Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
2404.14966
0
0
📈
Abstract
Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss. In contrast, the newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity. However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks. In this work, we present Mamba3D, a state space model tailored for point cloud learning to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential. Specifically, we propose a simple yet effective Local Norm Pooling (LNP) block to extract local geometric features. Additionally, to obtain better global features, we introduce a bidirectional SSM (bi-SSM) with both a token forward SSM and a novel backward SSM that operates on the feature channel. Extensive experimental results show that Mamba3D surpasses Transformer-based counterparts and concurrent works in multiple tasks, with or without pre-training. Notably, Mamba3D achieves multiple SoTA, including an overall accuracy of 92.6% (train from scratch) on the ScanObjectNN and 95.1% (with single-modal pre-training) on the ModelNet40 classification task, with only linear complexity.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss.
- The newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity.
- However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks.
- Mamba3D, a state space model tailored for point cloud learning, is presented to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential.
Plain English Explanation
The paper discusses a new model called Mamba3D that is designed to analyze and process point cloud data more effectively than existing Transformer-based models. Point clouds are 3D representations of objects or environments, made up of many individual data points.
Transformer-based models, which are widely used for this task, suffer from a major limitation: they have a quadratic complexity, meaning their performance degrades rapidly as the size of the point cloud increases. This leads to a loss of resolution and important information about the 3D structure.
In contrast, the Mamba model, which is based on state space models (SSM), has only linear complexity. This means it can handle larger point clouds without the same performance issues. However, the basic Mamba model still doesn't deliver satisfactory results on point cloud tasks.
To address this, the researchers developed Mamba3D, a more specialized version of the Mamba model. Mamba3D includes two key innovations:
- A Local Norm Pooling (LNP) block to extract more detailed local geometric features from the point cloud data.
- A bidirectional SSM that uses both forward and backward processing to obtain better global features.
These modifications to the basic Mamba model allow Mamba3D to outperform Transformer-based approaches and other concurrent works on a variety of point cloud tasks. It achieves state-of-the-art results with high efficiency and the potential for scalability to larger datasets.
Technical Explanation
The paper presents the Mamba3D model, which is a state space model (SSM) designed specifically for point cloud learning tasks. SSMs have a linear complexity, in contrast to the quadratic complexity of Transformer-based models, which leads to compromised point cloud resolution and information loss.
The key innovations in Mamba3D are:
-
Local Norm Pooling (LNP) block: This module is introduced to enhance local feature extraction from the point cloud data. The LNP block computes the local geometric features by normalizing the point features within a local neighborhood.
-
Bidirectional SSM (bi-SSM): To obtain better global features, the researchers propose a bi-SSM architecture. This includes both a forward SSM, which processes the point features in a sequential manner, and a novel backward SSM, which operates on the feature channel dimension.
The experimental results show that Mamba3D outperforms Transformer-based models and other concurrent works on multiple point cloud tasks, with or without pre-training. Notably, Mamba3D achieves state-of-the-art performance on the ScanObjectNN (92.6% accuracy) and ModelNet40 (95.1% accuracy) classification benchmarks, while maintaining linear complexity.
Critical Analysis
The paper presents a compelling solution to the limitations of Transformer-based models for point cloud analysis. By leveraging state space models and introducing innovative architectural components like the LNP block and bi-SSM, the researchers have demonstrated significant performance improvements.
However, the paper does not extensively discuss potential limitations or areas for further research. For example, it would be interesting to understand how Mamba3D scales to even larger and more complex point cloud datasets, or how it performs on more diverse point cloud tasks beyond classification.
Additionally, the paper could benefit from a more in-depth discussion of the theoretical underpinnings of the state space model approach and how it compares to other alternatives, such as graph neural networks or specialized point cloud architectures.
Overall, the Mamba3D model presents an exciting advance in point cloud learning, but there may be opportunities to further explore its capabilities and limitations through additional research.
Conclusion
The paper introduces the Mamba3D model, a state space model designed specifically for point cloud learning tasks. Mamba3D addresses the limitations of existing Transformer-based models, which suffer from quadratic complexity and compromised point cloud resolution.
By incorporating a Local Norm Pooling (LNP) block and a bidirectional state space model (bi-SSM), Mamba3D achieves superior performance, high efficiency, and scalability potential on multiple point cloud benchmarks. The model's linear complexity allows it to handle larger point clouds without the same degradation in performance.
The Mamba3D approach represents a significant advancement in the field of point cloud analysis and processing, with potential applications in domains like 3D reconstruction, autonomous navigation, and virtual/augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
PointMamba: A Simple State Space Model for Point Cloud Analysis
Dingkang Liang, Xin Zhou, Xinyu Wang, Xingkui Zhu, Wei Xu, Zhikang Zou, Xiaoqing Ye, Xiang Bai
0
0
Transformers have become one of the foundational architectures in point cloud analysis tasks due to their excellent global modeling ability. However, the attention mechanism has quadratic complexity and is difficult to extend to long sequence modeling due to limited computational resources and so on. Recently, state space models (SSM), a new family of deep sequence models, have presented great potential for sequence modeling in NLP tasks. In this paper, taking inspiration from the success of SSM in NLP, we propose PointMamba, a framework with global modeling and linear complexity. Specifically, by taking embedded point patches as input, we proposed a reordering strategy to enhance SSM's global modeling ability by providing a more logical geometric scanning order. The reordered point tokens are then sent to a series of Mamba blocks to causally capture the point cloud structure. Experimental results show our proposed PointMamba outperforms the transformer-based counterparts on different point cloud analysis datasets, while significantly saving about 44.3% parameters and 25% FLOPs, demonstrating the potential option for constructing foundational 3D vision models. We hope our PointMamba can provide a new perspective for point cloud analysis. The code is available at https://github.com/LMD0311/PointMamba.
4/3/2024
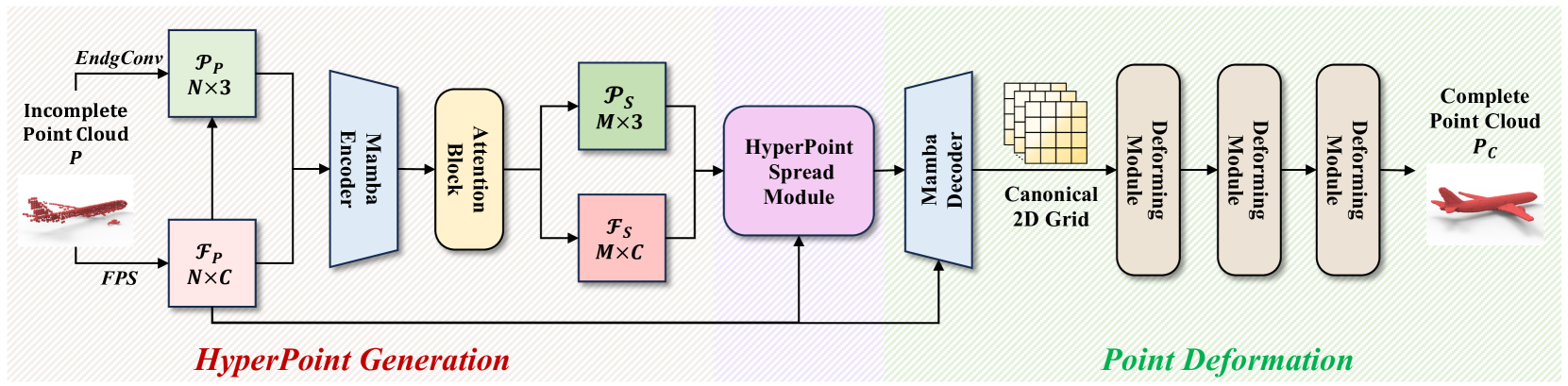
3DMambaComplete: Exploring Structured State Space Model for Point Cloud Completion
Yixuan Li, Weidong Yang, Ben Fei
0
0
Point cloud completion aims to generate a complete and high-fidelity point cloud from an initially incomplete and low-quality input. A prevalent strategy involves leveraging Transformer-based models to encode global features and facilitate the reconstruction process. However, the adoption of pooling operations to obtain global feature representations often results in the loss of local details within the point cloud. Moreover, the attention mechanism inherent in Transformers introduces additional computational complexity, rendering it challenging to handle long sequences effectively. To address these issues, we propose 3DMambaComplete, a point cloud completion network built on the novel Mamba framework. It comprises three modules: HyperPoint Generation encodes point cloud features using Mamba's selection mechanism and predicts a set of Hyperpoints. A specific offset is estimated, and the down-sampled points become HyperPoints. The HyperPoint Spread module disperses these HyperPoints across different spatial locations to avoid concentration. Finally, a deformation method transforms the 2D mesh representation of HyperPoints into a fine-grained 3D structure for point cloud reconstruction. Extensive experiments conducted on various established benchmarks demonstrate that 3DMambaComplete surpasses state-of-the-art point cloud completion methods, as confirmed by qualitative and quantitative analyses.
4/11/2024
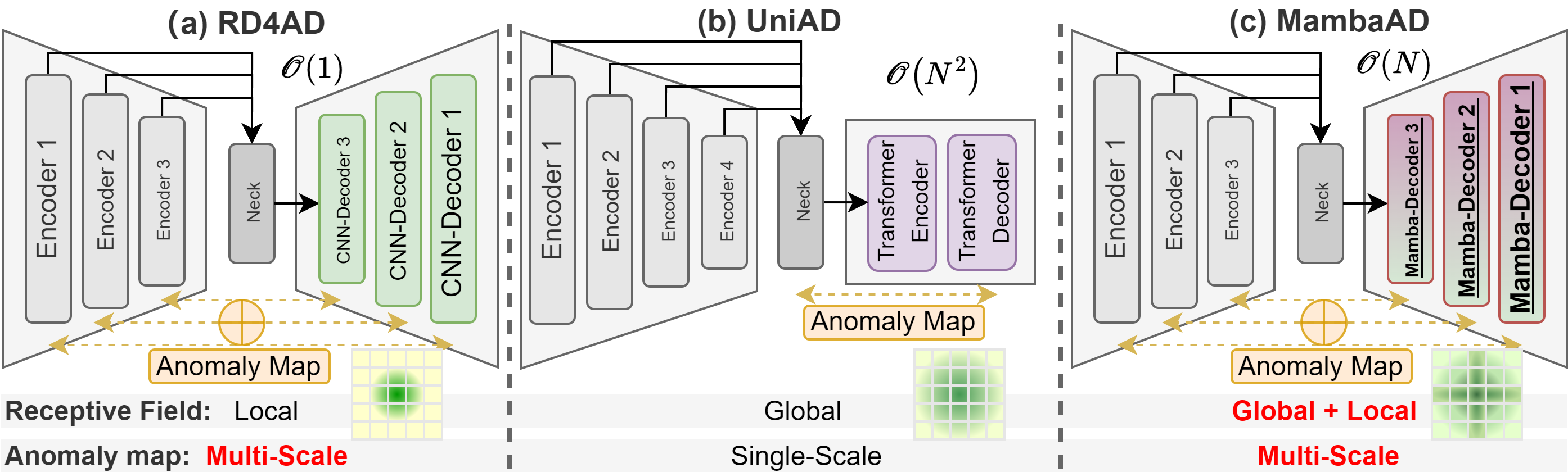
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
Haoyang He, Yuhu Bai, Jiangning Zhang, Qingdong He, Hongxu Chen, Zhenye Gan, Chengjie Wang, Xiangtai Li, Guanzhong Tian, Lei Xie
0
0
Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness.
4/16/2024
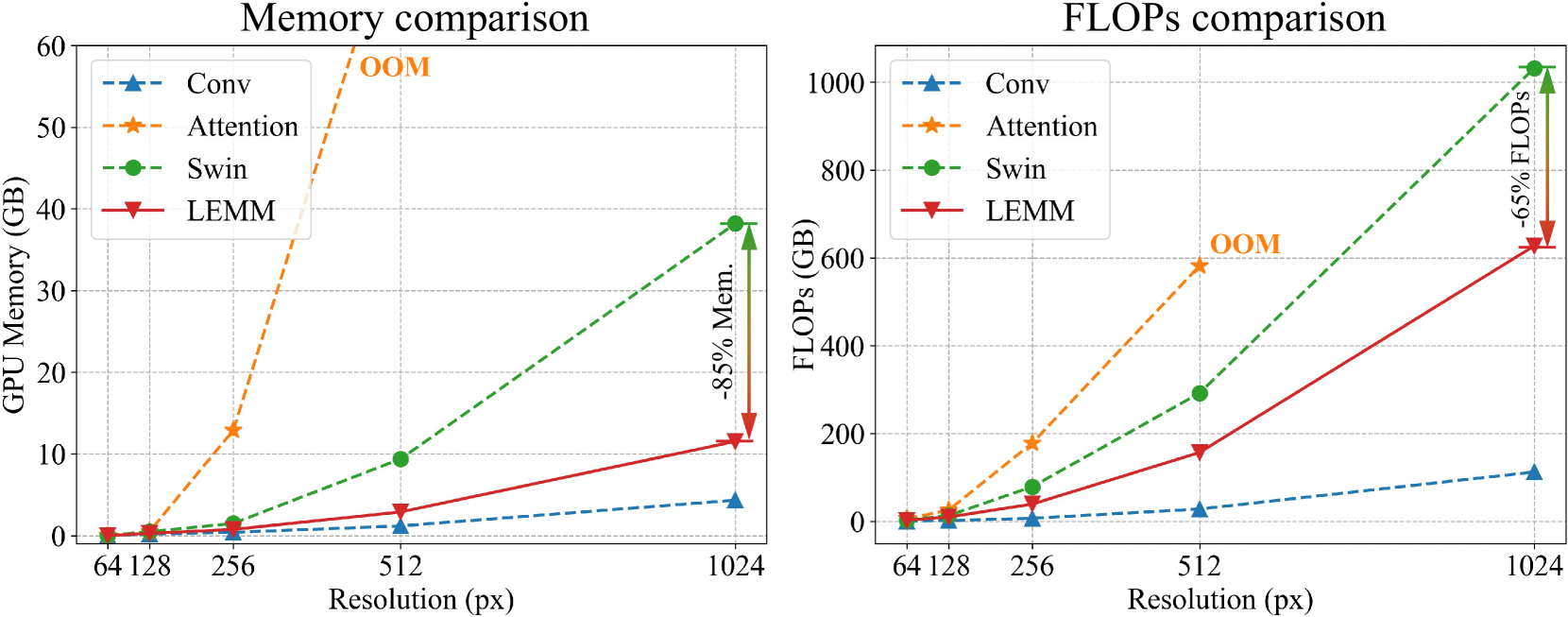
A Novel State Space Model with Local Enhancement and State Sharing for Image Fusion
Zihan Cao, Xiao Wu, Liang-Jian Deng, Yu Zhong
0
0
In image fusion tasks, images from different sources possess distinct characteristics. This has driven the development of numerous methods to explore better ways of fusing them while preserving their respective characteristics. Mamba, as a state space model, has emerged in the field of natural language processing. Recently, many studies have attempted to extend Mamba to vision tasks. However, due to the nature of images different from casual language sequences, the limited state capacity of Mamba weakens its ability to model image information. Additionally, the sequence modeling ability of Mamba is only capable of spatial information and cannot effectively capture the rich spectral information in images. Motivated by these challenges, we customize and improve the vision Mamba network designed for the image fusion task. Specifically, we propose the local-enhanced vision Mamba block, dubbed as LEVM. The LEVM block can improve local information perception of the network and simultaneously learn local and global spatial information. Furthermore, we propose the state sharing technique to enhance spatial details and integrate spatial and spectral information. Finally, the overall network is a multi-scale structure based on vision Mamba, called LE-Mamba. Extensive experiments show the proposed methods achieve state-of-the-art results on multispectral pansharpening and multispectral and hyperspectral image fusion datasets, and demonstrate the effectiveness of the proposed approach. Code will be made available.
4/16/2024