Mamba-ND: Selective State Space Modeling for Multi-Dimensional Data

0

Sign in to get full access
Overview
- The paper introduces Mamba-ND, a framework for selective state space modeling of multi-dimensional data
- It addresses the challenges of modeling complex, high-dimensional data with traditional state space models
- The key innovations include a selective state approach to reduce model complexity and an efficient inference algorithm for linear time computation
Plain English Explanation
Mamba-ND is a new way to model complex, multi-dimensional data using a technique called state space modeling. Traditional state space models can struggle with high-dimensional data, as the number of states grows exponentially.
Mamba-ND solves this by selectively representing only the most important states, reducing the model complexity. This selective state approach allows Mamba-ND to efficiently model data like images or long-term sequences in linear time, rather than the exponential time required by previous methods.
The paper demonstrates how Mamba-ND outperforms existing state space models on a variety of multi-dimensional tasks, making it a promising new tool for working with complex, high-dimensional data.
Technical Explanation
The key innovation in Mamba-ND is the selective state space approach, which differs from traditional state space models. Instead of representing every possible state, Mamba-ND only maintains the most important states, reducing the overall model complexity.
This selective state representation is combined with an efficient inference algorithm that can compute the model outputs in linear time, rather than the exponential time required by previous state space methods. The paper provides details on the model architecture and training procedure, as well as extensive experiments demonstrating Mamba-ND's performance advantages on multi-dimensional datasets, including image and sequence modeling tasks.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the Mamba-ND framework. However, some potential limitations are worth noting:
- The selective state approach, while effective, may not capture all the nuances of high-dimensional data. There could be important states that are discarded by the model.
- The linear time inference is a significant advantage, but the training process may still be computationally expensive, especially for very large datasets.
- The paper focuses on generic multi-dimensional data, but does not dive deep into specific application domains. Further research may be needed to fully understand Mamba-ND's performance in real-world scenarios.
Overall, Mamba-ND represents an impressive advancement in state space modeling for complex data, but there is still room for further refinement and exploration of its capabilities and limitations.
Conclusion
The Mamba-ND framework introduced in this paper offers a novel approach to modeling high-dimensional, multi-dimensional data using selective state space representations. By selectively maintaining only the most important states, Mamba-ND can achieve efficient, linear-time inference, overcoming the limitations of traditional state space models.
The paper's thorough evaluation demonstrates Mamba-ND's strong performance on a variety of multi-dimensional tasks, making it a promising tool for researchers and practitioners working with complex, high-dimensional data. As the field of state space modeling continues to evolve, Mamba-ND's selective state approach could have far-reaching implications for how we model and understand complex, real-world phenomena.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mamba-ND: Selective State Space Modeling for Multi-Dimensional Data
Shufan Li, Harkanwar Singh, Aditya Grover
In recent years, Transformers have become the de-facto architecture for sequence modeling on text and a variety of multi-dimensional data, such as images and video. However, the use of self-attention layers in a Transformer incurs prohibitive compute and memory complexity that scales quadratically w.r.t. the sequence length. A recent architecture, Mamba, based on state space models has been shown to achieve comparable performance for modeling text sequences, while scaling linearly with the sequence length. In this work, we present Mamba-ND, a generalized design extending the Mamba architecture to arbitrary multi-dimensional data. Our design alternatively unravels the input data across different dimensions following row-major orderings. We provide a systematic comparison of Mamba-ND with several other alternatives, based on prior multi-dimensional extensions such as Bi-directional LSTMs and S4ND. Empirically, we show that Mamba-ND demonstrates performance competitive with the state-of-the-art on a variety of multi-dimensional benchmarks, including ImageNet-1K classification, HMDB-51 action recognition, and ERA5 weather forecasting.
Read more7/16/2024
🤷
91
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Read more6/3/2024
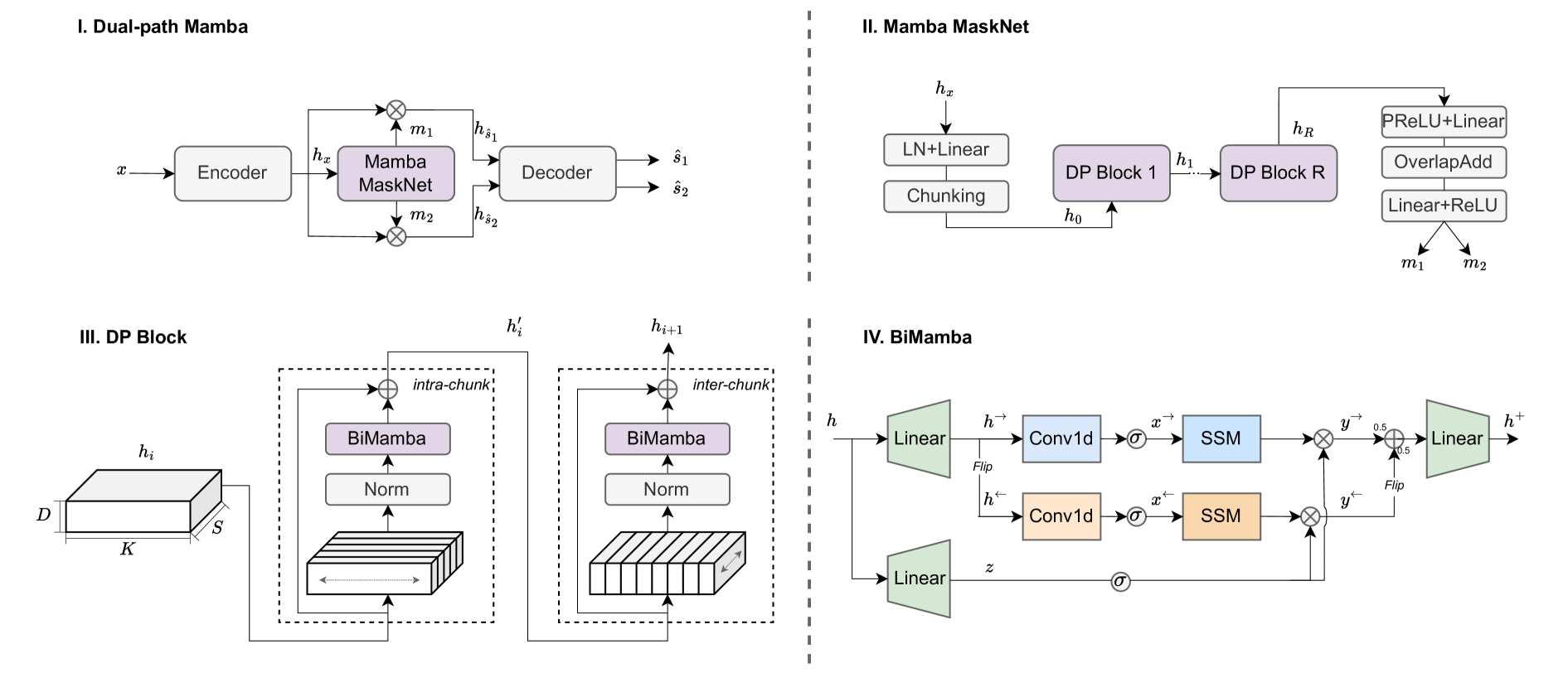
0
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
Read more5/2/2024
🤿
0
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
Read more4/26/2024