PointMamba: A Simple State Space Model for Point Cloud Analysis
2402.10739
0
0
📈
Abstract
Transformers have become one of the foundational architectures in point cloud analysis tasks due to their excellent global modeling ability. However, the attention mechanism has quadratic complexity and is difficult to extend to long sequence modeling due to limited computational resources and so on. Recently, state space models (SSM), a new family of deep sequence models, have presented great potential for sequence modeling in NLP tasks. In this paper, taking inspiration from the success of SSM in NLP, we propose PointMamba, a framework with global modeling and linear complexity. Specifically, by taking embedded point patches as input, we proposed a reordering strategy to enhance SSM's global modeling ability by providing a more logical geometric scanning order. The reordered point tokens are then sent to a series of Mamba blocks to causally capture the point cloud structure. Experimental results show our proposed PointMamba outperforms the transformer-based counterparts on different point cloud analysis datasets, while significantly saving about 44.3% parameters and 25% FLOPs, demonstrating the potential option for constructing foundational 3D vision models. We hope our PointMamba can provide a new perspective for point cloud analysis. The code is available at https://github.com/LMD0311/PointMamba.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Transformers have become a popular architecture for analyzing point cloud data due to their strong ability to model global patterns.
- However, the attention mechanism in transformers has limitations, such as high computational complexity and difficulty in handling long sequences.
- The paper proposes a new framework called PointMamba that aims to address these limitations by leveraging state space models (SSMs), a class of deep sequence models that have shown promise in natural language processing tasks.
Plain English Explanation
Point clouds are digital representations of 3D objects or environments, often used in applications like self-driving cars, robotics, and virtual reality. Transformers, a type of deep learning model, have become a go-to choice for analyzing point cloud data because they can capture the overall structure and patterns within the data.
However, transformers have a key drawback - their attention mechanism, which is crucial for identifying important relationships in the data, has a quadratic complexity. This means that as the size of the point cloud increases, the computational power required to process it grows exponentially, making it difficult to use transformers for large-scale point cloud analysis.
The researchers behind this paper were inspired by the success of state space models (SSMs) in natural language processing. SSMs are a family of deep learning models that can efficiently handle sequential data, like text, by modeling the underlying state of the system. The researchers wondered if a similar approach could be applied to point cloud data, potentially overcoming the limitations of transformers.
The result is PointMamba, a new framework that combines the global modeling capabilities of transformers with the linear complexity of SSMs. PointMamba takes small, overlapping patches of the point cloud as input, reorders them in a more logical, geometric way, and then processes them through a series of specialized "Mamba" blocks to capture the overall structure of the point cloud.
Technical Explanation
The key technical contributions of PointMamba are:
-
Reordering Strategy: The researchers developed a reordering strategy to enhance the global modeling ability of SSMs. By rearranging the input point patches in a more logical, geometric order, PointMamba can better capture the overall structure of the point cloud.
-
Mamba Blocks: PointMamba processes the reordered point patches through a series of specialized "Mamba" blocks, which use the state space modeling approach to efficiently capture the causal relationships and structure within the point cloud.
The researchers evaluated PointMamba on several standard point cloud analysis tasks, such as object classification and part segmentation. Their results show that PointMamba outperforms transformer-based models while using significantly fewer parameters and computational resources (44.3% fewer parameters and 25% fewer FLOPs).
Critical Analysis
The paper presents a well-designed and thorough evaluation of PointMamba, demonstrating its effectiveness on a range of point cloud analysis tasks. However, the researchers do acknowledge some limitations and areas for further research:
-
Scalability: While PointMamba is more computationally efficient than transformers, the researchers note that further improvements may be needed to handle truly large-scale point clouds, such as those encountered in real-world applications.
-
Interpretability: As with many deep learning models, the internal workings of PointMamba may be difficult to interpret, which could be a concern for applications that require explainable AI.
-
Generalization: The researchers primarily evaluated PointMamba on standard benchmark datasets. More research may be needed to understand how well the model generalizes to more diverse and challenging real-world point cloud data.
Overall, the PointMamba framework presents a promising new approach to point cloud analysis, offering a more efficient and scalable alternative to transformer-based models. Further refinement and exploration of the model's capabilities could lead to significant advancements in 3D vision and perception tasks.
Conclusion
The PointMamba framework proposed in this paper offers a novel solution to the limitations of transformer-based models for point cloud analysis. By leveraging state space models and a reordering strategy, PointMamba can capture the global structure of point clouds with significantly lower computational requirements than transformers.
The strong performance of PointMamba on standard benchmarks suggests that it could become a foundational architecture for 3D vision and perception tasks, potentially enabling more efficient and scalable solutions in applications like self-driving cars, robotics, and virtual reality. As the field of point cloud analysis continues to evolve, innovative approaches like PointMamba may pave the way for more advanced and practical 3D understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
Xu Han, Yuan Tang, Zhaoxuan Wang, Xianzhi Li
0
0
Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss. In contrast, the newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity. However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks. In this work, we present Mamba3D, a state space model tailored for point cloud learning to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential. Specifically, we propose a simple yet effective Local Norm Pooling (LNP) block to extract local geometric features. Additionally, to obtain better global features, we introduce a bidirectional SSM (bi-SSM) with both a token forward SSM and a novel backward SSM that operates on the feature channel. Extensive experimental results show that Mamba3D surpasses Transformer-based counterparts and concurrent works in multiple tasks, with or without pre-training. Notably, Mamba3D achieves multiple SoTA, including an overall accuracy of 92.6% (train from scratch) on the ScanObjectNN and 95.1% (with single-modal pre-training) on the ModelNet40 classification task, with only linear complexity.
4/24/2024
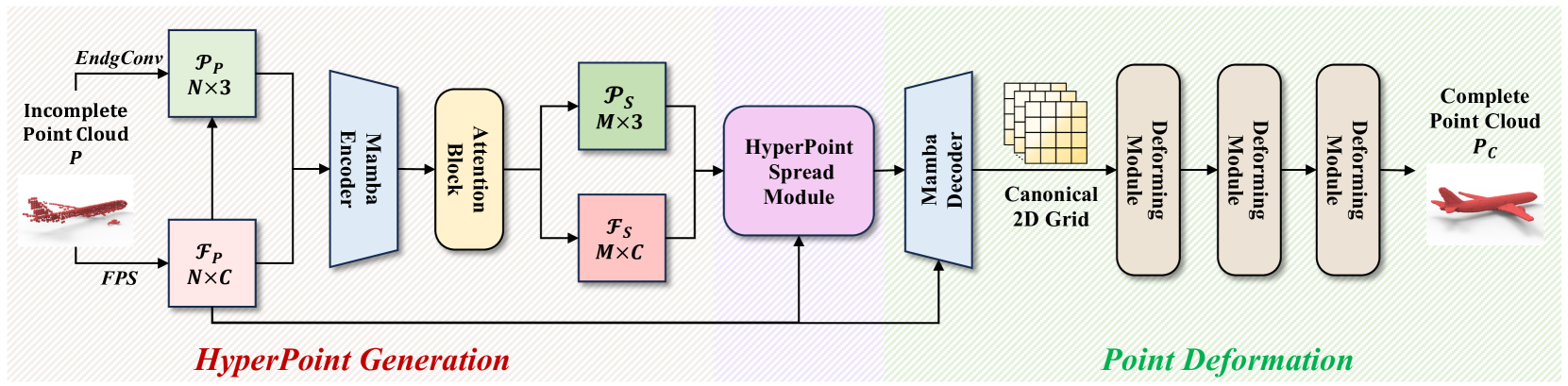
3DMambaComplete: Exploring Structured State Space Model for Point Cloud Completion
Yixuan Li, Weidong Yang, Ben Fei
0
0
Point cloud completion aims to generate a complete and high-fidelity point cloud from an initially incomplete and low-quality input. A prevalent strategy involves leveraging Transformer-based models to encode global features and facilitate the reconstruction process. However, the adoption of pooling operations to obtain global feature representations often results in the loss of local details within the point cloud. Moreover, the attention mechanism inherent in Transformers introduces additional computational complexity, rendering it challenging to handle long sequences effectively. To address these issues, we propose 3DMambaComplete, a point cloud completion network built on the novel Mamba framework. It comprises three modules: HyperPoint Generation encodes point cloud features using Mamba's selection mechanism and predicts a set of Hyperpoints. A specific offset is estimated, and the down-sampled points become HyperPoints. The HyperPoint Spread module disperses these HyperPoints across different spatial locations to avoid concentration. Finally, a deformation method transforms the 2D mesh representation of HyperPoints into a fine-grained 3D structure for point cloud reconstruction. Extensive experiments conducted on various established benchmarks demonstrate that 3DMambaComplete surpasses state-of-the-art point cloud completion methods, as confirmed by qualitative and quantitative analyses.
4/11/2024
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
0
0
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
4/29/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024