decoder network integrated with VMamba could obtain up to 2.8% higher mDS than representative CNN-based models while showing about the same performance as Transformer-based models. Moreover, the VMamba-based encoder-decoder network could process high-resolution image input with up to 90.6% lower floating-point operations.
Read more6/26/2024
🔮
0
Mamba meets crack segmentation
Zhili He, Yu-Hsing Wang
Cracks pose safety risks to infrastructure and cannot be overlooked. The prevailing structures in existing crack segmentation networks predominantly consist of CNNs or Transformers. However, CNNs exhibit a deficiency in global modeling capability, hindering the representation to entire crack features. Transformers can capture long-range dependencies but suffer from high and quadratic complexity. Recently, Mamba has garnered extensive attention due to its linear spatial and computational complexity and its powerful global perception. This study explores the representation capabilities of Mamba to crack features. Specifically, this paper uncovers the connection between Mamba and the attention mechanism, providing a profound insight, an attention perspective, into interpreting Mamba and devising a novel Mamba module following the principles of attention blocks, namely CrackMamba. We compare CrackMamba with the most prominent visual Mamba modules, Vim and Vmamba, on two datasets comprising asphalt pavement and concrete pavement cracks, and steel cracks, respectively. The quantitative results show that CrackMamba stands out as the sole Mamba block consistently enhancing the baseline model's performance across all evaluation measures, while reducing its parameters and computational costs. Moreover, this paper substantiates that Mamba can achieve global receptive fields through both theoretical analysis and visual interpretability. The discoveries of this study offer a dual contribution. First, as a plug-and-play and simple yet effective Mamba module, CrackMamba exhibits immense potential for integration into various crack segmentation models. Second, the proposed innovative Mamba design concept, integrating Mamba with the attention mechanism, holds significant reference value for all Mamba-based computer vision models, not limited to crack segmentation networks, as investigated in this study.
Read more7/23/2024

0
Convolution and Attention-Free Mamba-based Cardiac Image Segmentation
Abbas Khan, Muhammad Asad, Martin Benning, Caroline Roney, Gregory Slabaugh
Convolutional Neural Networks (CNNs) and Transformer-based self-attention models have become the standard for medical image segmentation. This paper demonstrates that convolution and self-attention, while widely used, are not the only effective methods for segmentation. Breaking with convention, we present a Convolution and self-Attention-free Mamba-based semantic Segmentation Network named CAMS-Net. Specifically, we design Mamba-based Channel Aggregator and Spatial Aggregator, which are applied independently in each encoder-decoder stage. The Channel Aggregator extracts information across different channels, and the Spatial Aggregator learns features across different spatial locations. We also propose a Linearly Interconnected Factorized Mamba (LIFM) block to reduce the computational complexity of a Mamba block and to enhance its decision function by introducing a non-linearity between two factorized Mamba blocks. Our model outperforms the existing state-of-the-art CNN, self-attention, and Mamba-based methods on CMR and M&Ms-2 Cardiac segmentation datasets, showing how this innovative, convolution, and self-attention-free method can inspire further research beyond CNN and Transformer paradigms, achieving linear complexity and reducing the number of parameters. Source code and pre-trained models will be publicly available upon acceptance.
Read more9/11/2024
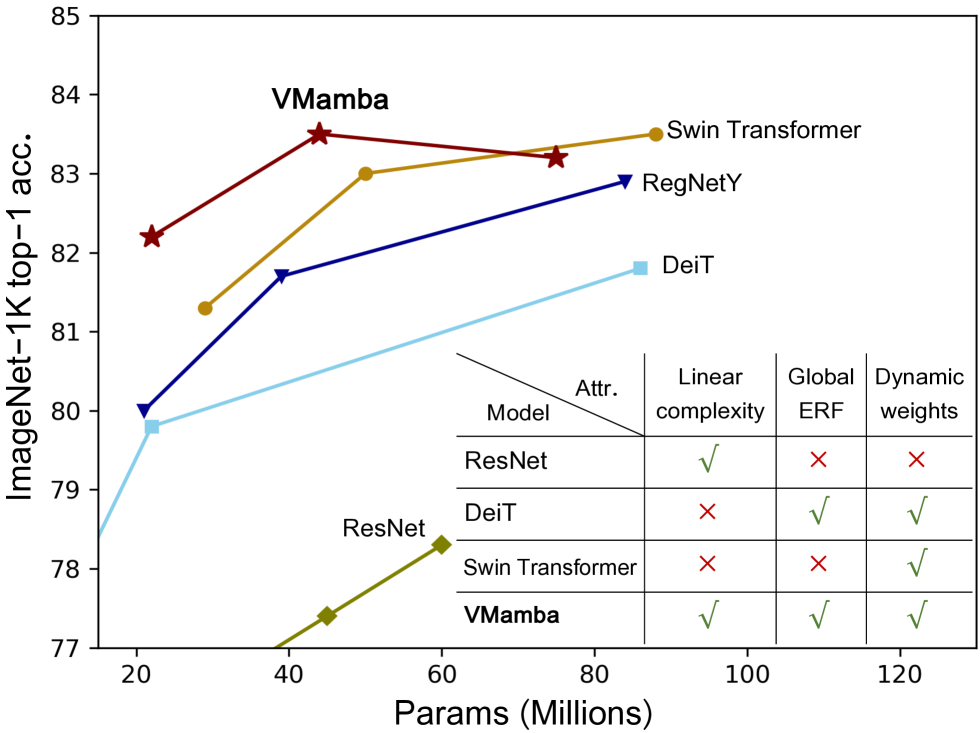
0
VMamba: Visual State Space Model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
Designing computationally efficient network architectures persists as an ongoing necessity in computer vision. In this paper, we transplant Mamba, a state-space language model, into VMamba, a vision backbone that works in linear time complexity. At the core of VMamba lies a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D helps bridge the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the gathering of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments showcase VMamba's promising performance across diverse visual perception tasks, highlighting its advantages in input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba.
Read more5/28/2024